 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Cross-lingual Transfer in Bytes
Apr 12, 2024Multilingual pretraining has been a successful solution to the challenges posed by the lack of resources for languages. These models can transfer knowledge to target languages with minimal or no examples. Recent research suggests that monolingual models also have a similar capability, but the mechanisms behind this transfer remain unclear. Some studies have explored factors like language contamination and syntactic similarity. An emerging line of research suggests that the representations learned by language models contain two components: a language-specific and a language-agnostic component. The latter is responsible for transferring a more universal knowledge. However, there is a lack of comprehensive exploration of these properties across diverse target languages. To investigate this hypothesis, we conducted an experiment inspired by the work on the Scaling Laws for Transfer. We measured the amount of data transferred from a source language to a target language and found that models initialized from diverse languages perform similarly to a target language in a cross-lingual setting. This was surprising because the amount of data transferred to 10 diverse target languages, such as Spanish, Korean, and Finnish, was quite similar. We also found evidence that this transfer is not related to language contamination or language proximity, which strengthens the hypothesis that the model also relies on language-agnostic knowledge. Our experiments have opened up new possibilities for measuring how much data represents the language-agnostic representations learned during pretraining.
MonoByte: A Pool of Monolingual Byte-level Language Models
Sep 27, 2022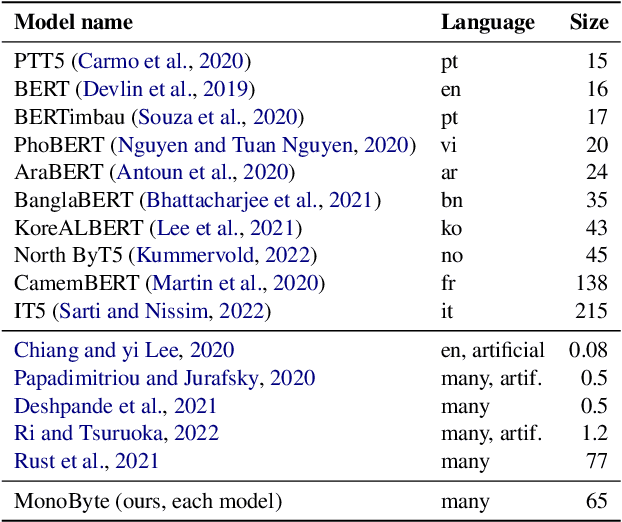
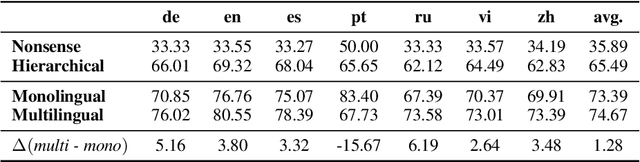
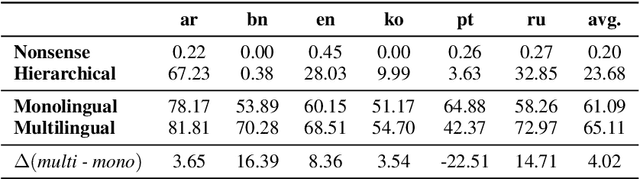
The zero-shot cross-lingual ability of models pretrained on multilingual and even monolingual corpora has spurred many hypotheses to explain this intriguing empirical result. However, due to the costs of pretraining, most research uses public models whose pretraining methodology, such as the choice of tokenization, corpus size, and computational budget, might differ drastically. When researchers pretrain their own models, they often do so under a constrained budget, and the resulting models might underperform significantly compared to SOTA models. These experimental differences led to various inconsistent conclusions about the nature of the cross-lingual ability of these models. To help further research on the topic, we released 10 monolingual byte-level models rigorously pretrained under the same configuration with a large compute budget (equivalent to 420 days on a V100) and corpora that are 4 times larger than the original BERT's. Because they are tokenizer-free, the problem of unseen token embeddings is eliminated, thus allowing researchers to try a wider range of cross-lingual experiments in languages with different scripts. Additionally, we release two models pretrained on non-natural language texts that can be used in sanity-check experiments. Experiments on QA and NLI tasks show that our monolingual models achieve competitive performance to the multilingual one, and hence can be served to strengthen our understanding of cross-lingual transferability in language models.
On the ability of monolingual models to learn language-agnostic representations
Sep 04, 2021
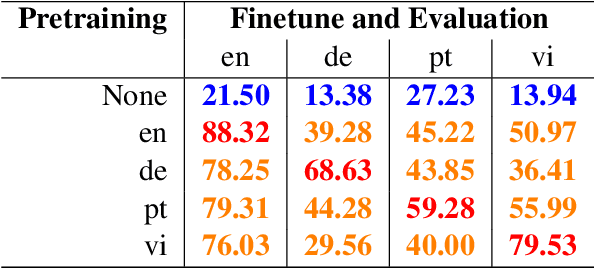
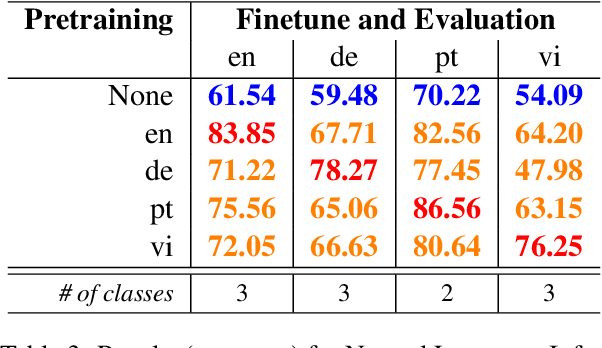
Pretrained multilingual models have become a de facto default approach for zero-shot cross-lingual transfer. Previous work has shown that these models are able to achieve cross-lingual representations when pretrained on two or more languages with shared parameters. In this work, we provide evidence that a model can achieve language-agnostic representations even when pretrained on a single language. That is, we find that monolingual models pretrained and finetuned on different languages achieve competitive performance compared to the ones that use the same target language. Surprisingly, the models show a similar performance on a same task regardless of the pretraining language. For example, models pretrained on distant languages such as German and Portuguese perform similarly on English tasks.
A cost-benefit analysis of cross-lingual transfer methods
May 29, 2021
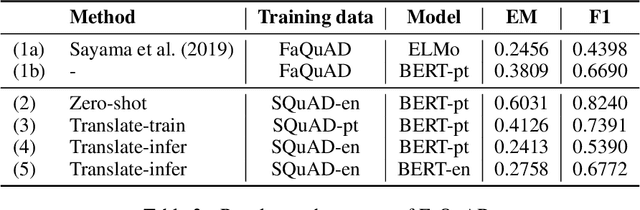
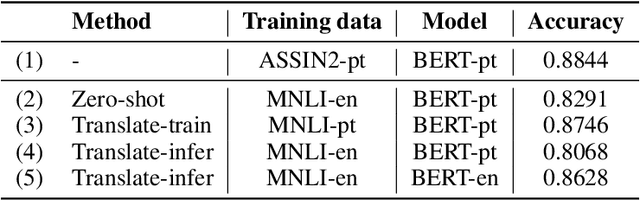
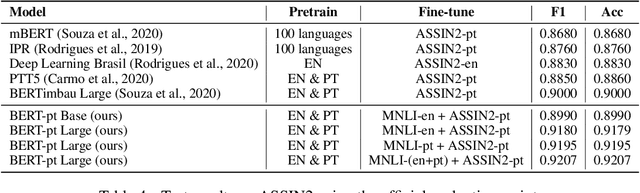
An effective method for cross-lingual transfer is to fine-tune a bilingual or multilingual model on a supervised dataset in one language and evaluating it on another language in a zero-shot manner. Translating examples at training time or inference time are also viable alternatives. However, there are costs associated with these methods that are rarely addressed in the literature. In this work, we analyze cross-lingual methods in terms of their effectiveness (e.g., accuracy), development and deployment costs, as well as their latencies at inference time. Our experiments on three tasks indicate that the best cross-lingual method is highly task-dependent. Finally, by combining zero-shot and translation methods, we achieve the state-of-the-art in two of the three datasets used in this work. Based on these results, we question the need for manually labeled training data in a target language. Code, models and translated datasets are available at https://github.com/unicamp-dl/cross-lingual-analysis