 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigData Applications from Graph Analytics to Machine Learning by Aggregates in Recursion
Sep 18, 2019In the past, the semantic issues raised by the non-monotonic nature of aggregates often prevented their use in the recursive statements of logic programs and deductive databases. However, the recently introduced notion of Pre-mappability (PreM) has shown that, in key applications of interest, aggregates can be used in recursion to optimize the perfect-model semantics of aggregate-stratified programs. Therefore we can preserve the declarative formal semantics of such programs while achieving a highly efficient operational semantics that is conducive to scalable implementations on parallel and distributed platforms. In this paper, we show that with PreM, a wide spectrum of classical algorithms of practical interest, ranging from graph analytics and dynamic programming based optimization problems to data mining and machine learning applications can be concisely expressed in declarative languages by using aggregates in recursion. Our examples are also used to show that PreM can be checked using simple techniques and templatized verification strategies. A wide range of advanced BigData applications can now be expressed declaratively in logic-based languages, including Datalog, Prolog, and even SQL, while enabling their execution with superior performance and scalability.
* In Proceedings ICLP 2019, arXiv:1909.07646. Paper presented at the 35th International Conference on Logic Programming (ICLP 2019), Las Cruces, New Mexico, USA, 20-25 September 2019, 7 pages (short paper - applications track)
How Much Are You Willing to Share? A "Poker-Styled" Selective Privacy Preserving Framework for Recommender Systems
Jun 04, 2018

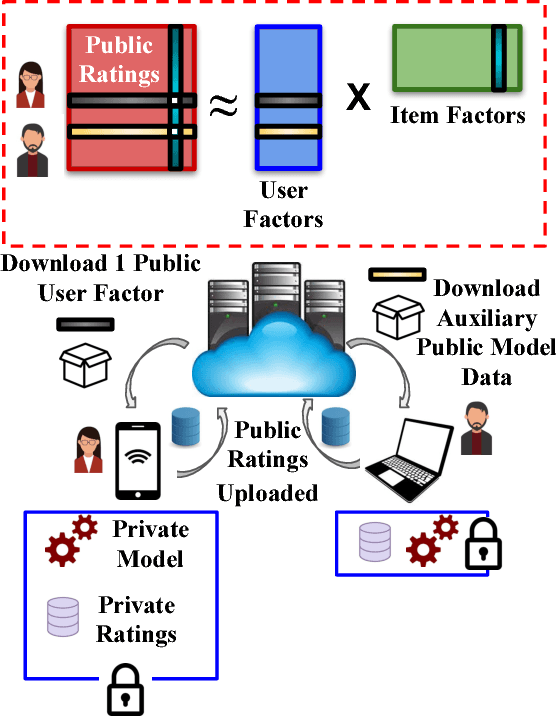
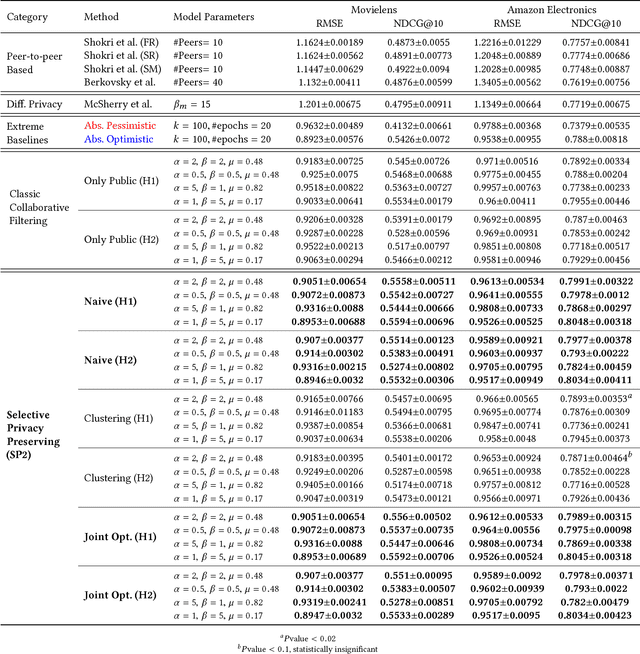
Most industrial recommender systems rely on the popular collaborative filtering (CF) technique for providing personalized recommendations to its users. However, the very nature of CF is adversarial to the idea of user privacy, because users need to share their preferences with others in order to be grouped with like-minded people and receive accurate recommendations. While previous privacy preserving approaches have been successful inasmuch as they concealed user preference information to some extent from a centralized recommender system, they have also, nevertheless, incurred significant trade-offs in terms of privacy, scalability, and accuracy. They are also vulnerable to privacy breaches by malicious actors. In light of these observations, we propose a novel selective privacy preserving (SP2) paradigm that allows users to custom define the scope and extent of their individual privacies, by marking their personal ratings as either public (which can be shared) or private (which are never shared and stored only on the user device). Our SP2 framework works in two steps: (i) First, it builds an initial recommendation model based on the sum of all public ratings that have been shared by users and (ii) then, this public model is fine-tuned on each user's device based on the user private ratings, thus eventually learning a more accurate model. Furthermore, in this work, we introduce three different algorithms for implementing an end-to-end SP2 framework that can scale effectively from thousands to hundreds of millions of items. Our user survey shows that an overwhelming fraction of users are likely to rate much more items to improve the overall recommendations when they can control what ratings will be publicly shared with others.