 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Answer Matters: Evaluating Commonsense with Probabilistic Measures
Jun 06, 2024



Large language models have demonstrated impressive performance on commonsense tasks; however, these tasks are often posed as multiple-choice questions, allowing models to exploit systematic biases. Commonsense is also inherently probabilistic with multiple correct answers. The purpose of "boiling water" could be making tea and cooking, but it also could be killing germs. Existing tasks do not capture the probabilistic nature of common sense. To this end, we present commonsense frame completion (CFC), a new generative task that evaluates common sense via multiple open-ended generations. We also propose a method of probabilistic evaluation that strongly correlates with human judgments. Humans drastically outperform strong language model baselines on our dataset, indicating this approach is both a challenging and useful evaluation of machine common sense.
A Dataset for Discourse Structure in Peer Review Discussions
Oct 16, 2021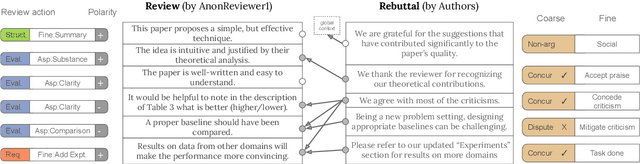
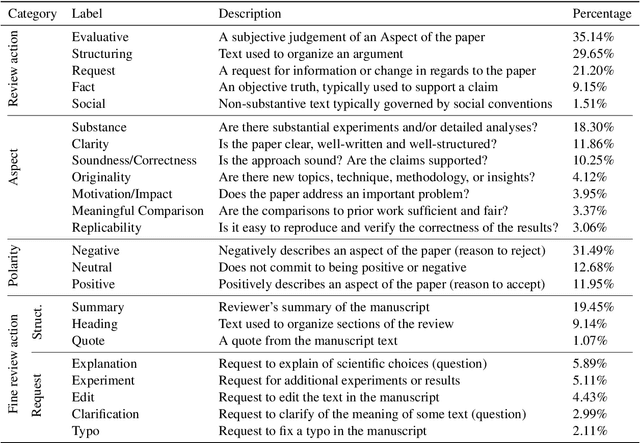

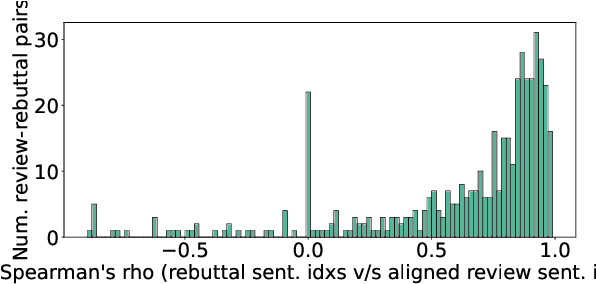
At the foundation of scientific evaluation is the labor-intensive process of peer review. This critical task requires participants to consume and interpret vast amounts of highly technical text. We show that discourse cues from rebuttals can shed light on the quality and interpretation of reviews. Further, an understanding of the argumentative strategies employed by the reviewers and authors provides useful signal for area chairs and other decision makers. This paper presents a new labeled dataset of 20k sentences contained in 506 review-rebuttal pairs in English, annotated by experts. While existing datasets annotate a subset of review sentences using various schemes, ours synthesizes existing label sets and extends them to include fine-grained annotation of the rebuttal sentences, characterizing the authors' stance towards the reviewers' criticisms and their commitment to addressing them. Further, we annotate \textit{every} sentence in both the review and the rebuttal, including a description of the context for each rebuttal sentence.