 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder Matters: Generating Progressive Explanations for Planning Tasks in Human-Robot Teaming
Paper and Code
Apr 16, 2020
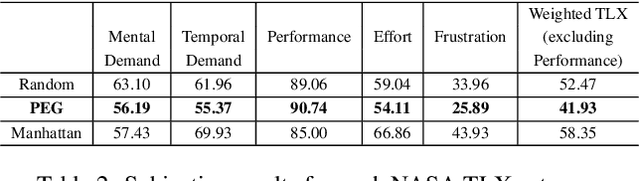
Prior work on generating explanations has been focused on providing the rationale behind the robot's decision making. While these approaches provide the right explanations from the explainer's perspective, they fail to heed the cognitive requirement of understanding an explanation from the explainee's perspective. In this work, we set out to address this issue from a planning context by considering the order of information provided in an explanation, which is referred to as the progressiveness of explanations. Progressive explanations contribute to a better understanding by minimizing the cumulative cognitive effort required for understanding all the information in an explanation. As a result, such explanations are easier to understand. Given the sequential nature of communicating information, a general formulation based on goal-based Markov Decision Processes for generating progressive explanation is presented. The reward function of this MDP is learned via inverse reinforcement learning based on explanations that are provided by human subjects. Our method is evaluated in an escape-room domain. The results show that our progressive explanation generation method reduces the cognitive load over two baselines.