 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Usage and Engagement in AI-Powered Scientific Research Tools: The Asta Interaction Dataset
Feb 26, 2026AI-powered scientific research tools are rapidly being integrated into research workflows, yet the field lacks a clear lens into how researchers use these systems in real-world settings. We present and analyze the Asta Interaction Dataset, a large-scale resource comprising over 200,000 user queries and interaction logs from two deployed tools (a literature discovery interface and a scientific question-answering interface) within an LLM-powered retrieval-augmented generation platform. Using this dataset, we characterize query patterns, engagement behaviors, and how usage evolves with experience. We find that users submit longer and more complex queries than in traditional search, and treat the system as a collaborative research partner, delegating tasks such as drafting content and identifying research gaps. Users treat generated responses as persistent artifacts, revisiting and navigating among outputs and cited evidence in non-linear ways. With experience, users issue more targeted queries and engage more deeply with supporting citations, although keyword-style queries persist even among experienced users. We release the anonymized dataset and analysis with a new query intent taxonomy to inform future designs of real-world AI research assistants and to support realistic evaluation.
Robustness of Explanation Methods for NLP Models
Jun 24, 2022



Explanation methods have emerged as an important tool to highlight the features responsible for the predictions of neural networks. There is mounting evidence that many explanation methods are rather unreliable and susceptible to malicious manipulations. In this paper, we particularly aim to understand the robustness of explanation methods in the context of text modality. We provide initial insights and results towards devising a successful adversarial attack against text explanations. To our knowledge, this is the first attempt to evaluate the adversarial robustness of an explanation method. Our experiments show the explanation method can be largely disturbed for up to 86% of the tested samples with small changes in the input sentence and its semantics.
Word2Box: Learning Word Representation Using Box Embeddings
Jun 28, 2021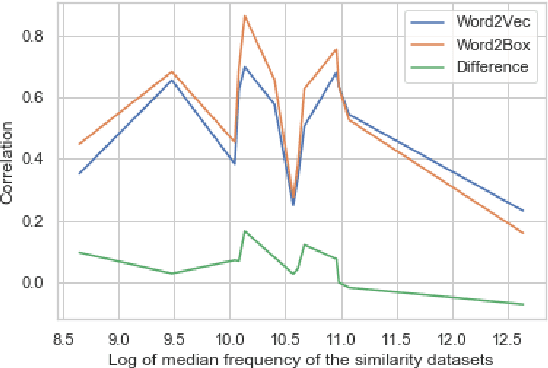



Learning vector representations for words is one of the most fundamental topics in NLP, capable of capturing syntactic and semantic relationships useful in a variety of downstream NLP tasks. Vector representations can be limiting, however, in that typical scoring such as dot product similarity intertwines position and magnitude of the vector in space. Exciting innovations in the space of representation learning have proposed alternative fundamental representations, such as distributions, hyperbolic vectors, or regions. Our model, Word2Box, takes a region-based approach to the problem of word representation, representing words as $n$-dimensional rectangles. These representations encode position and breadth independently and provide additional geometric operations such as intersection and containment which allow them to model co-occurrence patterns vectors struggle with. We demonstrate improved performance on various word similarity tasks, particularly on less common words, and perform a qualitative analysis exploring the additional unique expressivity provided by Word2Box.