 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Adaptive Dense Retrieval for Brazilian Legal Search
May 05, 2026Brazilian legal retrieval is heterogeneous, covering case law, legislation, and question-based search. This makes training dense retrievers a trade-off between stronger domain specialization and broader robustness across retrieval types of search. In this paper, we explore this trade-off using three training setups based on Qwen3-Embedding-4B: a base model with no fine-tuning, a version trained only on legal data, and a mixed setup that combines legal data with SQuAD-pt supervised dataset. We evaluate these models on five legal datasets from the JUÁ leaderboard, along with Quati dataset as an extra Portuguese retrieval benchmark to test out-of-domain generalization. The legal-only model performs best on the most specialized legal tasks. The mixed setup keeps strong performance on legal data while offering a better overall balance, improving average NDCG@10 from 0.414 to 0.447, MRR@10 from 0.586 to 0.595, and MAP@10 from 0.270 to 0.308 across all six datasets. The biggest improvement appears on Quati, where the mixed model clearly outperforms the legal-only one. Overall, the results show that legal-only and mixed training lead to different strengths: the first is better for specialization, while the second is more robust across different types of search, especially question-based ones. Both adapted models are available on Hugging Face
JUÁ - A Benchmark for Information Retrieval in Brazilian Legal Text Collections
Apr 07, 2026Legal information retrieval in Portuguese remains difficult to evaluate systematically because available datasets differ widely in document type, query style, and relevance definition. We present \textsc{JUÁ}, a public benchmark for Brazilian legal retrieval designed to support more reproducible and comparable evaluation across heterogeneous legal collections. More broadly, \textsc{JUÁ} is intended not only as a benchmark, but as a continuous evaluation infrastructure for Brazilian legal IR, combining shared protocols, common ranking metrics, fixed splits when applicable, and a public leaderboard. The benchmark covers jurisprudence retrieval as well as broader legislative, regulatory, and question-driven legal search. We evaluate lexical, dense, and BM25-based reranking pipelines, including a domain-adapted Qwen embedding model fine-tuned on \textsc{JUÁ}-aligned supervision. Results show that the benchmark is sufficiently heterogeneous to distinguish retrieval paradigms and reveal substantial cross-dataset trade-offs. Domain adaptation yields its clearest gains on the supervision-aligned \textsc{JUÁ-Juris} subset, while BM25 remains highly competitive on other collections, especially in settings with strong lexical and institutional phrasing cues. Overall, \textsc{JUÁ} provides a practical evaluation framework for studying legal retrieval across multiple Brazilian legal domains under a common benchmark design.
Comparing Knowledge Injection Methods for LLMs in a Low-Resource Regime
Aug 08, 2025Large language models (LLMs) often require vast amounts of text to effectively acquire new knowledge. While continuing pre-training on large corpora or employing retrieval-augmented generation (RAG) has proven successful, updating an LLM with only a few thousand or million tokens remains challenging. In this work, we investigate the task of injecting small, unstructured information into LLMs and its relation to the catastrophic forgetting phenomenon. We use a dataset of recent news -- ensuring no overlap with the model's pre-training data -- to evaluate the knowledge acquisition by probing the model with question-answer pairs related the learned information. Starting from a continued pre-training baseline, we explored different augmentation algorithms to generate synthetic data to improve the knowledge acquisition capabilities. Our experiments show that simply continuing pre-training on limited data yields modest improvements, whereas exposing the model to diverse textual variations significantly improves the learning of new facts -- particularly with methods that induce greater variability through diverse prompting. Furthermore, we shed light on the forgetting phenomenon in small-data regimes, illustrating the delicate balance between learning new content and retaining existing capabilities. We also confirm the sensitivity of RAG-based approaches for knowledge injection, which often lead to greater degradation on control datasets compared to parametric methods. Finally, we demonstrate that models can generate effective synthetic training data themselves, suggesting a pathway toward self-improving model updates. All code and generated data used in our experiments are publicly available, providing a resource for studying efficient knowledge injection in LLMs with limited data at https://github.com/hugoabonizio/knowledge-injection-methods.
BR-TaxQA-R: A Dataset for Question Answering with References for Brazilian Personal Income Tax Law, including case law
May 21, 2025This paper presents BR-TaxQA-R, a novel dataset designed to support question answering with references in the context of Brazilian personal income tax law. The dataset contains 715 questions from the 2024 official Q\&A document published by Brazil's Internal Revenue Service, enriched with statutory norms and administrative rulings from the Conselho Administrativo de Recursos Fiscais (CARF). We implement a Retrieval-Augmented Generation (RAG) pipeline using OpenAI embeddings for searching and GPT-4o-mini for answer generation. We compare different text segmentation strategies and benchmark our system against commercial tools such as ChatGPT and Perplexity.ai using RAGAS-based metrics. Results show that our custom RAG pipeline outperforms commercial systems in Response Relevancy, indicating stronger alignment with user queries, while commercial models achieve higher scores in Factual Correctness and fluency. These findings highlight a trade-off between legally grounded generation and linguistic fluency. Crucially, we argue that human expert evaluation remains essential to ensure the legal validity of AI-generated answers in high-stakes domains such as taxation. BR-TaxQA-R is publicly available at https://huggingface.co/datasets/unicamp-dl/BR-TaxQA-R.
PublicHearingBR: A Brazilian Portuguese Dataset of Public Hearing Transcripts for Summarization of Long Documents
Oct 10, 2024This paper introduces PublicHearingBR, a Brazilian Portuguese dataset designed for summarizing long documents. The dataset consists of transcripts of public hearings held by the Brazilian Chamber of Deputies, paired with news articles and structured summaries containing the individuals participating in the hearing and their statements or opinions. The dataset supports the development and evaluation of long document summarization systems in Portuguese. Our contributions include the dataset, a hybrid summarization system to establish a baseline for future studies, and a discussion on evaluation metrics for summarization involving large language models, addressing the challenge of hallucination in the generated summaries. As a result of this discussion, the dataset also provides annotated data that can be used in Natural Language Inference tasks in Portuguese.
MLissard: Multilingual Long and Simple Sequential Reasoning Benchmarks
Oct 08, 2024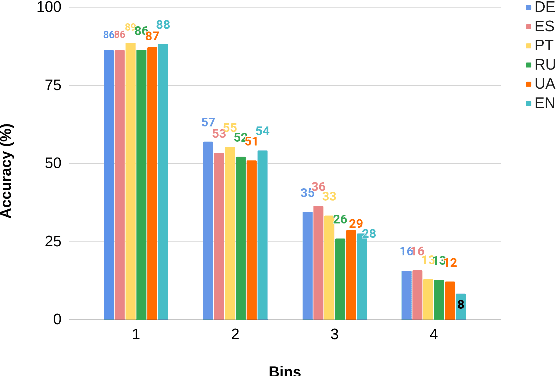

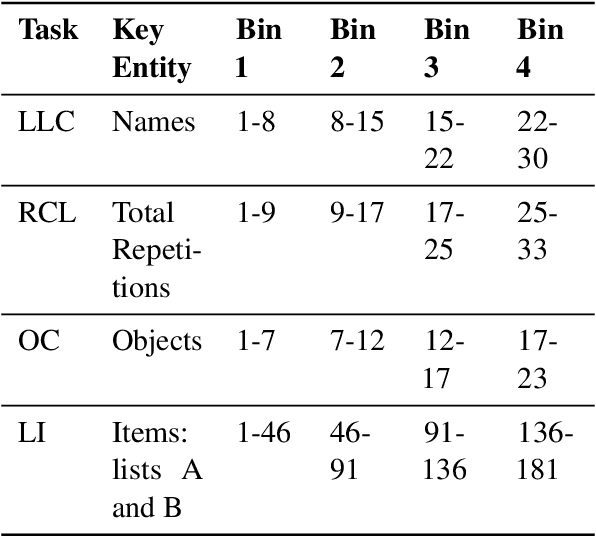
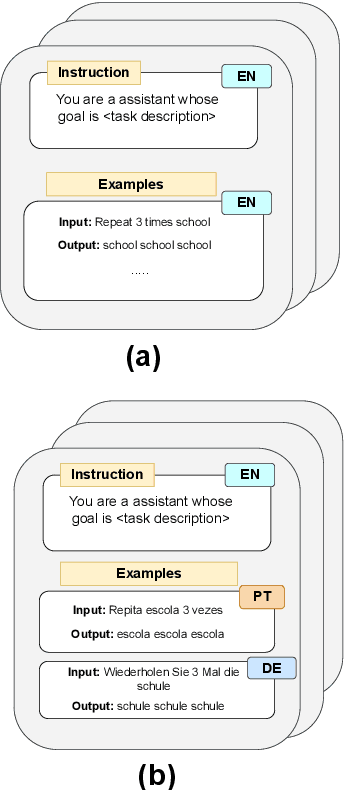
Language models are now capable of solving tasks that require dealing with long sequences consisting of hundreds of thousands of tokens. However, they often fail on tasks that require repetitive use of simple rules, even on sequences that are much shorter than those seen during training. For example, state-of-the-art LLMs can find common items in two lists with up to 20 items but fail when lists have 80 items. In this paper, we introduce MLissard, a multilingual benchmark designed to evaluate models' abilities to process and generate texts of varied lengths and offers a mechanism for controlling sequence complexity. Our evaluation of open-source and proprietary models show a consistent decline in performance across all models and languages as the complexity of the sequence increases. Surprisingly, the use of in-context examples in languages other than English helps increase extrapolation performance significantly. The datasets and code are available at https://github.com/unicamp-dl/Lissard
SurveySum: A Dataset for Summarizing Multiple Scientific Articles into a Survey Section
Aug 29, 2024



Document summarization is a task to shorten texts into concise and informative summaries. This paper introduces a novel dataset designed for summarizing multiple scientific articles into a section of a survey. Our contributions are: (1) SurveySum, a new dataset addressing the gap in domain-specific summarization tools; (2) two specific pipelines to summarize scientific articles into a section of a survey; and (3) the evaluation of these pipelines using multiple metrics to compare their performance. Our results highlight the importance of high-quality retrieval stages and the impact of different configurations on the quality of generated summaries.
Check-Eval: A Checklist-based Approach for Evaluating Text Quality
Jul 19, 2024



Evaluating the quality of text generated by large language models (LLMs) remains a significant challenge. Traditional metrics often fail to align well with human judgments, particularly in tasks requiring creativity and nuance. In this paper, we propose Check-Eval, a novel evaluation framework leveraging LLMs to assess the quality of generated text through a checklist-based approach. Check-Eval can be employed as both a reference-free and reference-dependent evaluation method, providing a structured and interpretable assessment of text quality. The framework consists of two main stages: checklist generation and checklist evaluation. We validate Check-Eval on two benchmark datasets: Portuguese Legal Semantic Textual Similarity and SummEval. Our results demonstrate that Check-Eval achieves higher correlations with human judgments compared to existing metrics, such as G-Eval and GPTScore, underscoring its potential as a more reliable and effective evaluation framework for natural language generation tasks. The code for our experiments is available at https://anonymous.4open.science/r/check-eval-0DB4.
ptt5-v2: A Closer Look at Continued Pretraining of T5 Models for the Portuguese Language
Jun 16, 2024Despite advancements in Natural Language Processing (NLP) and the growing availability of pretrained models, the English language remains the primary focus of model development. Continued pretraining on language-specific corpora provides a practical solution for adapting models to other languages. However, the impact of different pretraining settings on downstream tasks remains underexplored. This work introduces $\texttt{ptt5-v2}$, investigating the continued pretraining of T5 models for Portuguese. We first develop a baseline set of settings and pretrain models with sizes up to 3B parameters. Finetuning on three Portuguese downstream tasks (assin2 STS, assin2 RTE, and TweetSentBR) yields SOTA results on the latter two. We then explore the effects of different pretraining configurations, including quality filters, optimization strategies, and multi-epoch pretraining. Perhaps surprisingly, their impact remains subtle compared to our baseline. We release $\texttt{ptt5-v2}$ pretrained checkpoints and the finetuned MonoT5 rerankers on HuggingFace at https://huggingface.co/collections/unicamp-dl/ptt5-v2-666538a650188ba00aa8d2d0 and https://huggingface.co/collections/unicamp-dl/monoptt5-66653981877df3ea727f720d.
Measuring Cross-lingual Transfer in Bytes
Apr 12, 2024Multilingual pretraining has been a successful solution to the challenges posed by the lack of resources for languages. These models can transfer knowledge to target languages with minimal or no examples. Recent research suggests that monolingual models also have a similar capability, but the mechanisms behind this transfer remain unclear. Some studies have explored factors like language contamination and syntactic similarity. An emerging line of research suggests that the representations learned by language models contain two components: a language-specific and a language-agnostic component. The latter is responsible for transferring a more universal knowledge. However, there is a lack of comprehensive exploration of these properties across diverse target languages. To investigate this hypothesis, we conducted an experiment inspired by the work on the Scaling Laws for Transfer. We measured the amount of data transferred from a source language to a target language and found that models initialized from diverse languages perform similarly to a target language in a cross-lingual setting. This was surprising because the amount of data transferred to 10 diverse target languages, such as Spanish, Korean, and Finnish, was quite similar. We also found evidence that this transfer is not related to language contamination or language proximity, which strengthens the hypothesis that the model also relies on language-agnostic knowledge. Our experiments have opened up new possibilities for measuring how much data represents the language-agnostic representations learned during pretraining.