 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuCL: Stratified Rubric-Based Curriculum Learning for Multimodal Large Language Model Reasoning
Feb 25, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a prevailing paradigm for enhancing reasoning in Multimodal Large Language Models (MLLMs). However, relying solely on outcome supervision risks reward hacking, where models learn spurious reasoning patterns to satisfy final answer checks. While recent rubric-based approaches offer fine-grained supervision signals, they suffer from high computational costs of instance-level generation and inefficient training dynamics caused by treating all rubrics as equally learnable. In this paper, we propose Stratified Rubric-based Curriculum Learning (RuCL), a novel framework that reformulates curriculum learning by shifting the focus from data selection to reward design. RuCL generates generalized rubrics for broad applicability and stratifies them based on the model's competence. By dynamically adjusting rubric weights during training, RuCL guides the model from mastering foundational perception to tackling advanced logical reasoning. Extensive experiments on various visual reasoning benchmarks show that RuCL yields a remarkable +7.83% average improvement over the Qwen2.5-VL-7B model, achieving a state-of-the-art accuracy of 60.06%.
Learning Ordinal Probabilistic Reward from Preferences
Feb 13, 2026Reward models are crucial for aligning large language models (LLMs) with human values and intentions. Existing approaches follow either Generative (GRMs) or Discriminative (DRMs) paradigms, yet both suffer from limitations: GRMs typically demand costly point-wise supervision, while DRMs produce uncalibrated relative scores that lack probabilistic interpretation. To address these challenges, we introduce a novel reward modeling paradigm: Probabilistic Reward Model (PRM). Instead of modeling reward as a deterministic scalar, our approach treats it as a random variable, learning a full probability distribution for the quality of each response. To make this paradigm practical, we present its closed-form, discrete realization: the Ordinal Probabilistic Reward Model (OPRM), which discretizes the quality score into a finite set of ordinal ratings. Building on OPRM, we propose a data-efficient training strategy called Region Flooding Tuning (RgFT). It enables rewards to better reflect absolute text quality by incorporating quality-level annotations, which guide the model to concentrate the probability mass within corresponding rating sub-regions. Experiments on various reward model benchmarks show that our method improves accuracy by $\textbf{2.9%}\sim\textbf{7.4%}$ compared to prior reward models, demonstrating strong performance and data efficiency. Analysis of the score distribution provides evidence that our method captures not only relative rankings but also absolute quality.
Offline Safe Policy Optimization From Heterogeneous Feedback
Dec 23, 2025Offline Preference-based Reinforcement Learning (PbRL) learns rewards and policies aligned with human preferences without the need for extensive reward engineering and direct interaction with human annotators. However, ensuring safety remains a critical challenge across many domains and tasks. Previous works on safe RL from human feedback (RLHF) first learn reward and cost models from offline data, then use constrained RL to optimize a safe policy. While such an approach works in the contextual bandits settings (LLMs), in long horizon continuous control tasks, errors in rewards and costs accumulate, leading to impairment in performance when used with constrained RL methods. To address these challenges, (a) instead of indirectly learning policies (from rewards and costs), we introduce a framework that learns a policy directly based on pairwise preferences regarding the agent's behavior in terms of rewards, as well as binary labels indicating the safety of trajectory segments; (b) we propose \textsc{PreSa} (Preference and Safety Alignment), a method that combines preference learning module with safety alignment in a constrained optimization problem. This optimization problem is solved within a Lagrangian paradigm that directly learns reward-maximizing safe policy \textit{without explicitly learning reward and cost models}, avoiding the need for constrained RL; (c) we evaluate our approach on continuous control tasks with both synthetic and real human feedback. Empirically, our method successfully learns safe policies with high rewards, outperforming state-of-the-art baselines, and offline safe RL approaches with ground-truth reward and cost.
Offline Safe Reinforcement Learning Using Trajectory Classification
Dec 19, 2024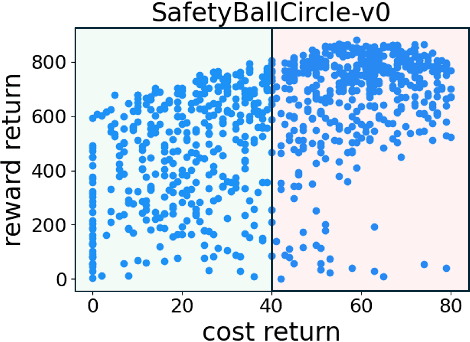

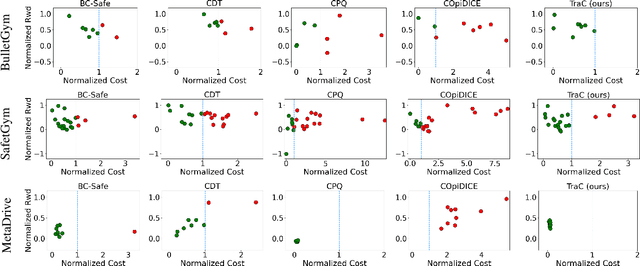

Offline safe reinforcement learning (RL) has emerged as a promising approach for learning safe behaviors without engaging in risky online interactions with the environment. Most existing methods in offline safe RL rely on cost constraints at each time step (derived from global cost constraints) and this can result in either overly conservative policies or violation of safety constraints. In this paper, we propose to learn a policy that generates desirable trajectories and avoids undesirable trajectories. To be specific, we first partition the pre-collected dataset of state-action trajectories into desirable and undesirable subsets. Intuitively, the desirable set contains high reward and safe trajectories, and undesirable set contains unsafe trajectories and low-reward safe trajectories. Second, we learn a policy that generates desirable trajectories and avoids undesirable trajectories, where (un)desirability scores are provided by a classifier learnt from the dataset of desirable and undesirable trajectories. This approach bypasses the computational complexity and stability issues of a min-max objective that is employed in existing methods. Theoretically, we also show our approach's strong connections to existing learning paradigms involving human feedback. Finally, we extensively evaluate our method using the DSRL benchmark for offline safe RL. Empirically, our method outperforms competitive baselines, achieving higher rewards and better constraint satisfaction across a wide variety of benchmark tasks.
Translating Natural Language to Planning Goals with Large-Language Models
Feb 10, 2023


Recent large language models (LLMs) have demonstrated remarkable performance on a variety of natural language processing (NLP) tasks, leading to intense excitement about their applicability across various domains. Unfortunately, recent work has also shown that LLMs are unable to perform accurate reasoning nor solve planning problems, which may limit their usefulness for robotics-related tasks. In this work, our central question is whether LLMs are able to translate goals specified in natural language to a structured planning language. If so, LLM can act as a natural interface between the planner and human users; the translated goal can be handed to domain-independent AI planners that are very effective at planning. Our empirical results on GPT 3.5 variants show that LLMs are much better suited towards translation rather than planning. We find that LLMs are able to leverage commonsense knowledge and reasoning to furnish missing details from under-specified goals (as is often the case in natural language). However, our experiments also reveal that LLMs can fail to generate goals in tasks that involve numerical or physical (e.g., spatial) reasoning, and that LLMs are sensitive to the prompts used. As such, these models are promising for translation to structured planning languages, but care should be taken in their use.
Order Matters: Generating Progressive Explanations for Planning Tasks in Human-Robot Teaming
Apr 16, 2020
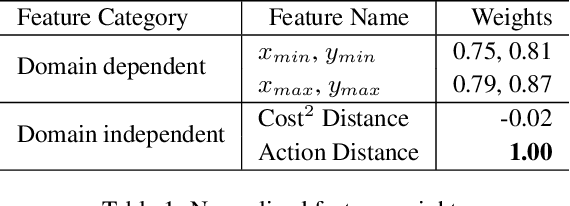
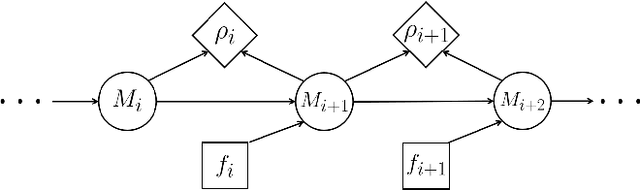
Prior work on generating explanations has been focused on providing the rationale behind the robot's decision making. While these approaches provide the right explanations from the explainer's perspective, they fail to heed the cognitive requirement of understanding an explanation from the explainee's perspective. In this work, we set out to address this issue from a planning context by considering the order of information provided in an explanation, which is referred to as the progressiveness of explanations. Progressive explanations contribute to a better understanding by minimizing the cumulative cognitive effort required for understanding all the information in an explanation. As a result, such explanations are easier to understand. Given the sequential nature of communicating information, a general formulation based on goal-based Markov Decision Processes for generating progressive explanation is presented. The reward function of this MDP is learned via inverse reinforcement learning based on explanations that are provided by human subjects. Our method is evaluated in an escape-room domain. The results show that our progressive explanation generation method reduces the cognitive load over two baselines.
Online Explanation Generation for Human-Robot Teaming
Apr 02, 2019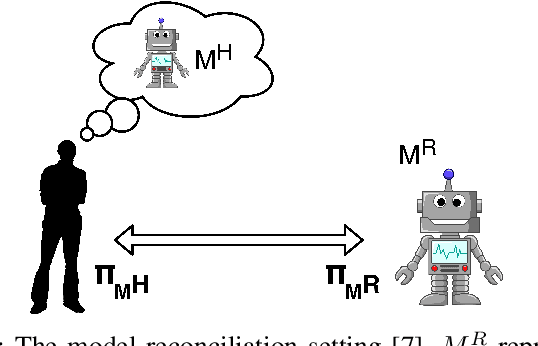
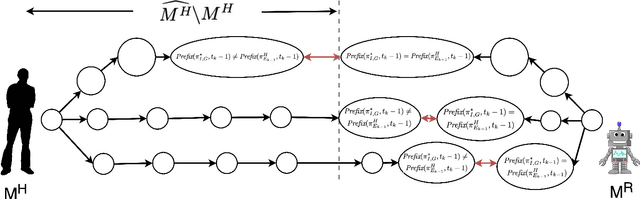

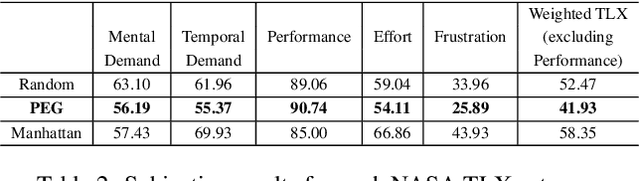
As Artificial Intelligence (AI) becomes an integral part of our life, the development of explainable AI, embodied in the decision-making process of an AI or robotic agent, becomes imperative. For a robotic teammate, the ability to generate explanations to explain its behavior is one of the key requirements of an explainable agency. Prior work on explanation generation focuses on supporting the reasoning behind the robot's behavior. These approaches, however, fail to consider the cognitive effort needed to understand the received explanation. In particular, the human teammate is expected to understand any explanation provided before the task execution, no matter how much information is presented in the explanation. In this work, we argue that an explanation, especially complex ones, should be made in an online fashion during the execution, which helps to spread out the information to be explained and thus reducing the cognitive load of humans. However, a challenge here is that the different parts of an explanation are dependent on each other, which must be taken into account when generating online explanations. To this end, a general formulation of online explanation generation is presented. We base our explanation generation method in a model reconciliation setting introduced in our prior work. Our approach is evaluated both with human subjects in a standard planning competition (IPC) domain, using NASA Task Load Index, as well as in simulation with ten different problems.
Correlated Equilibria for Approximate Variational Inference in MRFs
Oct 07, 2017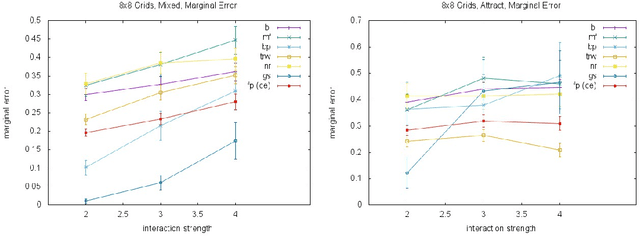
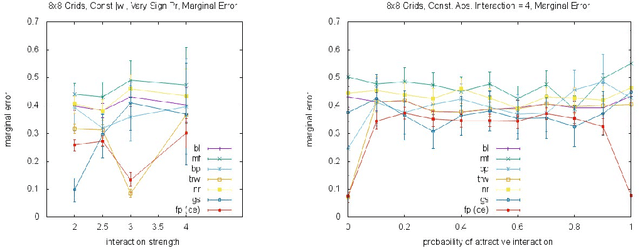
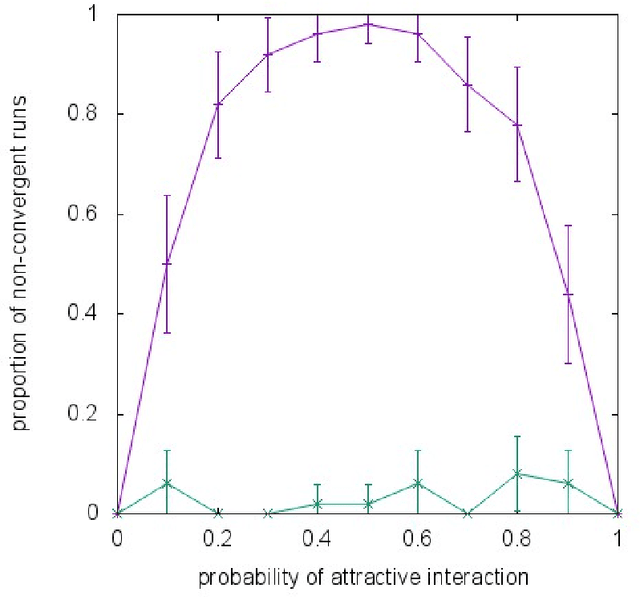
Almost all of the work in graphical models for game theory has mirrored previous work in probabilistic graphical models. Our work considers the opposite direction: Taking advantage of recent advances in equilibrium computation for probabilistic inference. We present formulations of inference problems in Markov random fields (MRFs) as computation of equilibria in a certain class of game-theoretic graphical models. We concretely establishes the precise connection between variational probabilistic inference in MRFs and correlated equilibria. No previous work exploits recent theoretical and empirical results from the literature on algorithmic and computational game theory on the tractable, polynomial-time computation of exact or approximate correlated equilibria in graphical games with arbitrary, loopy graph structure. We discuss how to design new algorithms with equally tractable guarantees for the computation of approximate variational inference in MRFs. Also, inspired by a previously stated game-theoretic view of state-of-the-art tree-reweighed (TRW) message-passing techniques for belief inference as zero-sum game, we propose a different, general-sum potential game to design approximate fictitious-play techniques. We perform synthetic experiments evaluating our proposed approximation algorithms with standard methods and TRW on several classes of classical Ising models (i.e., with binary random variables). We also evaluate the algorithms using Ising models learned from the MNIST dataset. Our experiments show that our global approach is competitive, particularly shinning in a class of Ising models with constant, "highly attractive" edge-weights, in which it is often better than all other alternatives we evaluated. With a notable exception, our more local approach was not as effective. Yet, in fairness, almost all of the alternatives are often no better than a simple baseline: estimate 0.5.