 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Parameter Left Behind: How Distillation and Model Size Affect Zero-Shot Retrieval
Jun 06, 2022



Recent work has shown that small distilled language models are strong competitors to models that are orders of magnitude larger and slower in a wide range of information retrieval tasks. This has made distilled and dense models, due to latency constraints, the go-to choice for deployment in real-world retrieval applications. In this work, we question this practice by showing that the number of parameters and early query-document interaction play a significant role in the generalization ability of retrieval models. Our experiments show that increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning. Furthermore, we show that rerankers largely outperform dense ones of similar size in several tasks. Our largest reranker reaches the state of the art in 12 of the 18 datasets of the Benchmark-IR (BEIR) and surpasses the previous state of the art by 3 average points. Finally, we confirm that in-domain effectiveness is not a good indicator of zero-shot effectiveness. Code is available at https://github.com/guilhermemr04/scaling-zero-shot-retrieval.git
Billions of Parameters Are Worth More Than In-domain Training Data: A case study in the Legal Case Entailment Task
May 30, 2022
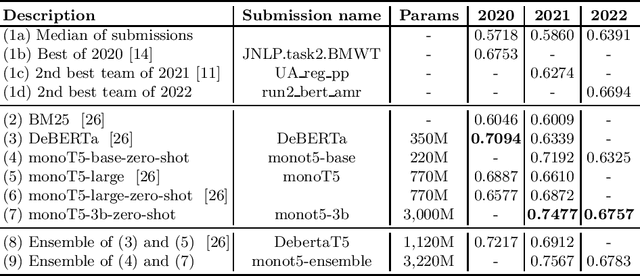
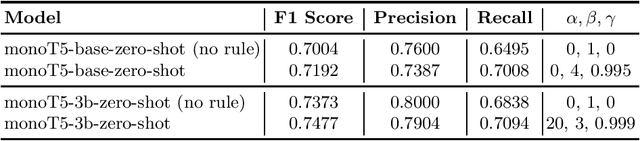
Recent work has shown that language models scaled to billions of parameters, such as GPT-3, perform remarkably well in zero-shot and few-shot scenarios. In this work, we experiment with zero-shot models in the legal case entailment task of the COLIEE 2022 competition. Our experiments show that scaling the number of parameters in a language model improves the F1 score of our previous zero-shot result by more than 6 points, suggesting that stronger zero-shot capability may be a characteristic of larger models, at least for this task. Our 3B-parameter zero-shot model outperforms all models, including ensembles, in the COLIEE 2021 test set and also achieves the best performance of a single model in the COLIEE 2022 competition, second only to the ensemble composed of the 3B model itself and a smaller version of the same model. Despite the challenges posed by large language models, mainly due to latency constraints in real-time applications, we provide a demonstration of our zero-shot monoT5-3b model being used in production as a search engine, including for legal documents. The code for our submission and the demo of our system are available at https://github.com/neuralmind-ai/coliee and https://neuralsearchx.neuralmind.ai, respectively.
To Tune or Not To Tune? Zero-shot Models for Legal Case Entailment
Feb 07, 2022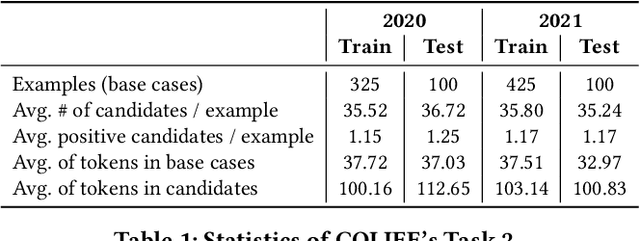
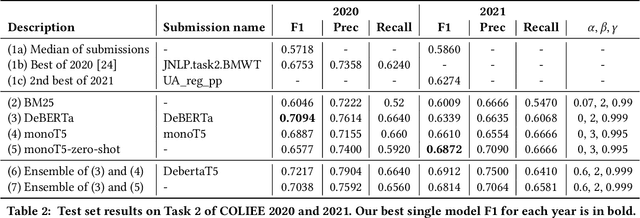
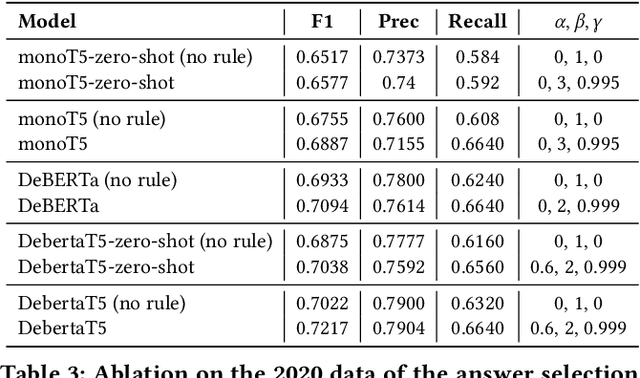
There has been mounting evidence that pretrained language models fine-tuned on large and diverse supervised datasets can transfer well to a variety of out-of-domain tasks. In this work, we investigate this transfer ability to the legal domain. For that, we participated in the legal case entailment task of COLIEE 2021, in which we use such models with no adaptations to the target domain. Our submissions achieved the highest scores, surpassing the second-best team by more than six percentage points. Our experiments confirm a counter-intuitive result in the new paradigm of pretrained language models: given limited labeled data, models with little or no adaptation to the target task can be more robust to changes in the data distribution than models fine-tuned on it. Code is available at https://github.com/neuralmind-ai/coliee.
A cost-benefit analysis of cross-lingual transfer methods
May 29, 2021
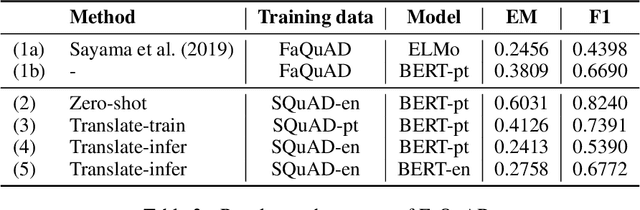
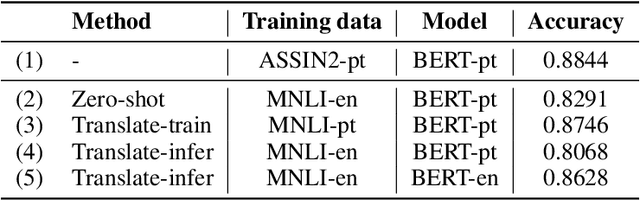
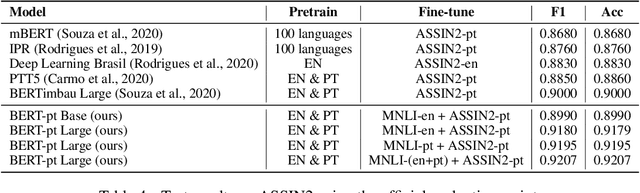
An effective method for cross-lingual transfer is to fine-tune a bilingual or multilingual model on a supervised dataset in one language and evaluating it on another language in a zero-shot manner. Translating examples at training time or inference time are also viable alternatives. However, there are costs associated with these methods that are rarely addressed in the literature. In this work, we analyze cross-lingual methods in terms of their effectiveness (e.g., accuracy), development and deployment costs, as well as their latencies at inference time. Our experiments on three tasks indicate that the best cross-lingual method is highly task-dependent. Finally, by combining zero-shot and translation methods, we achieve the state-of-the-art in two of the three datasets used in this work. Based on these results, we question the need for manually labeled training data in a target language. Code, models and translated datasets are available at https://github.com/unicamp-dl/cross-lingual-analysis
Yes, BM25 is a Strong Baseline for Legal Case Retrieval
Apr 26, 2021

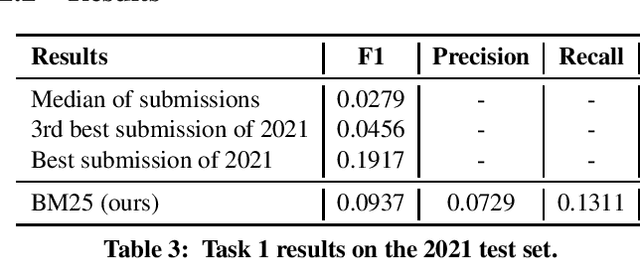
We describe our single submission to task 1 of COLIEE 2021. Our vanilla BM25 got second place, well above the median of submissions. Code is available at https://github.com/neuralmind-ai/coliee.