 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Augmented Cross-encoders for Controllable Personalized Search
Nov 05, 2024



Personalized search represents a problem where retrieval models condition on historical user interaction data in order to improve retrieval results. However, personalization is commonly perceived as opaque and not amenable to control by users. Further, personalization necessarily limits the space of items that users are exposed to. Therefore, prior work notes a tension between personalization and users' ability for discovering novel items. While discovery of novel items in personalization setups may be resolved through search result diversification, these approaches do little to allow user control over personalization. Therefore, in this paper, we introduce an approach for controllable personalized search. Our model, CtrlCE presents a novel cross-encoder model augmented with an editable memory constructed from users historical items. Our proposed memory augmentation allows cross-encoder models to condition on large amounts of historical user data and supports interaction from users permitting control over personalization. Further, controllable personalization for search must account for queries which don't require personalization, and in turn user control. For this, we introduce a calibrated mixing model which determines when personalization is necessary. This allows system designers using CtrlCE to only obtain user input for control when necessary. In multiple datasets of personalized search, we show CtrlCE to result in effective personalization as well as fulfill various key goals for controllable personalized search.
Interactive Topic Models with Optimal Transport
Jun 28, 2024


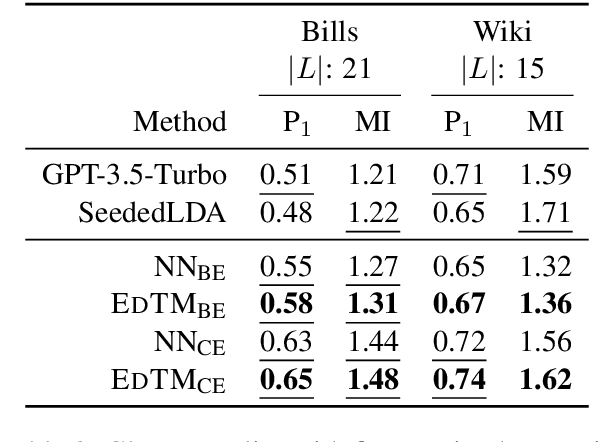
Topic models are widely used to analyze document collections. While they are valuable for discovering latent topics in a corpus when analysts are unfamiliar with the corpus, analysts also commonly start with an understanding of the content present in a corpus. This may be through categories obtained from an initial pass over the corpus or a desire to analyze the corpus through a predefined set of categories derived from a high level theoretical framework (e.g. political ideology). In these scenarios analysts desire a topic modeling approach which incorporates their understanding of the corpus while supporting various forms of interaction with the model. In this work, we present EdTM, as an approach for label name supervised topic modeling. EdTM models topic modeling as an assignment problem while leveraging LM/LLM based document-topic affinities and using optimal transport for making globally coherent topic-assignments. In experiments, we show the efficacy of our framework compared to few-shot LLM classifiers, and topic models based on clustering and LDA. Further, we show EdTM's ability to incorporate various forms of analyst feedback and while remaining robust to noisy analyst inputs.