 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Logic based Logical Query Answering on Knowledge Graph
Aug 05, 2021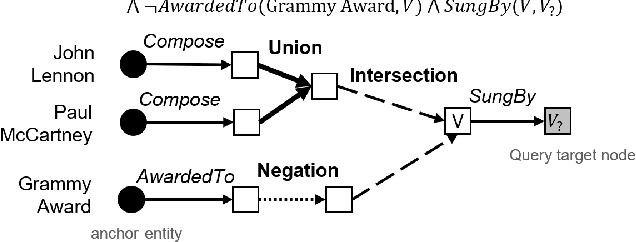
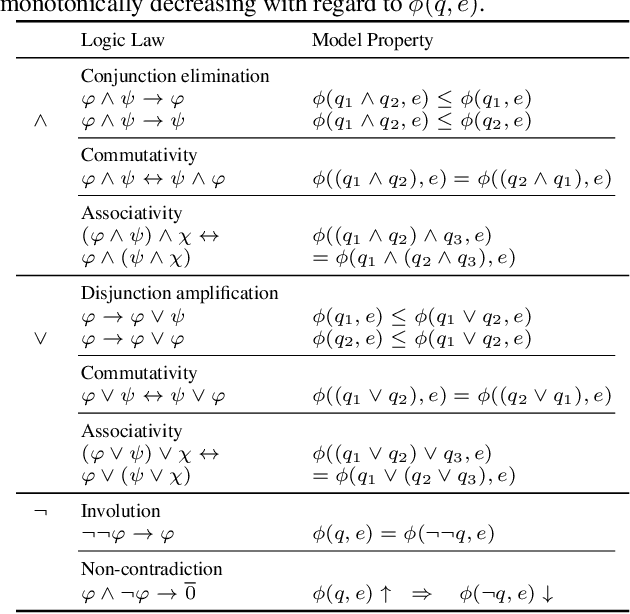

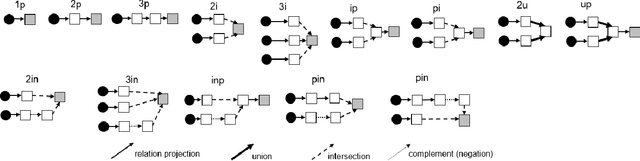
Answering complex First-Order Logical (FOL) queries on large-scale incomplete knowledge graphs (KGs) is an important yet challenging task. Recent advances embed logical queries and KG entities in the vector space and conduct query answering via dense similarity search. However, most of the designed logical operators in existing works do not satisfy the axiomatic system of classical logic. Moreover, these logical operators are parameterized so that they require a large number of complex FOL queries as training data, which are often arduous or even inaccessible to collect in most real-world KGs. In this paper, we present FuzzQE, a fuzzy logic based query embedding framework for answering FOL queries over KGs. FuzzQE follows fuzzy logic to define logical operators in a principled and learning free manner. Extensive experiments on two benchmark datasets demonstrate that FuzzQE achieves significantly better performance in answering FOL queries compared to the state-of-the-art methods. In addition, FuzzQE trained with only KG link prediction without any complex queries can achieve comparable performance with the systems trained with all FOL queries.
Probabilistic Box Embeddings for Uncertain Knowledge Graph Reasoning
Apr 09, 2021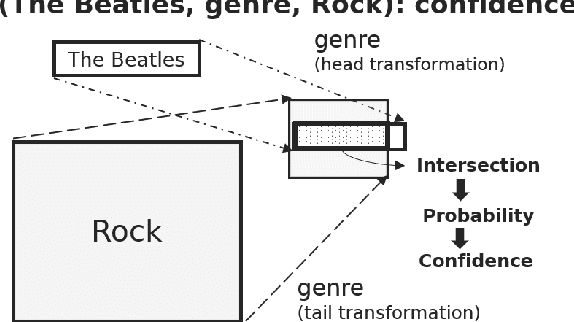

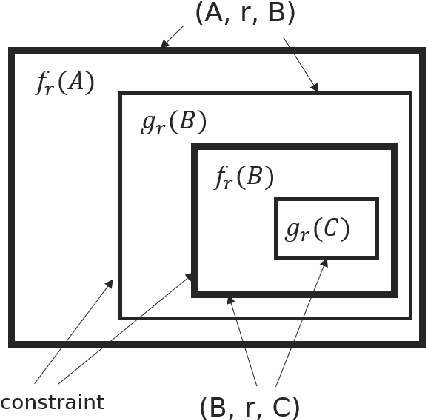
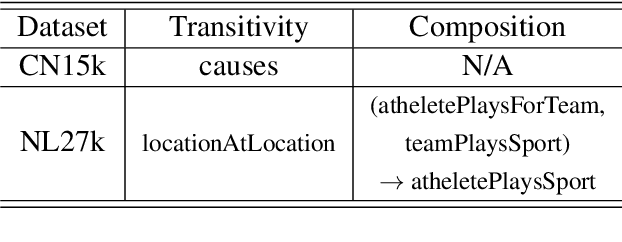
Knowledge bases often consist of facts which are harvested from a variety of sources, many of which are noisy and some of which conflict, resulting in a level of uncertainty for each triple. Knowledge bases are also often incomplete, prompting the use of embedding methods to generalize from known facts, however, existing embedding methods only model triple-level uncertainty, and reasoning results lack global consistency. To address these shortcomings, we propose BEUrRE, a novel uncertain knowledge graph embedding method with calibrated probabilistic semantics. BEUrRE models each entity as a box (i.e. axis-aligned hyperrectangle) and relations between two entities as affine transforms on the head and tail entity boxes. The geometry of the boxes allows for efficient calculation of intersections and volumes, endowing the model with calibrated probabilistic semantics and facilitating the incorporation of relational constraints. Extensive experiments on two benchmark datasets show that BEUrRE consistently outperforms baselines on confidence prediction and fact ranking due to its probabilistic calibration and ability to capture high-order dependencies among facts.
Multilingual Knowledge Graph Completion via Ensemble Knowledge Transfer
Oct 08, 2020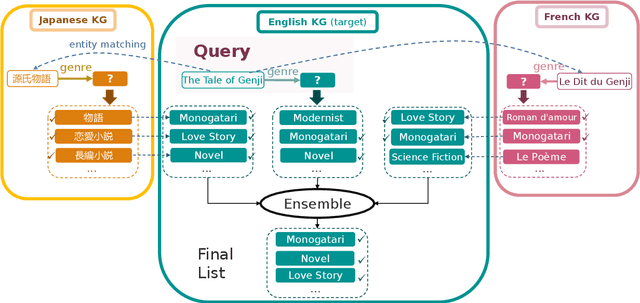
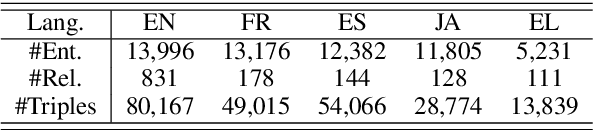
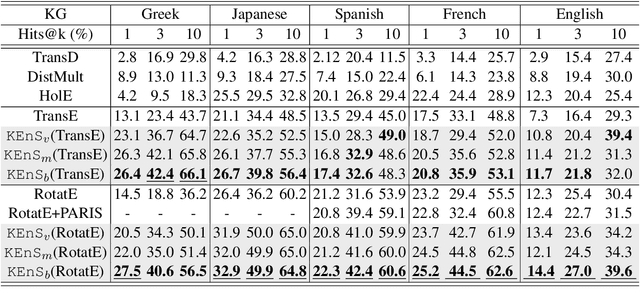
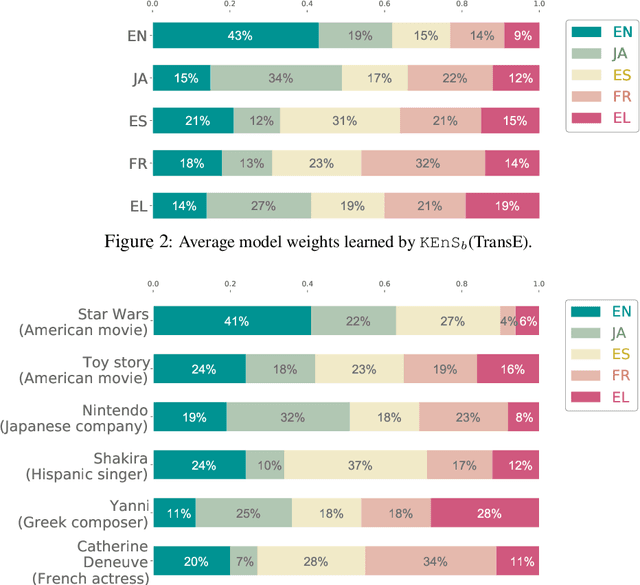
Predicting missing facts in a knowledge graph (KG) is a crucial task in knowledge base construction and reasoning, and it has been the subject of much research in recent works using KG embeddings. While existing KG embedding approaches mainly learn and predict facts within a single KG, a more plausible solution would benefit from the knowledge in multiple language-specific KGs, considering that different KGs have their own strengths and limitations on data quality and coverage. This is quite challenging, since the transfer of knowledge among multiple independently maintained KGs is often hindered by the insufficiency of alignment information and the inconsistency of described facts. In this paper, we propose KEnS, a novel framework for embedding learning and ensemble knowledge transfer across a number of language-specific KGs. KEnS embeds all KGs in a shared embedding space, where the association of entities is captured based on self-learning. Then, KEnS performs ensemble inference to combine prediction results from embeddings of multiple language-specific KGs, for which multiple ensemble techniques are investigated. Experiments on five real-world language-specific KGs show that KEnS consistently improves state-of-the-art methods on KG completion, via effectively identifying and leveraging complementary knowledge.
Embedding Uncertain Knowledge Graphs
Nov 26, 2018

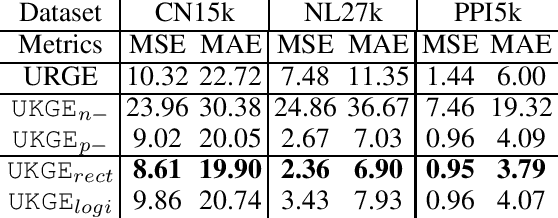
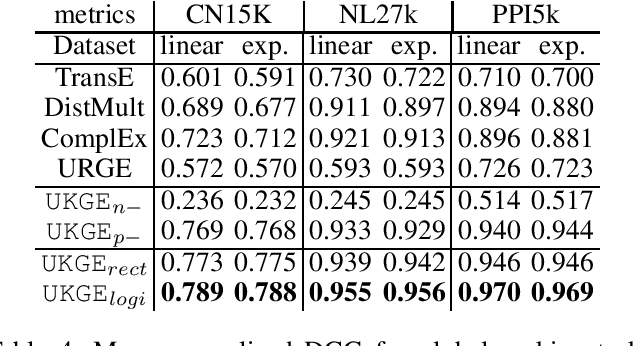
Embedding models for deterministic Knowledge Graphs (KG) have been extensively studied, with the purpose of capturing latent semantic relations between entities and incorporating the structured knowledge into machine learning. However, there are many KGs that model uncertain knowledge, which typically model the inherent uncertainty of relations facts with a confidence score, and embedding such uncertain knowledge represents an unresolved challenge. The capturing of uncertain knowledge will benefit many knowledge-driven applications such as question answering and semantic search by providing more natural characterization of the knowledge. In this paper, we propose a novel uncertain KG embedding model UKGE, which aims to preserve both structural and uncertainty information of relation facts in the embedding space. Unlike previous models that characterize relation facts with binary classification techniques, UKGE learns embeddings according to the confidence scores of uncertain relation facts. To further enhance the precision of UKGE, we also introduce probabilistic soft logic to infer confidence scores for unseen relation facts during training. We propose and evaluate two variants of UKGE based on different learning objectives. Experiments are conducted on three real-world uncertain KGs via three tasks, i.e. confidence prediction, relation fact ranking, and relation fact classification. UKGE shows effectiveness in capturing uncertain knowledge by achieving promising results on these tasks, and consistently outperforms baselines on these tasks.
On2Vec: Embedding-based Relation Prediction for Ontology Population
Sep 07, 2018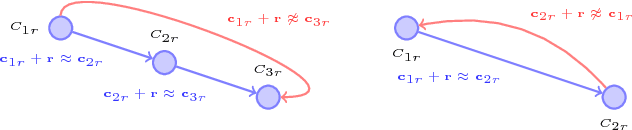

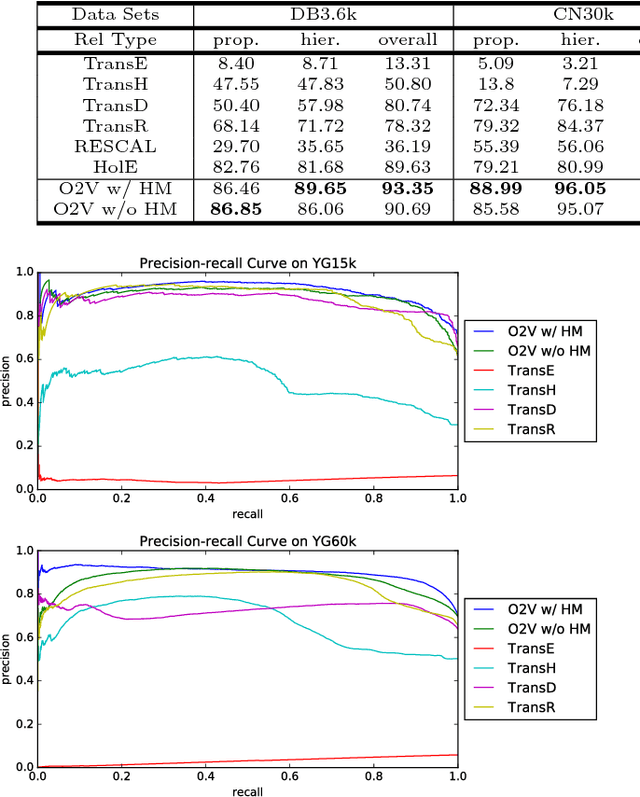
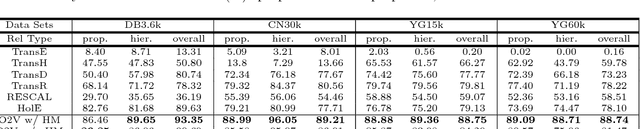
Populating ontology graphs represents a long-standing problem for the Semantic Web community. Recent advances in translation-based graph embedding methods for populating instance-level knowledge graphs lead to promising new approaching for the ontology population problem. However, unlike instance-level graphs, the majority of relation facts in ontology graphs come with comprehensive semantic relations, which often include the properties of transitivity and symmetry, as well as hierarchical relations. These comprehensive relations are often too complex for existing graph embedding methods, and direct application of such methods is not feasible. Hence, we propose On2Vec, a novel translation-based graph embedding method for ontology population. On2Vec integrates two model components that effectively characterize comprehensive relation facts in ontology graphs. The first is the Component-specific Model that encodes concepts and relations into low-dimensional embedding spaces without a loss of relational properties; the second is the Hierarchy Model that performs focused learning of hierarchical relation facts. Experiments on several well-known ontology graphs demonstrate the promising capabilities of On2Vec in predicting and verifying new relation facts. These promising results also make possible significant improvements in related methods.