 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROMPT2BOX: Uncovering Entailment Structure among LLM Prompts
Mar 22, 2026To discover the weaknesses of LLMs, researchers often embed prompts into a vector space and cluster them to extract insightful patterns. However, vector embeddings primarily capture topical similarity. As a result, prompts that share a topic but differ in specificity, and consequently in difficulty, are often represented similarly, making fine-grained weakness analysis difficult. To address this limitation, we propose PROMPT2BOX, which embeds prompts into a box embedding space using a trained encoder. The encoder, trained on existing and synthesized datasets, outputs box embeddings that capture not only semantic similarity but also specificity relations between prompts (e.g., "writing an adventure story" is more specific than "writing a story"). We further develop a novel dimension reduction technique for box embeddings to facilitate dataset visualization and comparison. Our experiments demonstrate that box embeddings consistently capture prompt specificity better than vector baselines. On the downstream task of creating hierarchical clustering trees for 17 LLMs from the UltraFeedback dataset, PROMPT2BOX can identify 8.9\% more LLM weaknesses than vector baselines and achieves an approximately 33\% stronger correlation between hierarchical depth and instruction specificity.
Box Embeddings: An open-source library for representation learning using geometric structures
Sep 10, 2021
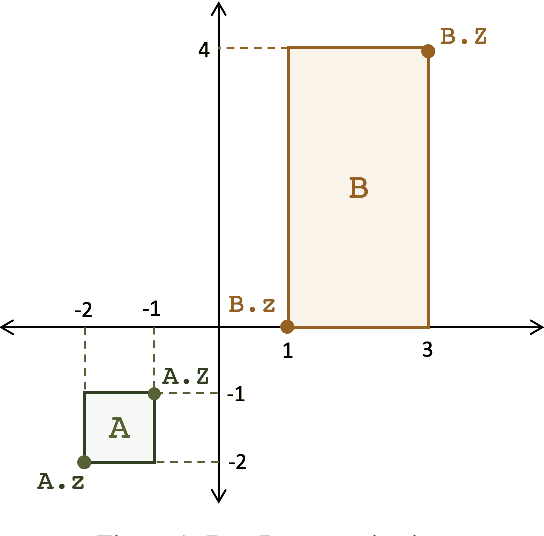
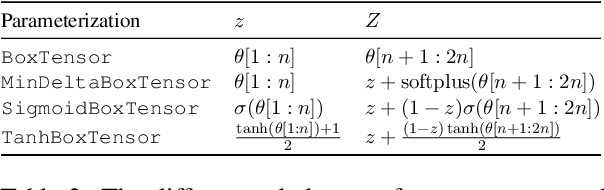
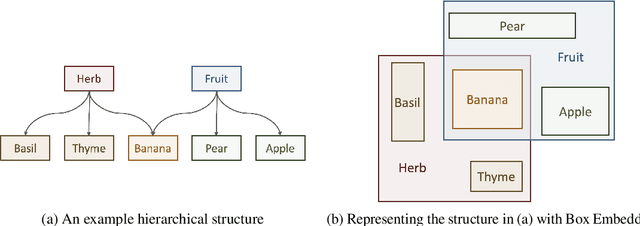
A major factor contributing to the success of modern representation learning is the ease of performing various vector operations. Recently, objects with geometric structures (eg. distributions, complex or hyperbolic vectors, or regions such as cones, disks, or boxes) have been explored for their alternative inductive biases and additional representational capacities. In this work, we introduce Box Embeddings, a Python library that enables researchers to easily apply and extend probabilistic box embeddings.
Word2Box: Learning Word Representation Using Box Embeddings
Jun 28, 2021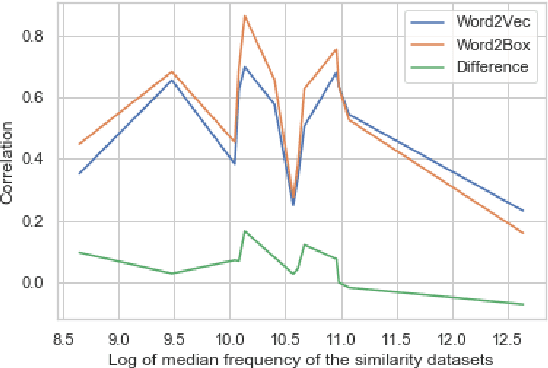



Learning vector representations for words is one of the most fundamental topics in NLP, capable of capturing syntactic and semantic relationships useful in a variety of downstream NLP tasks. Vector representations can be limiting, however, in that typical scoring such as dot product similarity intertwines position and magnitude of the vector in space. Exciting innovations in the space of representation learning have proposed alternative fundamental representations, such as distributions, hyperbolic vectors, or regions. Our model, Word2Box, takes a region-based approach to the problem of word representation, representing words as $n$-dimensional rectangles. These representations encode position and breadth independently and provide additional geometric operations such as intersection and containment which allow them to model co-occurrence patterns vectors struggle with. We demonstrate improved performance on various word similarity tasks, particularly on less common words, and perform a qualitative analysis exploring the additional unique expressivity provided by Word2Box.
Probabilistic Box Embeddings for Uncertain Knowledge Graph Reasoning
Apr 09, 2021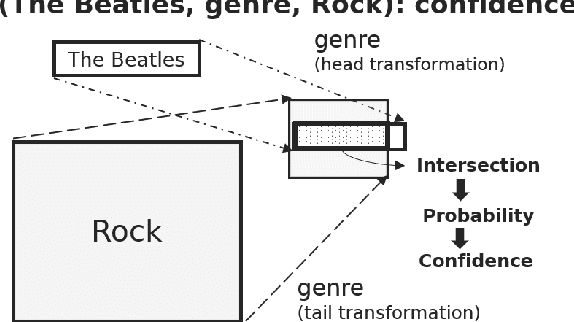

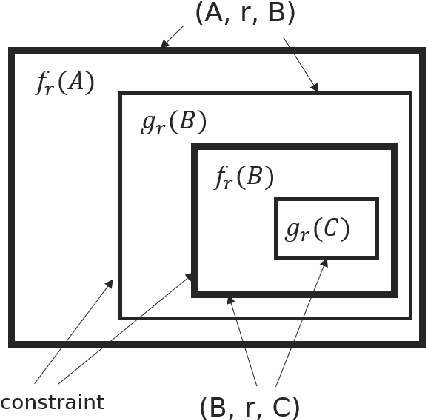
Knowledge bases often consist of facts which are harvested from a variety of sources, many of which are noisy and some of which conflict, resulting in a level of uncertainty for each triple. Knowledge bases are also often incomplete, prompting the use of embedding methods to generalize from known facts, however, existing embedding methods only model triple-level uncertainty, and reasoning results lack global consistency. To address these shortcomings, we propose BEUrRE, a novel uncertain knowledge graph embedding method with calibrated probabilistic semantics. BEUrRE models each entity as a box (i.e. axis-aligned hyperrectangle) and relations between two entities as affine transforms on the head and tail entity boxes. The geometry of the boxes allows for efficient calculation of intersections and volumes, endowing the model with calibrated probabilistic semantics and facilitating the incorporation of relational constraints. Extensive experiments on two benchmark datasets show that BEUrRE consistently outperforms baselines on confidence prediction and fact ranking due to its probabilistic calibration and ability to capture high-order dependencies among facts.
Improving Local Identifiability in Probabilistic Box Embeddings
Oct 29, 2020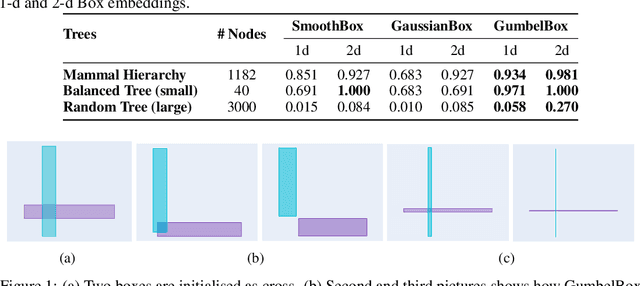
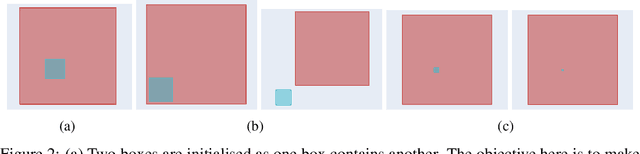
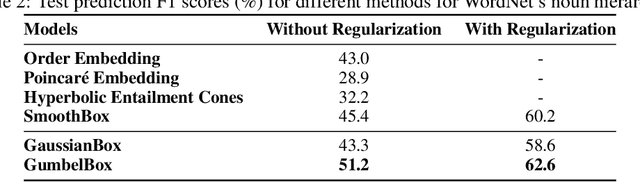
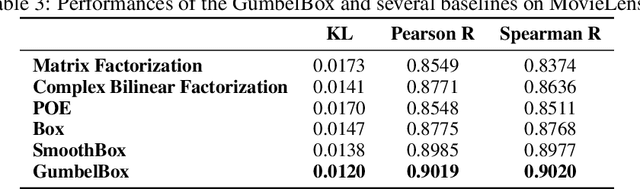
Geometric embeddings have recently received attention for their natural ability to represent transitive asymmetric relations via containment. Box embeddings, where objects are represented by n-dimensional hyperrectangles, are a particularly promising example of such an embedding as they are closed under intersection and their volume can be calculated easily, allowing them to naturally represent calibrated probability distributions. The benefits of geometric embeddings also introduce a problem of local identifiability, however, where whole neighborhoods of parameters result in equivalent loss which impedes learning. Prior work addressed some of these issues by using an approximation to Gaussian convolution over the box parameters, however, this intersection operation also increases the sparsity of the gradient. In this work, we model the box parameters with min and max Gumbel distributions, which were chosen such that space is still closed under the operation of the intersection. The calculation of the expected intersection volume involves all parameters, and we demonstrate experimentally that this drastically improves the ability of such models to learn.
Dating Documents using Graph Convolution Networks
Feb 01, 2019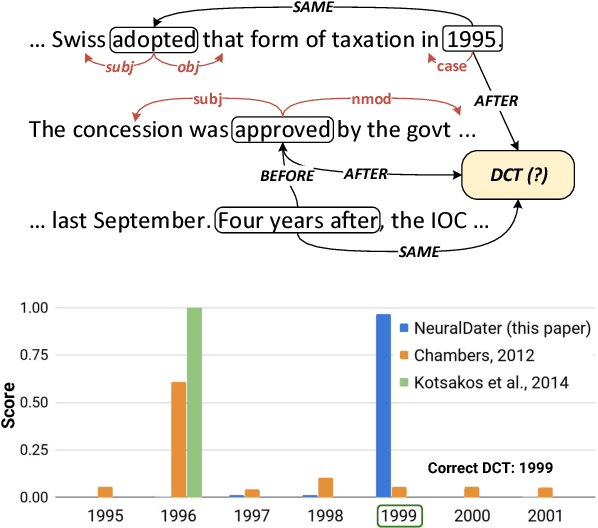
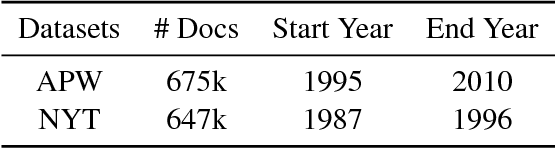
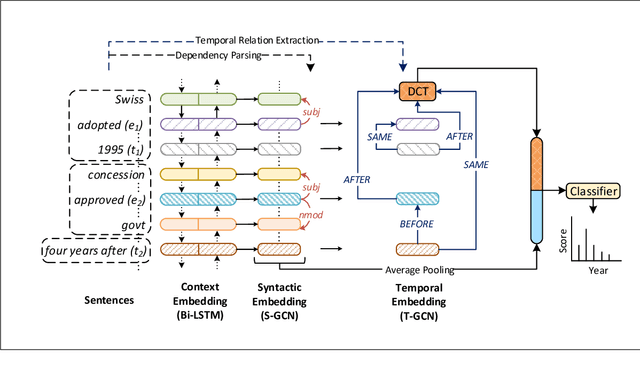
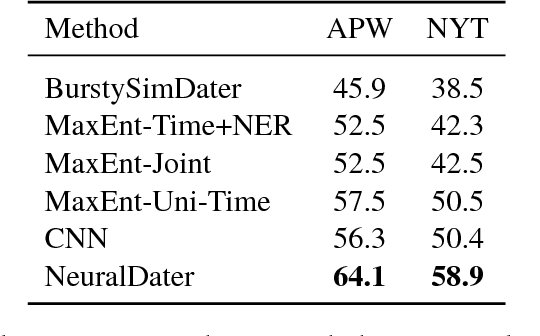
Document date is essential for many important tasks, such as document retrieval, summarization, event detection, etc. While existing approaches for these tasks assume accurate knowledge of the document date, this is not always available, especially for arbitrary documents from the Web. Document Dating is a challenging problem which requires inference over the temporal structure of the document. Prior document dating systems have largely relied on handcrafted features while ignoring such document internal structures. In this paper, we propose NeuralDater, a Graph Convolutional Network (GCN) based document dating approach which jointly exploits syntactic and temporal graph structures of document in a principled way. To the best of our knowledge, this is the first application of deep learning for the problem of document dating. Through extensive experiments on real-world datasets, we find that NeuralDater significantly outperforms state-of-the-art baseline by 19% absolute (45% relative) accuracy points.
* Accepted at ACL 2018