 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocRATES: Towards Automated Scenario-based Testing of Social Navigation Algorithms
Dec 27, 2024Current social navigation methods and benchmarks primarily focus on proxemics and task efficiency. While these factors are important, qualitative aspects such as perceptions of a robot's social competence are equally crucial for successful adoption and integration into human environments. We propose a more comprehensive evaluation of social navigation through scenario-based testing, where specific human-robot interaction scenarios can reveal key robot behaviors. However, creating such scenarios is often labor-intensive and complex. In this work, we address this challenge by introducing a pipeline that automates the generation of context-, and location-appropriate social navigation scenarios, ready for simulation. Our pipeline transforms simple scenario metadata into detailed textual scenarios, infers pedestrian and robot trajectories, and simulates pedestrian behaviors, which enables more controlled evaluation. We leverage the social reasoning and code-generation capabilities of Large Language Models (LLMs) to streamline scenario generation and translation. Our experiments show that our pipeline produces realistic scenarios and significantly improves scenario translation over naive LLM prompting. Additionally, we present initial feedback from a usability study with social navigation experts and a case-study demonstrating a scenario-based evaluation of three navigation algorithms.
Learning User-Interpretable Descriptions of Black-Box AI System Capabilities
Jul 28, 2021



Several approaches have been developed to answer specific questions that a user may have about an AI system that can plan and act. However, the problems of identifying which questions to ask and that of computing a user-interpretable symbolic description of the overall capabilities of the system have remained largely unaddressed. This paper presents an approach for addressing these problems by learning user-interpretable symbolic descriptions of the limits and capabilities of a black-box AI system using low-level simulators. It uses a hierarchical active querying paradigm to generate questions and to learn a user-interpretable model of the AI system based on its responses. In contrast to prior work, we consider settings where imprecision of the user's conceptual vocabulary precludes a direct expression of the agent's capabilities. Furthermore, our approach does not require assumptions about the internal design of the target AI system or about the methods that it may use to compute or learn task solutions. Empirical evaluation on several game-based simulator domains shows that this approach can efficiently learn symbolic models of AI systems that use a deterministic black-box policy in fully observable scenarios.
Order Matters: Generating Progressive Explanations for Planning Tasks in Human-Robot Teaming
Apr 16, 2020
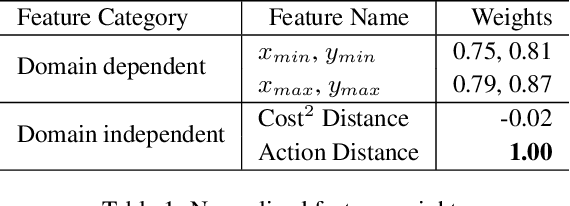
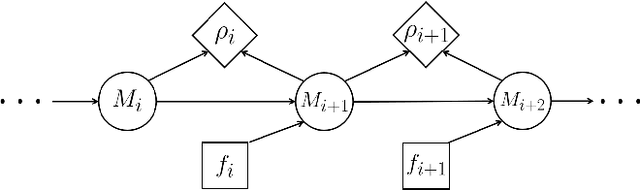
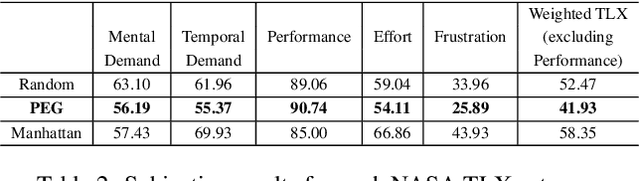
Prior work on generating explanations has been focused on providing the rationale behind the robot's decision making. While these approaches provide the right explanations from the explainer's perspective, they fail to heed the cognitive requirement of understanding an explanation from the explainee's perspective. In this work, we set out to address this issue from a planning context by considering the order of information provided in an explanation, which is referred to as the progressiveness of explanations. Progressive explanations contribute to a better understanding by minimizing the cumulative cognitive effort required for understanding all the information in an explanation. As a result, such explanations are easier to understand. Given the sequential nature of communicating information, a general formulation based on goal-based Markov Decision Processes for generating progressive explanation is presented. The reward function of this MDP is learned via inverse reinforcement learning based on explanations that are provided by human subjects. Our method is evaluated in an escape-room domain. The results show that our progressive explanation generation method reduces the cognitive load over two baselines.