 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehind the Mask: Demographic bias in name detection for PII masking
Paper and Code

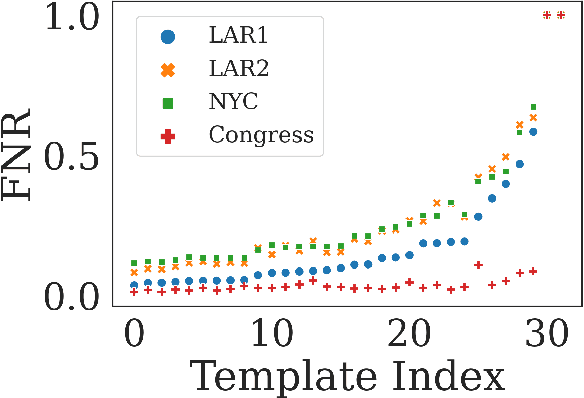
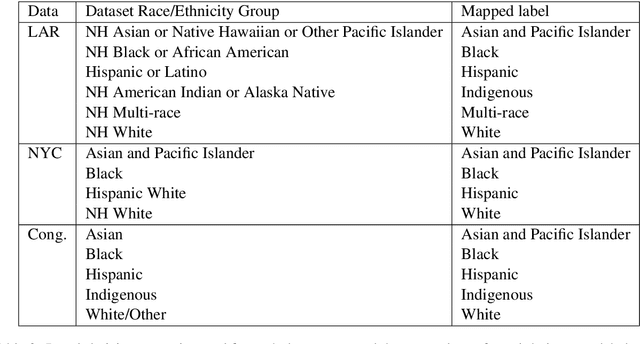
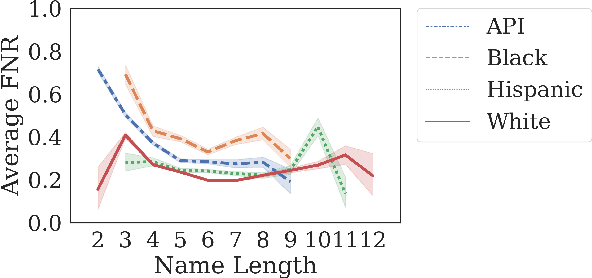
Many datasets contain personally identifiable information, or PII, which poses privacy risks to individuals. PII masking is commonly used to redact personal information such as names, addresses, and phone numbers from text data. Most modern PII masking pipelines involve machine learning algorithms. However, these systems may vary in performance, such that individuals from particular demographic groups bear a higher risk for having their personal information exposed. In this paper, we evaluate the performance of three off-the-shelf PII masking systems on name detection and redaction. We generate data using names and templates from the customer service domain. We find that an open-source RoBERTa-based system shows fewer disparities than the commercial models we test. However, all systems demonstrate significant differences in error rate based on demographics. In particular, the highest error rates occurred for names associated with Black and Asian/Pacific Islander individuals.