 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Augmented Cross-encoders for Controllable Personalized Search
Nov 05, 2024



Personalized search represents a problem where retrieval models condition on historical user interaction data in order to improve retrieval results. However, personalization is commonly perceived as opaque and not amenable to control by users. Further, personalization necessarily limits the space of items that users are exposed to. Therefore, prior work notes a tension between personalization and users' ability for discovering novel items. While discovery of novel items in personalization setups may be resolved through search result diversification, these approaches do little to allow user control over personalization. Therefore, in this paper, we introduce an approach for controllable personalized search. Our model, CtrlCE presents a novel cross-encoder model augmented with an editable memory constructed from users historical items. Our proposed memory augmentation allows cross-encoder models to condition on large amounts of historical user data and supports interaction from users permitting control over personalization. Further, controllable personalization for search must account for queries which don't require personalization, and in turn user control. For this, we introduce a calibrated mixing model which determines when personalization is necessary. This allows system designers using CtrlCE to only obtain user input for control when necessary. In multiple datasets of personalized search, we show CtrlCE to result in effective personalization as well as fulfill various key goals for controllable personalized search.
Forecasting Live Chat Intent from Browsing History
Aug 07, 2024Customers reach out to online live chat agents with various intents, such as asking about product details or requesting a return. In this paper, we propose the problem of predicting user intent from browsing history and address it through a two-stage approach. The first stage classifies a user's browsing history into high-level intent categories. Here, we represent each browsing history as a text sequence of page attributes and use the ground-truth class labels to fine-tune pretrained Transformers. The second stage provides a large language model (LLM) with the browsing history and predicted intent class to generate fine-grained intents. For automatic evaluation, we use a separate LLM to judge the similarity between generated and ground-truth intents, which closely aligns with human judgments. Our two-stage approach yields significant performance gains compared to generating intents without the classification stage.
Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
Apr 09, 2024This paper studies retrieval-augmented approaches for personalizing large language models (LLMs), which potentially have a substantial impact on various applications and domains. We propose the first attempt to optimize the retrieval models that deliver a limited number of personal documents to large language models for the purpose of personalized generation. We develop two optimization algorithms that solicit feedback from the downstream personalized generation tasks for retrieval optimization--one based on reinforcement learning whose reward function is defined using any arbitrary metric for personalized generation and another based on knowledge distillation from the downstream LLM to the retrieval model. This paper also introduces a pre- and post-generation retriever selection model that decides what retriever to choose for each LLM input. Extensive experiments on diverse tasks from the language model personalization (LaMP) benchmark reveal statistically significant improvements in six out of seven datasets.
Overview of the TREC 2023 Product Product Search Track
Nov 15, 2023



This is the first year of the TREC Product search track. The focus this year was the creation of a reusable collection and evaluation of the impact of the use of metadata and multi-modal data on retrieval accuracy. This year we leverage the new product search corpus, which includes contextual metadata. Our analysis shows that in the product search domain, traditional retrieval systems are highly effective and commonly outperform general-purpose pretrained embedding models. Our analysis also evaluates the impact of using simplified and metadata-enhanced collections, finding no clear trend in the impact of the expanded collection. We also see some surprising outcomes; despite their widespread adoption and competitive performance on other tasks, we find single-stage dense retrieval runs can commonly be noncompetitive or generate low-quality results both in the zero-shot and fine-tuned domain.
A Personalized Dense Retrieval Framework for Unified Information Access
Apr 26, 2023Developing a universal model that can efficiently and effectively respond to a wide range of information access requests -- from retrieval to recommendation to question answering -- has been a long-lasting goal in the information retrieval community. This paper argues that the flexibility, efficiency, and effectiveness brought by the recent development in dense retrieval and approximate nearest neighbor search have smoothed the path towards achieving this goal. We develop a generic and extensible dense retrieval framework, called \framework, that can handle a wide range of (personalized) information access requests, such as keyword search, query by example, and complementary item recommendation. Our proposed approach extends the capabilities of dense retrieval models for ad-hoc retrieval tasks by incorporating user-specific preferences through the development of a personalized attentive network. This allows for a more tailored and accurate personalized information access experience. Our experiments on real-world e-commerce data suggest the feasibility of developing universal information access models by demonstrating significant improvements even compared to competitive baselines specifically developed for each of these individual information access tasks. This work opens up a number of fundamental research directions for future exploration.
A Boring-yet-effective Approach for the Product Ranking Task of the Amazon KDD Cup 2022
Aug 09, 2022
In this work we describe our submission to the product ranking task of the Amazon KDD Cup 2022. We rely on a receipt that showed to be effective in previous competitions: we focus our efforts towards efficiently training and deploying large language odels, such as mT5, while reducing to a minimum the number of task-specific adaptations. Despite the simplicity of our approach, our best model was less than 0.004 nDCG@20 below the top submission. As the top 20 teams achieved an nDCG@20 close to .90, we argue that we need more difficult e-Commerce evaluation datasets to discriminate retrieval methods.
Diversifying Multi-aspect Search Results Using Simpson's Diversity Index
May 21, 2021
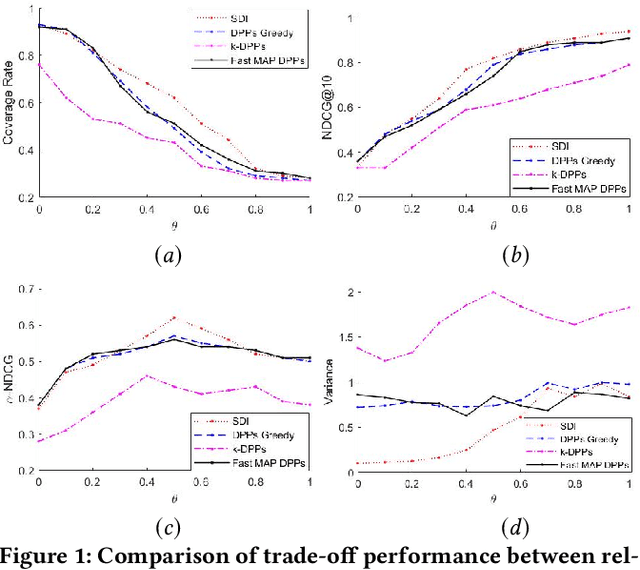
In search and recommendation, diversifying the multi-aspect search results could help with reducing redundancy, and promoting results that might not be shown otherwise. Many previous methods have been proposed for this task. However, previous methods do not explicitly consider the uniformity of the number of the items' classes, or evenness, which could degrade the search and recommendation quality. To address this problem, we introduce a novel method by adapting the Simpson's Diversity Index from biology, which enables a more effective and efficient quadratic search result diversification algorithm. We also extend the method to balance the diversity between multiple aspects through weighted factors and further improve computational complexity by developing a fast approximation algorithm. We demonstrate the feasibility of the proposed method using the openly available Kaggle shoes competition dataset. Our experimental results show that our approach outperforms previous state of the art diversification methods, while reducing computational complexity.
* Proceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM '20), October 19--23, 2020, Virtual Event, Ireland}
De-Biased Modelling of Search Click Behavior with Reinforcement Learning
May 21, 2021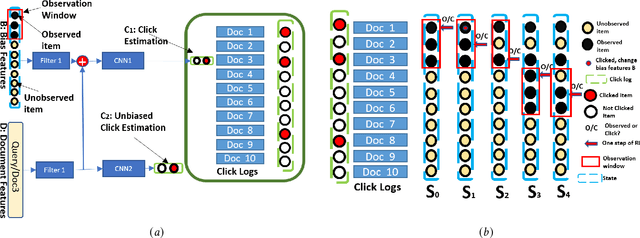

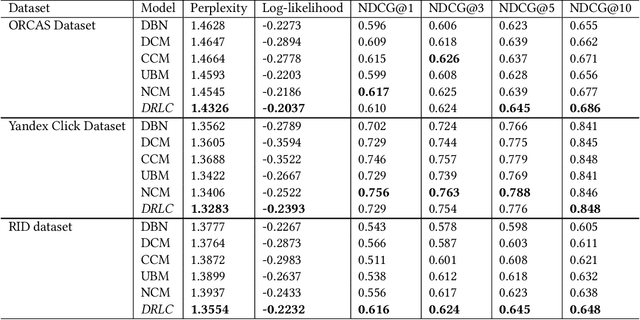
Users' clicks on Web search results are one of the key signals for evaluating and improving web search quality and have been widely used as part of current state-of-the-art Learning-To-Rank(LTR) models. With a large volume of search logs available for major search engines, effective models of searcher click behavior have emerged to evaluate and train LTR models. However, when modeling the users' click behavior, considering the bias of the behavior is imperative. In particular, when a search result is not clicked, it is not necessarily chosen as not relevant by the user, but instead could have been simply missed, especially for lower-ranked results. These kinds of biases in the click log data can be incorporated into the click models, propagating the errors to the resulting LTR ranking models or evaluation metrics. In this paper, we propose the De-biased Reinforcement Learning Click model (DRLC). The DRLC model relaxes previously made assumptions about the users' examination behavior and resulting latent states. To implement the DRLC model, convolutional neural networks are used as the value networks for reinforcement learning, trained to learn a policy to reduce bias in the click logs. To demonstrate the effectiveness of the DRLC model, we first compare performance with the previous state-of-art approaches using established click prediction metrics, including log-likelihood and perplexity. We further show that DRLC also leads to improvements in ranking performance. Our experiments demonstrate the effectiveness of the DRLC model in learning to reduce bias in click logs, leading to improved modeling performance and showing the potential for using DRLC for improving Web search quality.
APRF-Net: Attentive Pseudo-Relevance Feedback Network for Query Categorization
May 10, 2021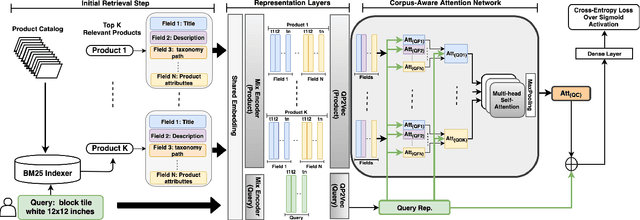
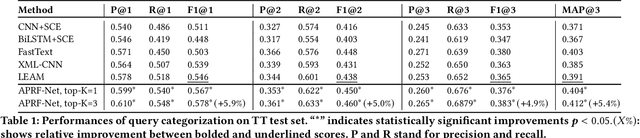
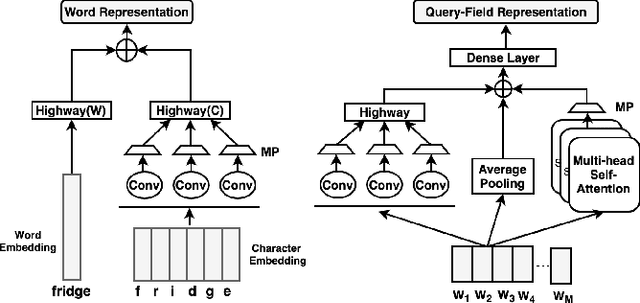
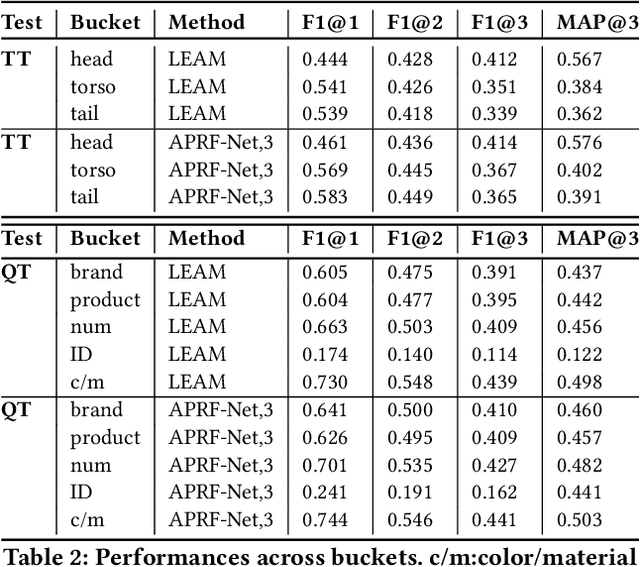
Query categorization is an essential part of query intent understanding in e-commerce search. A common query categorization task is to select the relevant fine-grained product categories in a product taxonomy. For frequent queries, rich customer behavior (e.g., click-through data) can be used to infer the relevant product categories. However, for more rare queries, which cover a large volume of search traffic, relying solely on customer behavior may not suffice due to the lack of this signal. To improve categorization of rare queries, we adapt the Pseudo-Relevance Feedback (PRF) approach to utilize the latent knowledge embedded in semantically or lexically similar product documents to enrich the representation of the more rare queries. To this end, we propose a novel deep neural model named Attentive Pseudo Relevance Feedback Network (APRF-Net) to enhance the representation of rare queries for query categorization. To demonstrate the effectiveness of our approach, we collect search queries from a large commercial search engine, and compare APRF-Net to state-of-the-art deep learning models for text classification. Our results show that the APRF-Net significantly improves query categorization by 5.9% on F1@1 score over the baselines, which increases to 8.2% improvement for the rare (tail) queries. The findings of this paper can be leveraged for further improvements in search query representation and understanding.
DeepCAT: Deep Category Representation for Query Understanding in E-commerce Search
May 10, 2021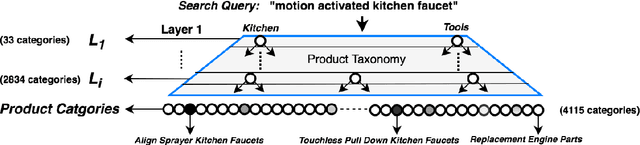
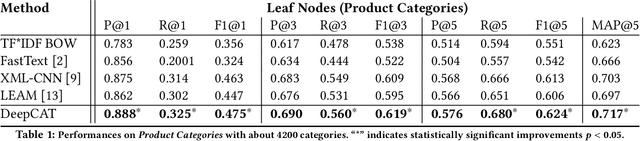
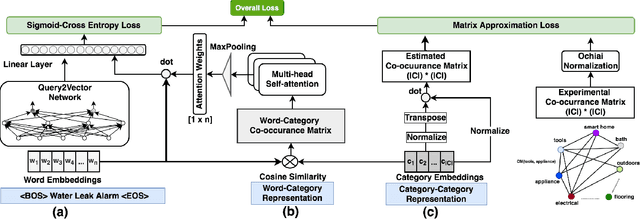
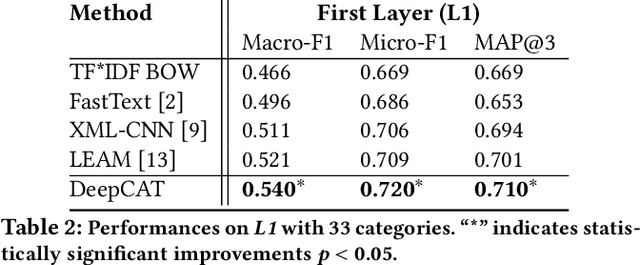
Mapping a search query to a set of relevant categories in the product taxonomy is a significant challenge in e-commerce search for two reasons: 1) Training data exhibits severe class imbalance problem due to biased click behavior, and 2) queries with little customer feedback (e.g., tail queries) are not well-represented in the training set, and cause difficulties for query understanding. To address these problems, we propose a deep learning model, DeepCAT, which learns joint word-category representations to enhance the query understanding process. We believe learning category interactions helps to improve the performance of category mapping on minority classes, tail and torso queries. DeepCAT contains a novel word-category representation model that trains the category representations based on word-category co-occurrences in the training set. The category representation is then leveraged to introduce a new loss function to estimate the category-category co-occurrences for refining joint word-category embeddings. To demonstrate our model's effectiveness on minority categories and tail queries, we conduct two sets of experiments. The results show that DeepCAT reaches a 10% improvement on minority classes and a 7.1% improvement on tail queries over a state-of-the-art label embedding model. Our findings suggest a promising direction for improving e-commerce search by semantic modeling of taxonomy hierarchies.