 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Prior Learning via Neural Networks for Next-item Recommendation
May 10, 2022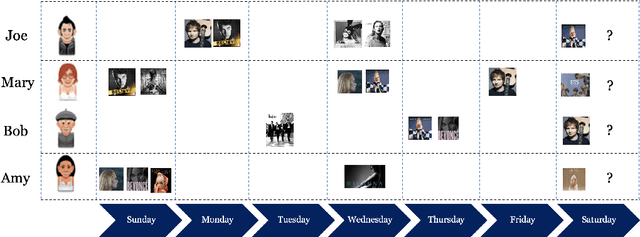
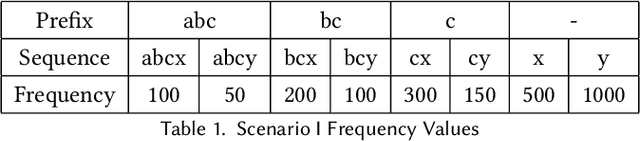

Next-item prediction is a a popular problem in the recommender systems domain. As the name suggests, the task is to recommend subsequent items that a user would be interested in given contextual information and historical interaction data. In our paper, we model a general notion of context via a sequence of item interactions. We model the next item prediction problem using the Bayesian framework and capture the probability of appearance of a sequence through the posterior mean of the Beta distribution. We train two neural networks to accurately predict the alpha & beta parameter values of the Beta distribution. Our novel approach of combining black-box style neural networks, known to be suitable for function approximation with Bayesian estimation methods have resulted in an innovative method that outperforms various state-of-the-art baselines. We demonstrate the effectiveness of our method in two real world datasets. Our framework is an important step towards the goal of building privacy preserving recommender systems.
motif2vec: Motif Aware Node Representation Learning for Heterogeneous Networks
Aug 22, 2019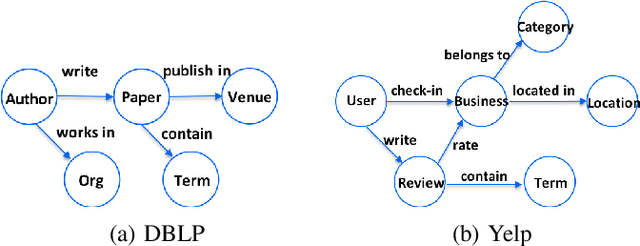



Recent years have witnessed a surge of interest in machine learning on graphs and networks with applications ranging from vehicular network design to IoT traffic management to social network recommendations. Supervised machine learning tasks in networks such as node classification and link prediction require us to perform feature engineering that is known and agreed to be the key to success in applied machine learning. Research efforts dedicated to representation learning, especially representation learning using deep learning, has shown us ways to automatically learn relevant features from vast amounts of potentially noisy, raw data. However, most of the methods are not adequate to handle heterogeneous information networks which pretty much represents most real-world data today. The methods cannot preserve the structure and semantic of multiple types of nodes and links well enough, capture higher-order heterogeneous connectivity patterns, and ensure coverage of nodes for which representations are generated. We propose a novel efficient algorithm, motif2vec that learns node representations or embeddings for heterogeneous networks. Specifically, we leverage higher-order, recurring, and statistically significant network connectivity patterns in the form of motifs to transform the original graph to motif graph(s), conduct biased random walk to efficiently explore higher order neighborhoods, and then employ heterogeneous skip-gram model to generate the embeddings. Unlike previous efforts that uses different graph meta-structures to guide the random walk, we use graph motifs to transform the original network and preserve the heterogeneity. We evaluate the proposed algorithm on multiple real-world networks from diverse domains and against existing state-of-the-art methods on multi-class node classification and link prediction tasks, and demonstrate its consistent superiority over prior work.
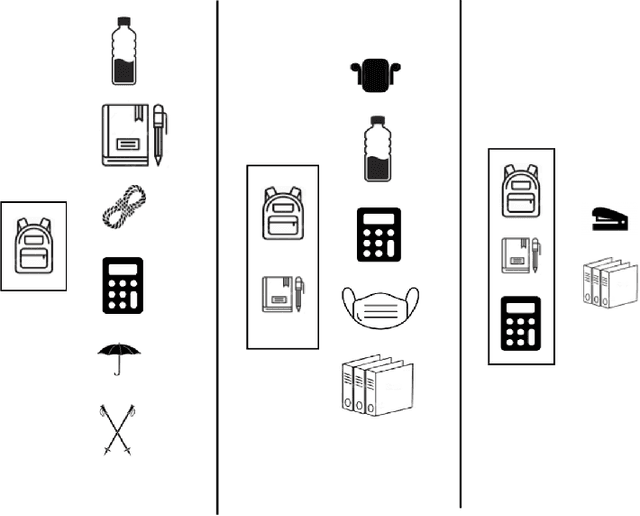
How Much Are You Willing to Share? A "Poker-Styled" Selective Privacy Preserving Framework for Recommender Systems
Jun 04, 2018

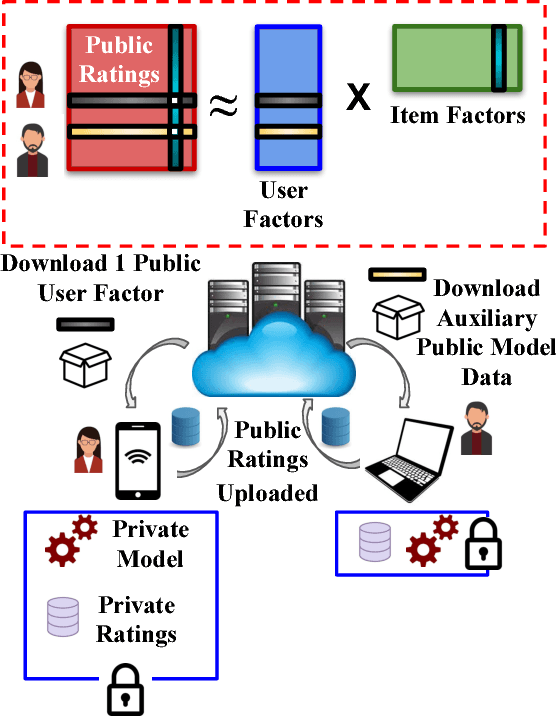
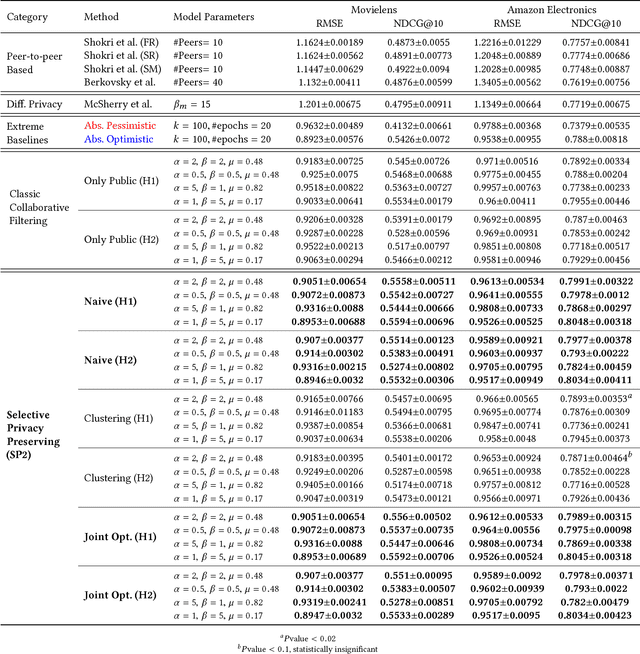
Most industrial recommender systems rely on the popular collaborative filtering (CF) technique for providing personalized recommendations to its users. However, the very nature of CF is adversarial to the idea of user privacy, because users need to share their preferences with others in order to be grouped with like-minded people and receive accurate recommendations. While previous privacy preserving approaches have been successful inasmuch as they concealed user preference information to some extent from a centralized recommender system, they have also, nevertheless, incurred significant trade-offs in terms of privacy, scalability, and accuracy. They are also vulnerable to privacy breaches by malicious actors. In light of these observations, we propose a novel selective privacy preserving (SP2) paradigm that allows users to custom define the scope and extent of their individual privacies, by marking their personal ratings as either public (which can be shared) or private (which are never shared and stored only on the user device). Our SP2 framework works in two steps: (i) First, it builds an initial recommendation model based on the sum of all public ratings that have been shared by users and (ii) then, this public model is fine-tuned on each user's device based on the user private ratings, thus eventually learning a more accurate model. Furthermore, in this work, we introduce three different algorithms for implementing an end-to-end SP2 framework that can scale effectively from thousands to hundreds of millions of items. Our user survey shows that an overwhelming fraction of users are likely to rate much more items to improve the overall recommendations when they can control what ratings will be publicly shared with others.