 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Differentiable Optimization via Model Transformations
Jun 10, 2022
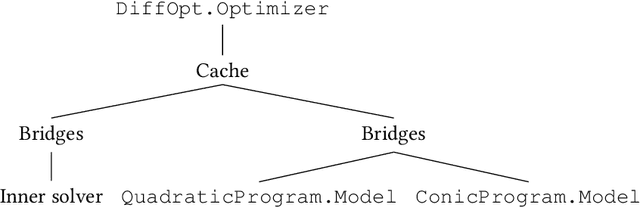

We introduce DiffOpt.jl, a Julia library to differentiate through the solution of convex optimization problems with respect to arbitrary parameters present in the objective and/or constraints. The library builds upon MathOptInterface, thus leveraging the rich ecosystem of solvers and composing well with modelling languages like JuMP. DiffOpt offers both forward and reverse differentiation modes, enabling multiple use cases from hyperparameter optimization to backpropagation and sensitivity analysis, bridging constrained optimization with end-to-end differentiable programming.
TinyMLOps: Operational Challenges for Widespread Edge AI Adoption
Mar 27, 2022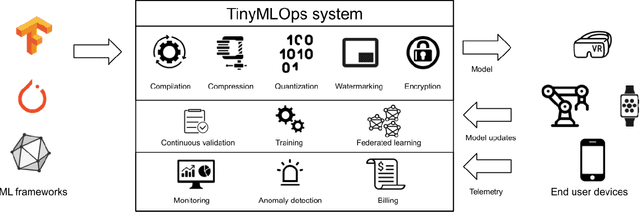
Deploying machine learning applications on edge devices can bring clear benefits such as improved reliability, latency and privacy but it also introduces its own set of challenges. Most works focus on the limited computational resources of edge platforms but this is not the only bottleneck standing in the way of widespread adoption. In this paper we list several other challenges that a TinyML practitioner might need to consider when operationalizing an application on edge devices. We focus on tasks such as monitoring and managing the application, common functionality for a MLOps platform, and show how they are complicated by the distributed nature of edge deployment. We also discuss issues that are unique to edge applications such as protecting a model's intellectual property and verifying its integrity.
A Dataset for Discourse Structure in Peer Review Discussions
Oct 16, 2021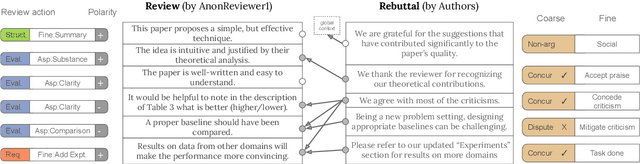
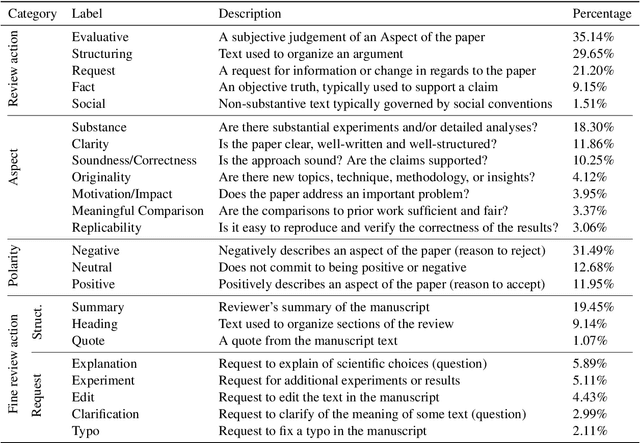

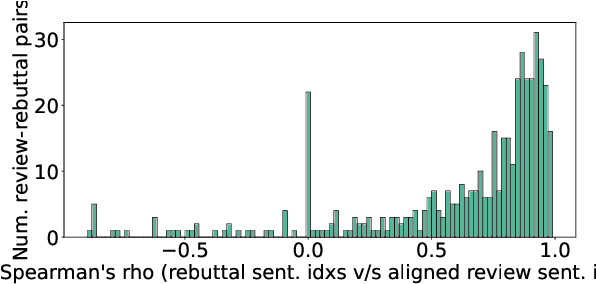
At the foundation of scientific evaluation is the labor-intensive process of peer review. This critical task requires participants to consume and interpret vast amounts of highly technical text. We show that discourse cues from rebuttals can shed light on the quality and interpretation of reviews. Further, an understanding of the argumentative strategies employed by the reviewers and authors provides useful signal for area chairs and other decision makers. This paper presents a new labeled dataset of 20k sentences contained in 506 review-rebuttal pairs in English, annotated by experts. While existing datasets annotate a subset of review sentences using various schemes, ours synthesizes existing label sets and extends them to include fine-grained annotation of the rebuttal sentences, characterizing the authors' stance towards the reviewers' criticisms and their commitment to addressing them. Further, we annotate \textit{every} sentence in both the review and the rebuttal, including a description of the context for each rebuttal sentence.
BayesAoA: A Bayesian method for Computation Efficient Angle of Arrival Estimation
Oct 15, 2021
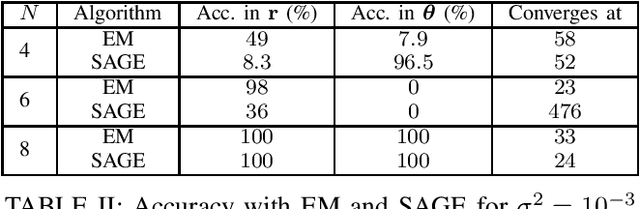


The angle of Arrival (AoA) estimation is of great interest in modern communication systems. Traditional maximum likelihood-based iterative algorithms are sensitive to initialization and cannot be used online. We propose a Bayesian method to find AoA that is insensitive towards initialization. The proposed method is less complex and needs fewer computing resources than traditional deep learning-based methods. It has a faster convergence than the brute-force methods. Further, a Hedge type solution is proposed that helps to deploy the method online to handle the situations where the channel noise and antenna configuration in the receiver change over time. The proposed method achieves $92\%$ accuracy in a channel of noise variance $10^{-6}$ with $19.3\%$ of the brute-force method's computation.
Domain Concretization from Examples: Addressing Missing Domain Knowledge via Robust Planning
Nov 18, 2020
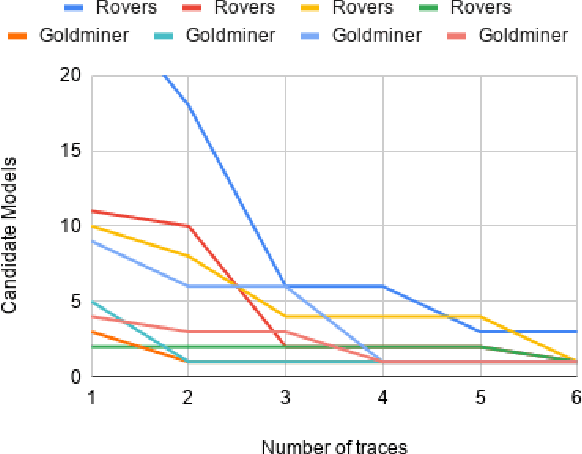
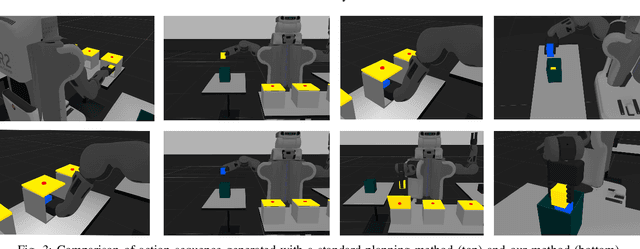

The assumption of complete domain knowledge is not warranted for robot planning and decision-making in the real world. It could be due to design flaws or arise from domain ramifications or qualifications. In such cases, existing planning and learning algorithms could produce highly undesirable behaviors. This problem is more challenging than partial observability in the sense that the agent is unaware of certain knowledge, in contrast to it being partially observable: the difference between known unknowns and unknown unknowns. In this work, we formulate it as the problem of Domain Concretization, an inverse problem to domain abstraction. Based on an incomplete domain model provided by the designer and teacher traces from human users, our algorithm searches for a candidate model set under a minimalistic model assumption. It then generates a robust plan with the maximum probability of success under the set of candidate models. In addition to a standard search formulation in the model-space, we propose a sample-based search method and also an online version of it to improve search time. We tested our approach on IPC domains and a simulated robotics domain where incompleteness was introduced by removing domain features from the complete model. Results show that our planning algorithm increases the plan success rate without impacting the cost much.
Order Matters: Generating Progressive Explanations for Planning Tasks in Human-Robot Teaming
Apr 16, 2020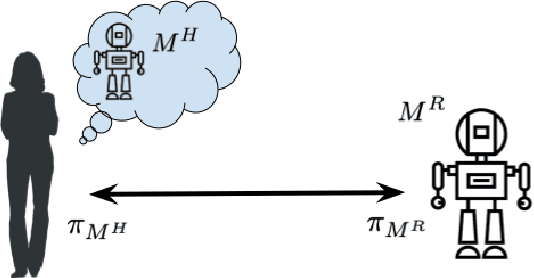
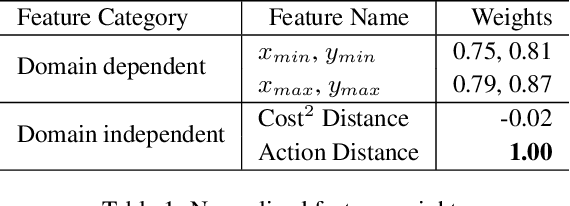
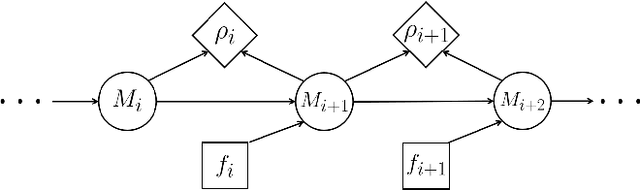
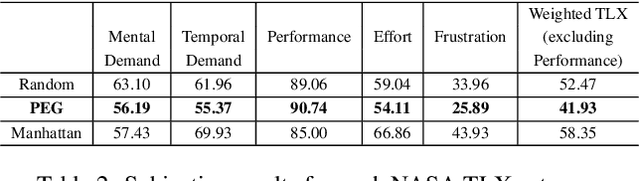
Prior work on generating explanations has been focused on providing the rationale behind the robot's decision making. While these approaches provide the right explanations from the explainer's perspective, they fail to heed the cognitive requirement of understanding an explanation from the explainee's perspective. In this work, we set out to address this issue from a planning context by considering the order of information provided in an explanation, which is referred to as the progressiveness of explanations. Progressive explanations contribute to a better understanding by minimizing the cumulative cognitive effort required for understanding all the information in an explanation. As a result, such explanations are easier to understand. Given the sequential nature of communicating information, a general formulation based on goal-based Markov Decision Processes for generating progressive explanation is presented. The reward function of this MDP is learned via inverse reinforcement learning based on explanations that are provided by human subjects. Our method is evaluated in an escape-room domain. The results show that our progressive explanation generation method reduces the cognitive load over two baselines.