 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehind the Mask: Demographic bias in name detection for PII masking
May 09, 2022
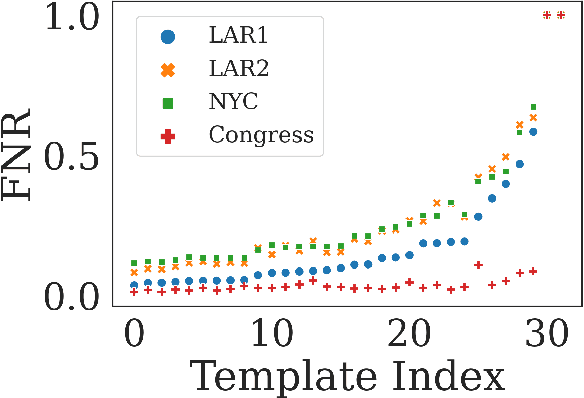
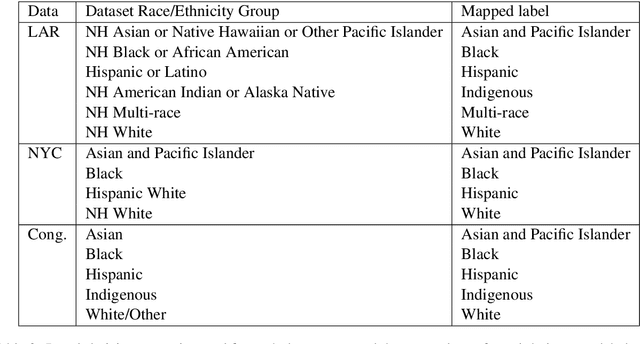
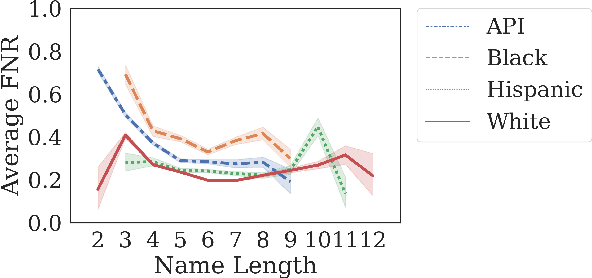
Many datasets contain personally identifiable information, or PII, which poses privacy risks to individuals. PII masking is commonly used to redact personal information such as names, addresses, and phone numbers from text data. Most modern PII masking pipelines involve machine learning algorithms. However, these systems may vary in performance, such that individuals from particular demographic groups bear a higher risk for having their personal information exposed. In this paper, we evaluate the performance of three off-the-shelf PII masking systems on name detection and redaction. We generate data using names and templates from the customer service domain. We find that an open-source RoBERTa-based system shows fewer disparities than the commercial models we test. However, all systems demonstrate significant differences in error rate based on demographics. In particular, the highest error rates occurred for names associated with Black and Asian/Pacific Islander individuals.
AI and the Everything in the Whole Wide World Benchmark
Nov 26, 2021
There is a tendency across different subfields in AI to valorize a small collection of influential benchmarks. These benchmarks operate as stand-ins for a range of anointed common problems that are frequently framed as foundational milestones on the path towards flexible and generalizable AI systems. State-of-the-art performance on these benchmarks is widely understood as indicative of progress towards these long-term goals. In this position paper, we explore the limits of such benchmarks in order to reveal the construct validity issues in their framing as the functionally "general" broad measures of progress they are set up to be.
A multilabel approach to morphosyntactic probing
Apr 17, 2021
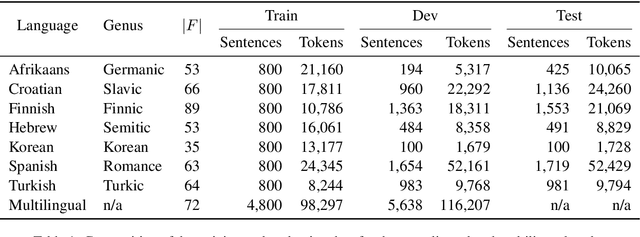
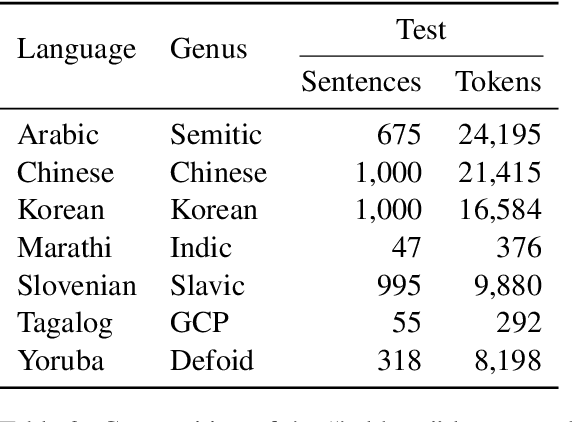
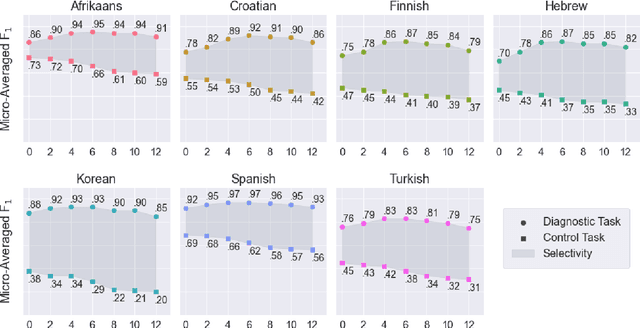
We introduce a multilabel probing task to assess the morphosyntactic representations of word embeddings from multilingual language models. We demonstrate this task with multilingual BERT (Devlin et al., 2018), training probes for seven typologically diverse languages of varying morphological complexity: Afrikaans, Croatian, Finnish, Hebrew, Korean, Spanish, and Turkish. Through this simple but robust paradigm, we show that multilingual BERT renders many morphosyntactic features easily and simultaneously extractable (e.g., gender, grammatical case, pronominal type). We further evaluate the probes on six "held-out" languages in a zero-shot transfer setting: Arabic, Chinese, Marathi, Slovenian, Tagalog, and Yoruba. This style of probing has the added benefit of revealing the linguistic properties that language models recognize as being shared across languages. For instance, the probes performed well on recognizing nouns in the held-out languages, suggesting that multilingual BERT has a conception of noun-hood that transcends individual languages; yet, the same was not true of adjectives.
Data and its contents: A survey of dataset development and use in machine learning research
Dec 09, 2020Datasets have played a foundational role in the advancement of machine learning research. They form the basis for the models we design and deploy, as well as our primary medium for benchmarking and evaluation. Furthermore, the ways in which we collect, construct and share these datasets inform the kinds of problems the field pursues and the methods explored in algorithm development. However, recent work from a breadth of perspectives has revealed the limitations of predominant practices in dataset collection and use. In this paper, we survey the many concerns raised about the way we collect and use data in machine learning and advocate that a more cautious and thorough understanding of data is necessary to address several of the practical and ethical issues of the field.