 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Extractive Opinion Summarization Using Cover Trees
Paper and Code
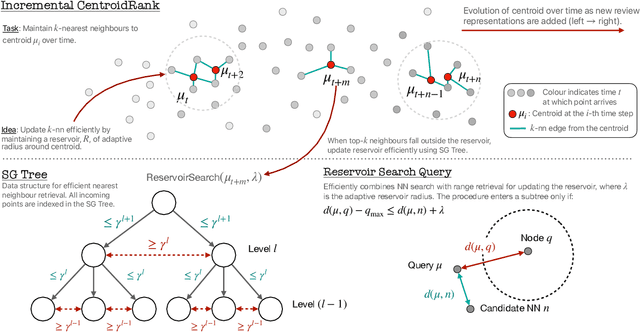
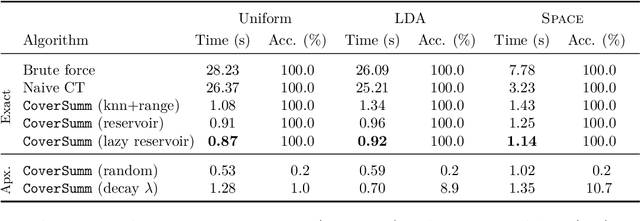
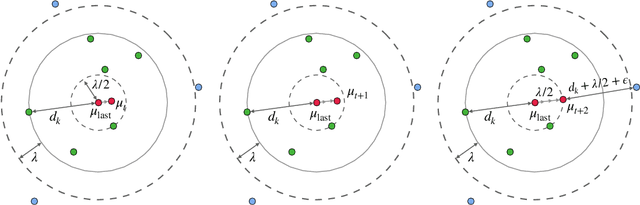
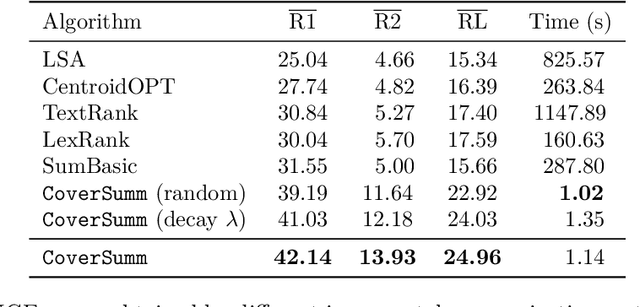
Extractive opinion summarization involves automatically producing a summary of text about an entity (e.g., a product's reviews) by extracting representative sentences that capture prevalent opinions in the review set. Typically, in online marketplaces user reviews accrue over time, and opinion summaries need to be updated periodically to provide customers with up-to-date information. In this work, we study the task of extractive opinion summarization in an incremental setting, where the underlying review set evolves over time. Many of the state-of-the-art extractive opinion summarization approaches are centrality-based, such as CentroidRank. CentroidRank performs extractive summarization by selecting a subset of review sentences closest to the centroid in the representation space as the summary. However, these methods are not capable of operating efficiently in an incremental setting, where reviews arrive one at a time. In this paper, we present an efficient algorithm for accurately computing the CentroidRank summaries in an incremental setting. Our approach, CoverSumm, relies on indexing review representations in a cover tree and maintaining a reservoir of candidate summary review sentences. CoverSumm's efficacy is supported by a theoretical and empirical analysis of running time. Empirically, on a diverse collection of data (both real and synthetically created to illustrate scaling considerations), we demonstrate that CoverSumm is up to 25x faster than baseline methods, and capable of adapting to nuanced changes in data distribution. We also conduct human evaluations of the generated summaries and find that CoverSumm is capable of producing informative summaries consistent with the underlying review set.