 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-JOIE: Joint Representation Learning of Biological Knowledge Bases
Mar 07, 2021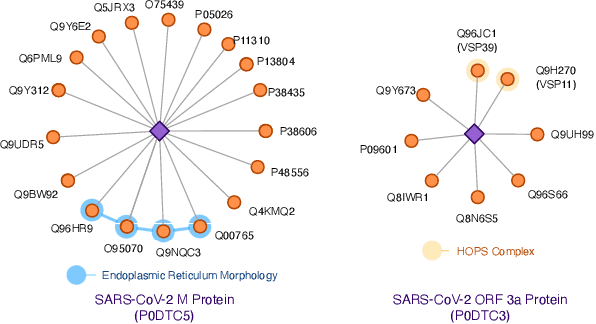
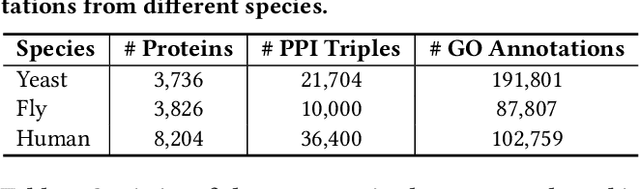
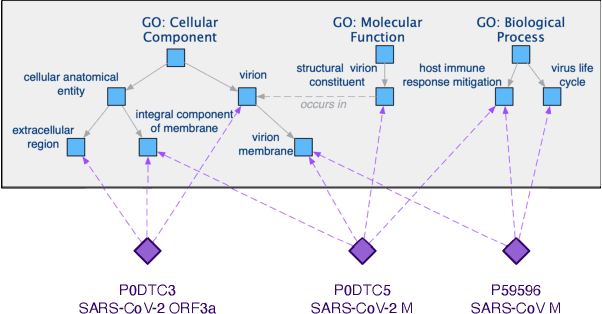
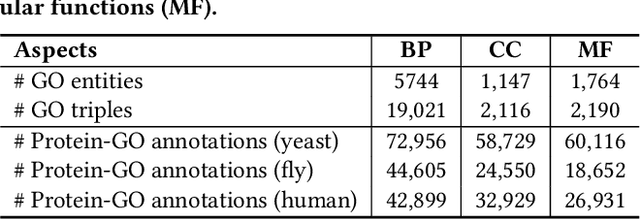
The widespread of Coronavirus has led to a worldwide pandemic with a high mortality rate. Currently, the knowledge accumulated from different studies about this virus is very limited. Leveraging a wide-range of biological knowledge, such as gene ontology and protein-protein interaction (PPI) networks from other closely related species presents a vital approach to infer the molecular impact of a new species. In this paper, we propose the transferred multi-relational embedding model Bio-JOIE to capture the knowledge of gene ontology and PPI networks, which demonstrates superb capability in modeling the SARS-CoV-2-human protein interactions. Bio-JOIE jointly trains two model components. The knowledge model encodes the relational facts from the protein and GO domains into separated embedding spaces, using a hierarchy-aware encoding technique employed for the GO terms. On top of that, the transfer model learns a non-linear transformation to transfer the knowledge of PPIs and gene ontology annotations across their embedding spaces. By leveraging only structured knowledge, Bio-JOIE significantly outperforms existing state-of-the-art methods in PPI type prediction on multiple species. Furthermore, we also demonstrate the potential of leveraging the learned representations on clustering proteins with enzymatic function into enzyme commission families. Finally, we show that Bio-JOIE can accurately identify PPIs between the SARS-CoV-2 proteins and human proteins, providing valuable insights for advancing research on this new disease.
* ACM BCB 2020, Best Student Paper
Multilingual Knowledge Graph Completion via Ensemble Knowledge Transfer
Oct 08, 2020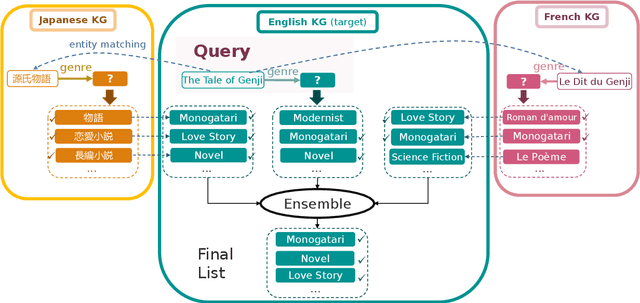
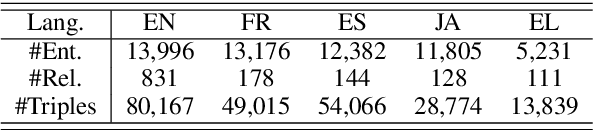
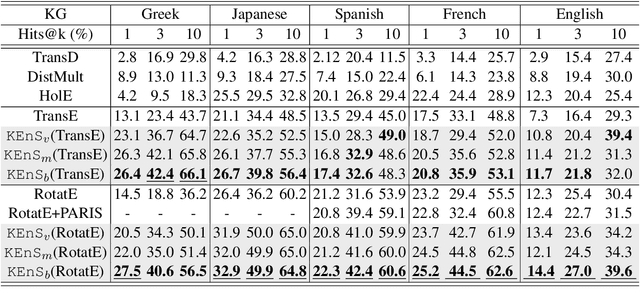
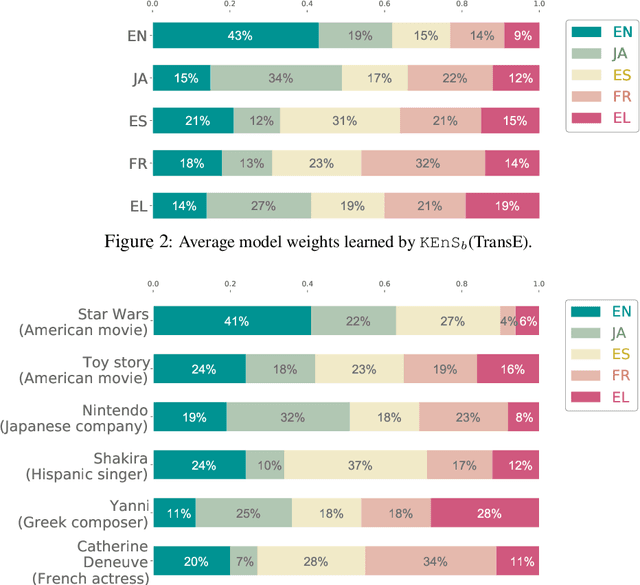
Predicting missing facts in a knowledge graph (KG) is a crucial task in knowledge base construction and reasoning, and it has been the subject of much research in recent works using KG embeddings. While existing KG embedding approaches mainly learn and predict facts within a single KG, a more plausible solution would benefit from the knowledge in multiple language-specific KGs, considering that different KGs have their own strengths and limitations on data quality and coverage. This is quite challenging, since the transfer of knowledge among multiple independently maintained KGs is often hindered by the insufficiency of alignment information and the inconsistency of described facts. In this paper, we propose KEnS, a novel framework for embedding learning and ensemble knowledge transfer across a number of language-specific KGs. KEnS embeds all KGs in a shared embedding space, where the association of entities is captured based on self-learning. Then, KEnS performs ensemble inference to combine prediction results from embeddings of multiple language-specific KGs, for which multiple ensemble techniques are investigated. Experiments on five real-world language-specific KGs show that KEnS consistently improves state-of-the-art methods on KG completion, via effectively identifying and leveraging complementary knowledge.
BigData Applications from Graph Analytics to Machine Learning by Aggregates in Recursion
Sep 18, 2019In the past, the semantic issues raised by the non-monotonic nature of aggregates often prevented their use in the recursive statements of logic programs and deductive databases. However, the recently introduced notion of Pre-mappability (PreM) has shown that, in key applications of interest, aggregates can be used in recursion to optimize the perfect-model semantics of aggregate-stratified programs. Therefore we can preserve the declarative formal semantics of such programs while achieving a highly efficient operational semantics that is conducive to scalable implementations on parallel and distributed platforms. In this paper, we show that with PreM, a wide spectrum of classical algorithms of practical interest, ranging from graph analytics and dynamic programming based optimization problems to data mining and machine learning applications can be concisely expressed in declarative languages by using aggregates in recursion. Our examples are also used to show that PreM can be checked using simple techniques and templatized verification strategies. A wide range of advanced BigData applications can now be expressed declaratively in logic-based languages, including Datalog, Prolog, and even SQL, while enabling their execution with superior performance and scalability.
* In Proceedings ICLP 2019, arXiv:1909.07646. Paper presented at the 35th International Conference on Logic Programming (ICLP 2019), Las Cruces, New Mexico, USA, 20-25 September 2019, 7 pages (short paper - applications track)
Quantification and Analysis of Scientific Language Variation Across Research Fields
Dec 04, 2018



Quantifying differences in terminologies from various academic domains has been a longstanding problem yet to be solved. We propose a computational approach for analyzing linguistic variation among scientific research fields by capturing the semantic change of terms based on a neural language model. The model is trained on a large collection of literature in five computer science research fields, for which we obtain field-specific vector representations for key terms, and global vector representations for other words. Several quantitative approaches are introduced to identify the terms whose semantics have drastically changed, or remain unchanged across different research fields. We also propose a metric to quantify the overall linguistic variation of research fields. After quantitative evaluation on human annotated data and qualitative comparison with other methods, we show that our model can improve cross-disciplinary data collaboration by identifying terms that potentially induce confusion during interdisciplinary studies.
Embedding Uncertain Knowledge Graphs
Nov 26, 2018

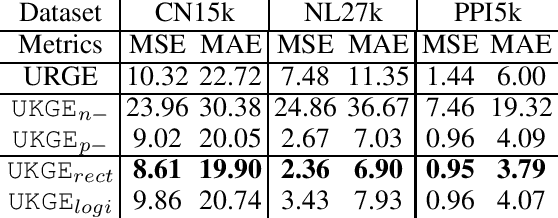
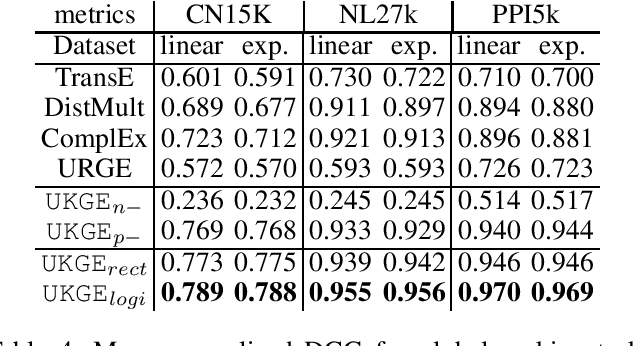
Embedding models for deterministic Knowledge Graphs (KG) have been extensively studied, with the purpose of capturing latent semantic relations between entities and incorporating the structured knowledge into machine learning. However, there are many KGs that model uncertain knowledge, which typically model the inherent uncertainty of relations facts with a confidence score, and embedding such uncertain knowledge represents an unresolved challenge. The capturing of uncertain knowledge will benefit many knowledge-driven applications such as question answering and semantic search by providing more natural characterization of the knowledge. In this paper, we propose a novel uncertain KG embedding model UKGE, which aims to preserve both structural and uncertainty information of relation facts in the embedding space. Unlike previous models that characterize relation facts with binary classification techniques, UKGE learns embeddings according to the confidence scores of uncertain relation facts. To further enhance the precision of UKGE, we also introduce probabilistic soft logic to infer confidence scores for unseen relation facts during training. We propose and evaluate two variants of UKGE based on different learning objectives. Experiments are conducted on three real-world uncertain KGs via three tasks, i.e. confidence prediction, relation fact ranking, and relation fact classification. UKGE shows effectiveness in capturing uncertain knowledge by achieving promising results on these tasks, and consistently outperforms baselines on these tasks.
On2Vec: Embedding-based Relation Prediction for Ontology Population
Sep 07, 2018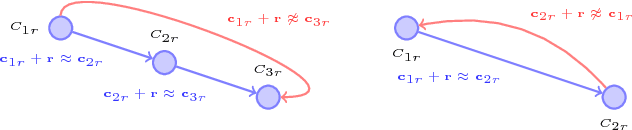

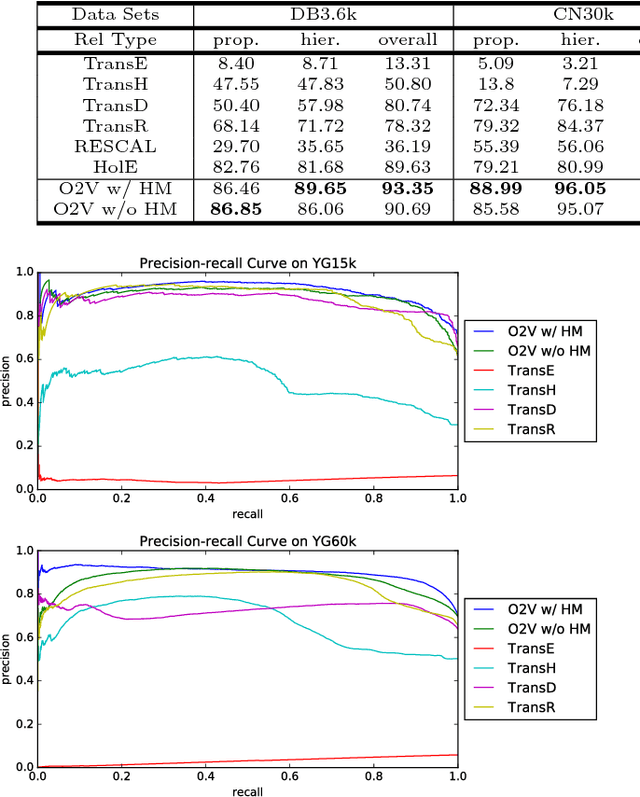
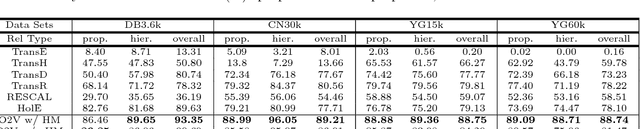
Populating ontology graphs represents a long-standing problem for the Semantic Web community. Recent advances in translation-based graph embedding methods for populating instance-level knowledge graphs lead to promising new approaching for the ontology population problem. However, unlike instance-level graphs, the majority of relation facts in ontology graphs come with comprehensive semantic relations, which often include the properties of transitivity and symmetry, as well as hierarchical relations. These comprehensive relations are often too complex for existing graph embedding methods, and direct application of such methods is not feasible. Hence, we propose On2Vec, a novel translation-based graph embedding method for ontology population. On2Vec integrates two model components that effectively characterize comprehensive relation facts in ontology graphs. The first is the Component-specific Model that encodes concepts and relations into low-dimensional embedding spaces without a loss of relational properties; the second is the Hierarchy Model that performs focused learning of hierarchical relation facts. Experiments on several well-known ontology graphs demonstrate the promising capabilities of On2Vec in predicting and verifying new relation facts. These promising results also make possible significant improvements in related methods.
Learning to Represent Bilingual Dictionaries
Aug 31, 2018
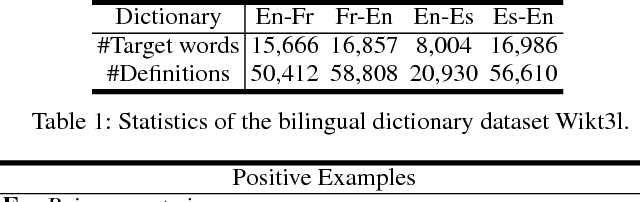


Bilingual word embeddings have been widely used to capture the similarity of lexical semantics in different human languages. However, many applications, such as cross-lingual semantic search and question answering, can be largely benefited from the cross-lingual correspondence between sentences and lexicons. To bridge this gap, we propose a neural embedding model that leverages bilingual dictionaries. The proposed model is trained to map the literal word definitions to the cross-lingual target words, for which we explore with different sentence encoding techniques. To enhance the learning process on limited resources, our model adopts several critical learning strategies, including multi-task learning on different bridges of languages, and joint learning of the dictionary model with a bilingual word embedding model. Experimental evaluation focuses on two applications. The results of the cross-lingual reverse dictionary retrieval task show our model's promising ability of comprehending bilingual concepts based on descriptions, and highlight the effectiveness of proposed learning strategies in improving performance. Meanwhile, our model effectively addresses the bilingual paraphrase identification problem and significantly outperforms previous approaches.
Neural Article Pair Modeling for Wikipedia Sub-article Matching
Aug 04, 2018


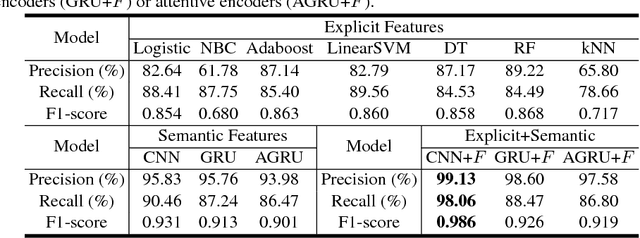
Nowadays, editors tend to separate different subtopics of a long Wiki-pedia article into multiple sub-articles. This separation seeks to improve human readability. However, it also has a deleterious effect on many Wikipedia-based tasks that rely on the article-as-concept assumption, which requires each entity (or concept) to be described solely by one article. This underlying assumption significantly simplifies knowledge representation and extraction, and it is vital to many existing technologies such as automated knowledge base construction, cross-lingual knowledge alignment, semantic search and data lineage of Wikipedia entities. In this paper we provide an approach to match the scattered sub-articles back to their corresponding main-articles, with the intent of facilitating automated Wikipedia curation and processing. The proposed model adopts a hierarchical learning structure that combines multiple variants of neural document pair encoders with a comprehensive set of explicit features. A large crowdsourced dataset is created to support the evaluation and feature extraction for the task. Based on the large dataset, the proposed model achieves promising results of cross-validation and significantly outperforms previous approaches. Large-scale serving on the entire English Wikipedia also proves the practicability and scalability of the proposed model by effectively extracting a vast collection of newly paired main and sub-articles.
Co-training Embeddings of Knowledge Graphs and Entity Descriptions for Cross-lingual Entity Alignment
Jun 18, 2018

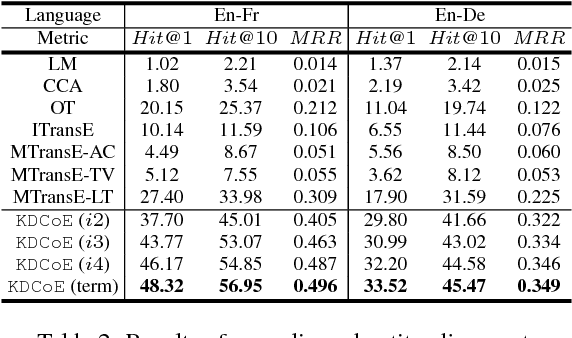
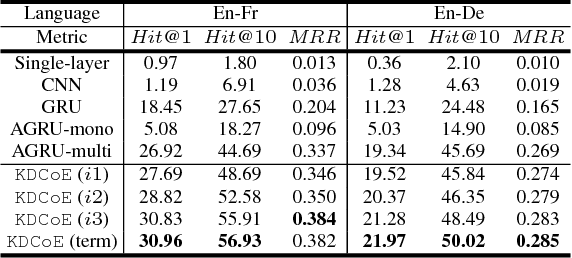
Multilingual knowledge graph (KG) embeddings provide latent semantic representations of entities and structured knowledge with cross-lingual inferences, which benefit various knowledge-driven cross-lingual NLP tasks. However, precisely learning such cross-lingual inferences is usually hindered by the low coverage of entity alignment in many KGs. Since many multilingual KGs also provide literal descriptions of entities, in this paper, we introduce an embedding-based approach which leverages a weakly aligned multilingual KG for semi-supervised cross-lingual learning using entity descriptions. Our approach performs co-training of two embedding models, i.e. a multilingual KG embedding model and a multilingual literal description embedding model. The models are trained on a large Wikipedia-based trilingual dataset where most entity alignment is unknown to training. Experimental results show that the performance of the proposed approach on the entity alignment task improves at each iteration of co-training, and eventually reaches a stage at which it significantly surpasses previous approaches. We also show that our approach has promising abilities for zero-shot entity alignment, and cross-lingual KG completion.
How Much Are You Willing to Share? A "Poker-Styled" Selective Privacy Preserving Framework for Recommender Systems
Jun 04, 2018

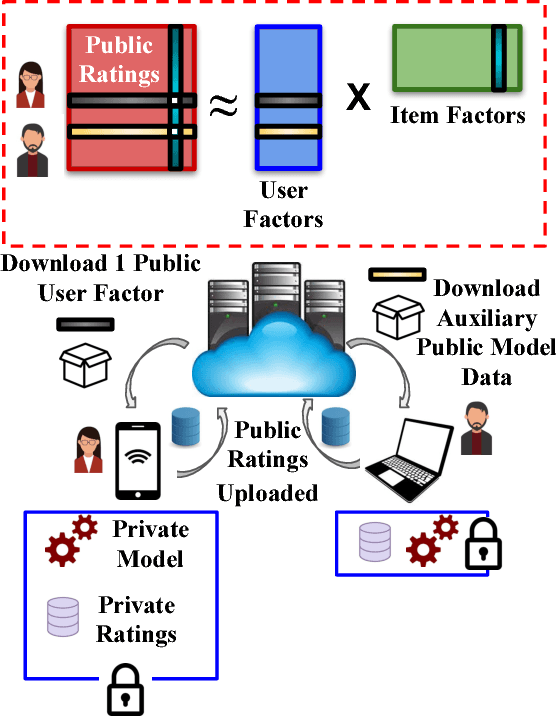
Most industrial recommender systems rely on the popular collaborative filtering (CF) technique for providing personalized recommendations to its users. However, the very nature of CF is adversarial to the idea of user privacy, because users need to share their preferences with others in order to be grouped with like-minded people and receive accurate recommendations. While previous privacy preserving approaches have been successful inasmuch as they concealed user preference information to some extent from a centralized recommender system, they have also, nevertheless, incurred significant trade-offs in terms of privacy, scalability, and accuracy. They are also vulnerable to privacy breaches by malicious actors. In light of these observations, we propose a novel selective privacy preserving (SP2) paradigm that allows users to custom define the scope and extent of their individual privacies, by marking their personal ratings as either public (which can be shared) or private (which are never shared and stored only on the user device). Our SP2 framework works in two steps: (i) First, it builds an initial recommendation model based on the sum of all public ratings that have been shared by users and (ii) then, this public model is fine-tuned on each user's device based on the user private ratings, thus eventually learning a more accurate model. Furthermore, in this work, we introduce three different algorithms for implementing an end-to-end SP2 framework that can scale effectively from thousands to hundreds of millions of items. Our user survey shows that an overwhelming fraction of users are likely to rate much more items to improve the overall recommendations when they can control what ratings will be publicly shared with others.