 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXLM: A Python package for non-autoregressive language models
Dec 18, 2025In recent years, there has been a resurgence of interest in non-autoregressive text generation in the context of general language modeling. Unlike the well-established autoregressive language modeling paradigm, which has a plethora of standard training and inference libraries, implementations of non-autoregressive language modeling have largely been bespoke making it difficult to perform systematic comparisons of different methods. Moreover, each non-autoregressive language model typically requires it own data collation, loss, and prediction logic, making it challenging to reuse common components. In this work, we present the XLM python package, which is designed to make implementing small non-autoregressive language models faster with a secondary goal of providing a suite of small pre-trained models (through a companion xlm-models package) that can be used by the research community. The code is available at https://github.com/dhruvdcoder/xlm-core.
MiGrATe: Mixed-Policy GRPO for Adaptation at Test-Time
Aug 12, 2025Large language models (LLMs) are increasingly being applied to black-box optimization tasks, from program synthesis to molecule design. Prior work typically leverages in-context learning to iteratively guide the model towards better solutions. Such methods, however, often struggle to balance exploration of new solution spaces with exploitation of high-reward ones. Recently, test-time training (TTT) with synthetic data has shown promise in improving solution quality. However, the need for hand-crafted training data tailored to each task limits feasibility and scalability across domains. To address this problem, we introduce MiGrATe-a method for online TTT that uses GRPO as a search algorithm to adapt LLMs at inference without requiring external training data. MiGrATe operates via a mixed-policy group construction procedure that combines on-policy sampling with two off-policy data selection techniques: greedy sampling, which selects top-performing past completions, and neighborhood sampling (NS), which generates completions structurally similar to high-reward ones. Together, these components bias the policy gradient towards exploitation of promising regions in solution space, while preserving exploration through on-policy sampling. We evaluate MiGrATe on three challenging domains-word search, molecule optimization, and hypothesis+program induction on the Abstraction and Reasoning Corpus (ARC)-and find that it consistently outperforms both inference-only and TTT baselines, demonstrating the potential of online TTT as a solution for complex search tasks without external supervision.
Identity Theft in AI Conference Peer Review
Aug 06, 2025We discuss newly uncovered cases of identity theft in the scientific peer-review process within artificial intelligence (AI) research, with broader implications for other academic procedures. We detail how dishonest researchers exploit the peer-review system by creating fraudulent reviewer profiles to manipulate paper evaluations, leveraging weaknesses in reviewer recruitment workflows and identity verification processes. The findings highlight the critical need for stronger safeguards against identity theft in peer review and academia at large, and to this end, we also propose mitigating strategies.
OpenUnlearning: Accelerating LLM Unlearning via Unified Benchmarking of Methods and Metrics
Jun 14, 2025



Robust unlearning is crucial for safely deploying large language models (LLMs) in environments where data privacy, model safety, and regulatory compliance must be ensured. Yet the task is inherently challenging, partly due to difficulties in reliably measuring whether unlearning has truly occurred. Moreover, fragmentation in current methodologies and inconsistent evaluation metrics hinder comparative analysis and reproducibility. To unify and accelerate research efforts, we introduce OpenUnlearning, a standardized and extensible framework designed explicitly for benchmarking both LLM unlearning methods and metrics. OpenUnlearning integrates 9 unlearning algorithms and 16 diverse evaluations across 3 leading benchmarks (TOFU, MUSE, and WMDP) and also enables analyses of forgetting behaviors across 450+ checkpoints we publicly release. Leveraging OpenUnlearning, we propose a novel meta-evaluation benchmark focused specifically on assessing the faithfulness and robustness of evaluation metrics themselves. We also benchmark diverse unlearning methods and provide a comparative analysis against an extensive evaluation suite. Overall, we establish a clear, community-driven pathway toward rigorous development in LLM unlearning research.
Insertion Language Models: Sequence Generation with Arbitrary-Position Insertions
May 09, 2025Autoregressive models (ARMs), which predict subsequent tokens one-by-one ``from left to right,'' have achieved significant success across a wide range of sequence generation tasks. However, they struggle to accurately represent sequences that require satisfying sophisticated constraints or whose sequential dependencies are better addressed by out-of-order generation. Masked Diffusion Models (MDMs) address some of these limitations, but the process of unmasking multiple tokens simultaneously in MDMs can introduce incoherences, and MDMs cannot handle arbitrary infilling constraints when the number of tokens to be filled in is not known in advance. In this work, we introduce Insertion Language Models (ILMs), which learn to insert tokens at arbitrary positions in a sequence -- that is, they select jointly both the position and the vocabulary element to be inserted. By inserting tokens one at a time, ILMs can represent strong dependencies between tokens, and their ability to generate sequences in arbitrary order allows them to accurately model sequences where token dependencies do not follow a left-to-right sequential structure. To train ILMs, we propose a tailored network parameterization and use a simple denoising objective. Our empirical evaluation demonstrates that ILMs outperform both ARMs and MDMs on common planning tasks. Furthermore, we show that ILMs outperform MDMs and perform on par with ARMs in an unconditional text generation task while offering greater flexibility than MDMs in arbitrary-length text infilling.
Memory Augmented Cross-encoders for Controllable Personalized Search
Nov 05, 2024



Personalized search represents a problem where retrieval models condition on historical user interaction data in order to improve retrieval results. However, personalization is commonly perceived as opaque and not amenable to control by users. Further, personalization necessarily limits the space of items that users are exposed to. Therefore, prior work notes a tension between personalization and users' ability for discovering novel items. While discovery of novel items in personalization setups may be resolved through search result diversification, these approaches do little to allow user control over personalization. Therefore, in this paper, we introduce an approach for controllable personalized search. Our model, CtrlCE presents a novel cross-encoder model augmented with an editable memory constructed from users historical items. Our proposed memory augmentation allows cross-encoder models to condition on large amounts of historical user data and supports interaction from users permitting control over personalization. Further, controllable personalization for search must account for queries which don't require personalization, and in turn user control. For this, we introduce a calibrated mixing model which determines when personalization is necessary. This allows system designers using CtrlCE to only obtain user input for control when necessary. In multiple datasets of personalized search, we show CtrlCE to result in effective personalization as well as fulfill various key goals for controllable personalized search.
A Fresh Take on Stale Embeddings: Improving Dense Retriever Training with Corrector Networks
Sep 03, 2024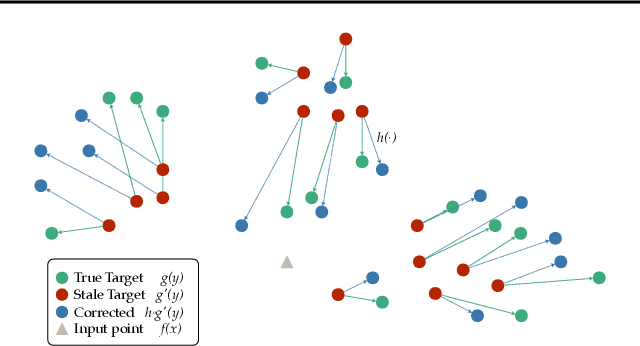
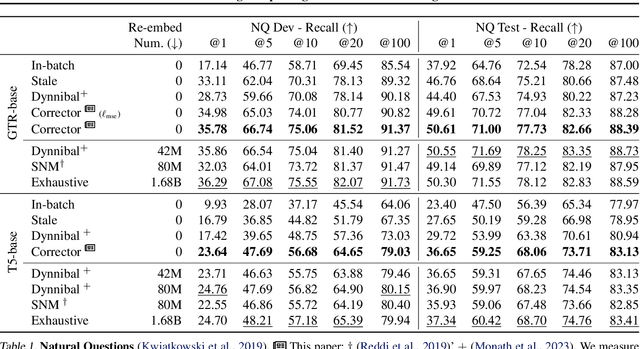
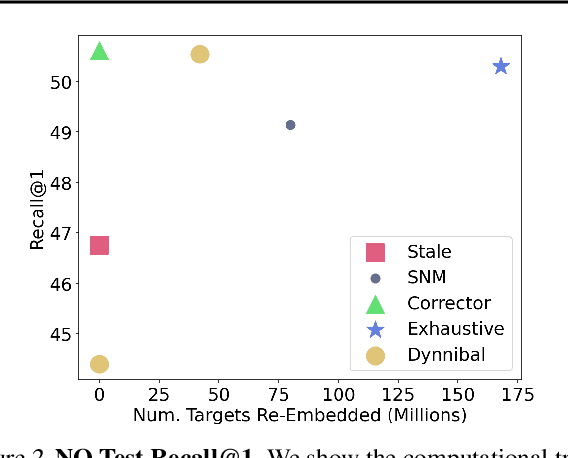
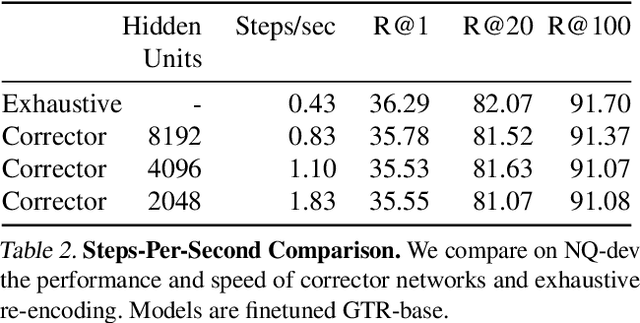
In dense retrieval, deep encoders provide embeddings for both inputs and targets, and the softmax function is used to parameterize a distribution over a large number of candidate targets (e.g., textual passages for information retrieval). Significant challenges arise in training such encoders in the increasingly prevalent scenario of (1) a large number of targets, (2) a computationally expensive target encoder model, (3) cached target embeddings that are out-of-date due to ongoing training of target encoder parameters. This paper presents a simple and highly scalable response to these challenges by training a small parametric corrector network that adjusts stale cached target embeddings, enabling an accurate softmax approximation and thereby sampling of up-to-date high scoring "hard negatives." We theoretically investigate the generalization properties of our proposed target corrector, relating the complexity of the network, staleness of cached representations, and the amount of training data. We present experimental results on large benchmark dense retrieval datasets as well as on QA with retrieval augmented language models. Our approach matches state-of-the-art results even when no target embedding updates are made during training beyond an initial cache from the unsupervised pre-trained model, providing a 4-80x reduction in re-embedding computational cost.
Analysis of Plan-based Retrieval for Grounded Text Generation
Aug 20, 2024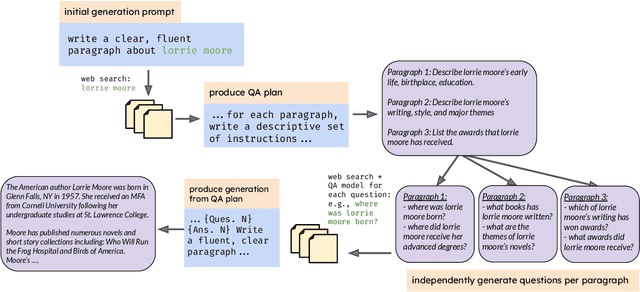
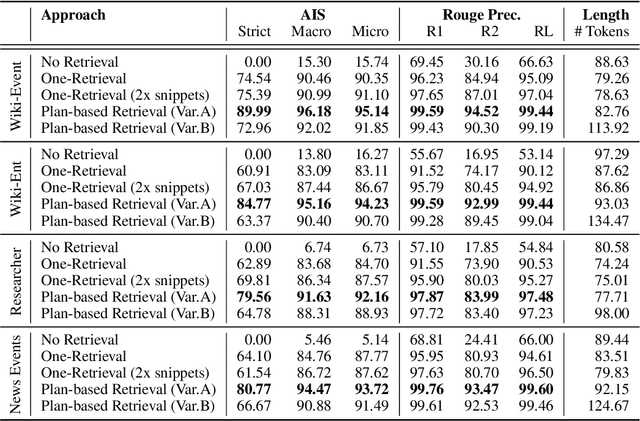

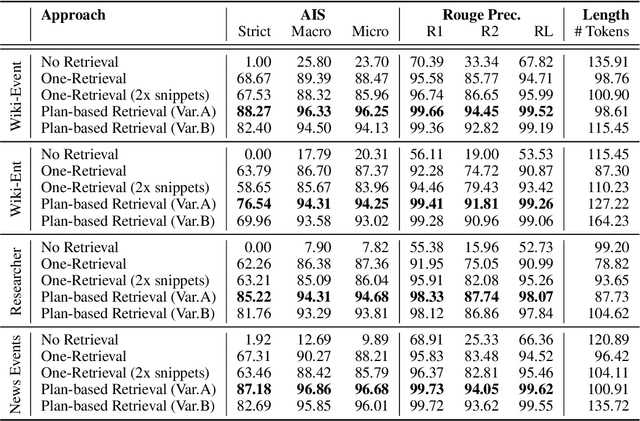
In text generation, hallucinations refer to the generation of seemingly coherent text that contradicts established knowledge. One compelling hypothesis is that hallucinations occur when a language model is given a generation task outside its parametric knowledge (due to rarity, recency, domain, etc.). A common strategy to address this limitation is to infuse the language models with retrieval mechanisms, providing the model with relevant knowledge for the task. In this paper, we leverage the planning capabilities of instruction-tuned LLMs and analyze how planning can be used to guide retrieval to further reduce the frequency of hallucinations. We empirically evaluate several variations of our proposed approach on long-form text generation tasks. By improving the coverage of relevant facts, plan-guided retrieval and generation can produce more informative responses while providing a higher rate of attribution to source documents.
Interactive Topic Models with Optimal Transport
Jun 28, 2024


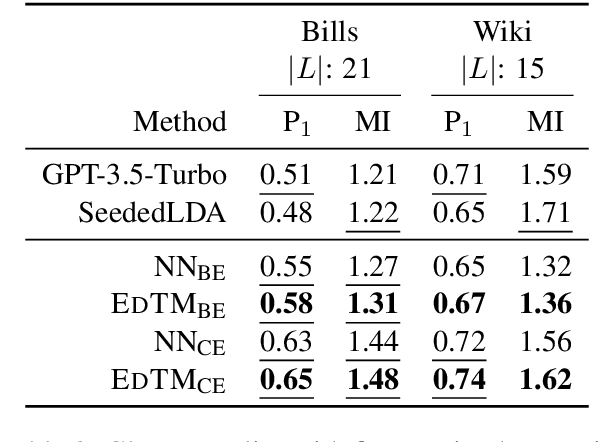
Topic models are widely used to analyze document collections. While they are valuable for discovering latent topics in a corpus when analysts are unfamiliar with the corpus, analysts also commonly start with an understanding of the content present in a corpus. This may be through categories obtained from an initial pass over the corpus or a desire to analyze the corpus through a predefined set of categories derived from a high level theoretical framework (e.g. political ideology). In these scenarios analysts desire a topic modeling approach which incorporates their understanding of the corpus while supporting various forms of interaction with the model. In this work, we present EdTM, as an approach for label name supervised topic modeling. EdTM models topic modeling as an assignment problem while leveraging LM/LLM based document-topic affinities and using optimal transport for making globally coherent topic-assignments. In experiments, we show the efficacy of our framework compared to few-shot LLM classifiers, and topic models based on clustering and LDA. Further, we show EdTM's ability to incorporate various forms of analyst feedback and while remaining robust to noisy analyst inputs.
Every Answer Matters: Evaluating Commonsense with Probabilistic Measures
Jun 06, 2024



Large language models have demonstrated impressive performance on commonsense tasks; however, these tasks are often posed as multiple-choice questions, allowing models to exploit systematic biases. Commonsense is also inherently probabilistic with multiple correct answers. The purpose of "boiling water" could be making tea and cooking, but it also could be killing germs. Existing tasks do not capture the probabilistic nature of common sense. To this end, we present commonsense frame completion (CFC), a new generative task that evaluates common sense via multiple open-ended generations. We also propose a method of probabilistic evaluation that strongly correlates with human judgments. Humans drastically outperform strong language model baselines on our dataset, indicating this approach is both a challenging and useful evaluation of machine common sense.