 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Neural Retrieval Models on the Touché 2020 Argument Retrieval Subset of BEIR
Jul 10, 2024



The zero-shot effectiveness of neural retrieval models is often evaluated on the BEIR benchmark -- a combination of different IR evaluation datasets. Interestingly, previous studies found that particularly on the BEIR subset Touch\'e 2020, an argument retrieval task, neural retrieval models are considerably less effective than BM25. Still, so far, no further investigation has been conducted on what makes argument retrieval so "special". To more deeply analyze the respective potential limits of neural retrieval models, we run a reproducibility study on the Touch\'e 2020 data. In our study, we focus on two experiments: (i) a black-box evaluation (i.e., no model retraining), incorporating a theoretical exploration using retrieval axioms, and (ii) a data denoising evaluation involving post-hoc relevance judgments. Our black-box evaluation reveals an inherent bias of neural models towards retrieving short passages from the Touch\'e 2020 data, and we also find that quite a few of the neural models' results are unjudged in the Touch\'e 2020 data. As many of the short Touch\'e passages are not argumentative and thus non-relevant per se, and as the missing judgments complicate fair comparison, we denoise the Touch\'e 2020 data by excluding very short passages (less than 20 words) and by augmenting the unjudged data with post-hoc judgments following the Touch\'e guidelines. On the denoised data, the effectiveness of the neural models improves by up to 0.52 in nDCG@10, but BM25 is still more effective. Our code and the augmented Touch\'e 2020 dataset are available at \url{https://github.com/castorini/touche-error-analysis}.
NoMIRACL: Knowing When You Don't Know for Robust Multilingual Retrieval-Augmented Generation
Dec 18, 2023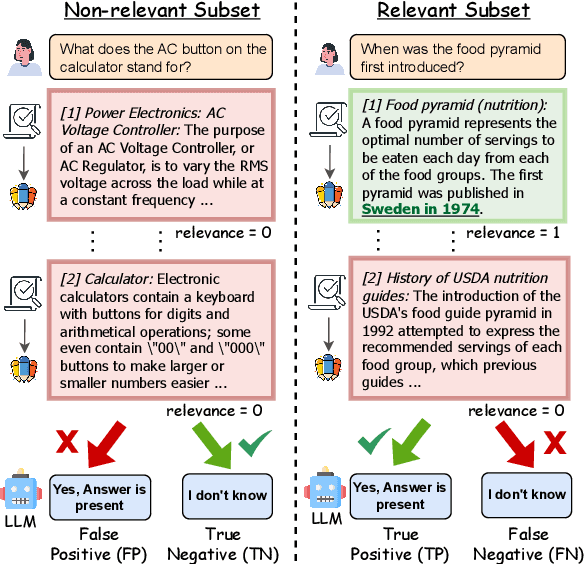

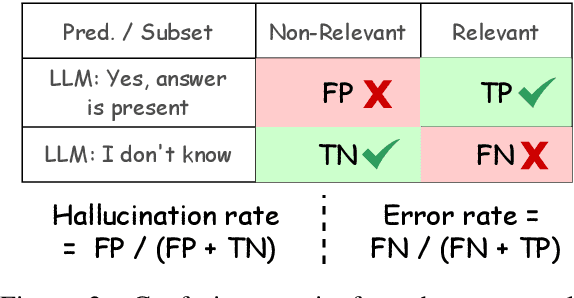
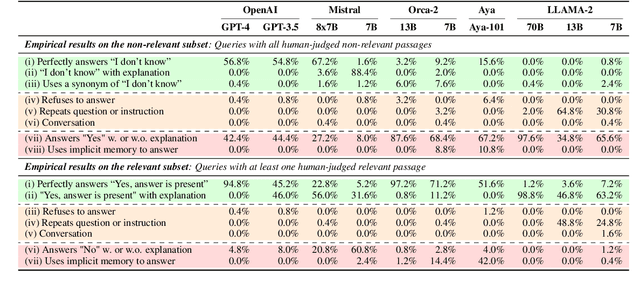
Retrieval-augmented generation (RAG) grounds large language model (LLM) output by leveraging external knowledge sources to reduce factual hallucinations. However, prior works lack a comprehensive evaluation of different language families, making it challenging to evaluate LLM robustness against errors in external retrieved knowledge. To overcome this, we establish NoMIRACL, a human-annotated dataset for evaluating LLM robustness in RAG across 18 typologically diverse languages. NoMIRACL includes both a non-relevant and a relevant subset. Queries in the non-relevant subset contain passages manually judged as non-relevant or noisy, whereas queries in the relevant subset include at least a single judged relevant passage. We measure LLM robustness using two metrics: (i) hallucination rate, measuring model tendency to hallucinate an answer, when the answer is not present in passages in the non-relevant subset, and (ii) error rate, measuring model inaccuracy to recognize relevant passages in the relevant subset. We build a GPT-4 baseline which achieves a 33.2% hallucination rate on the non-relevant and a 14.9% error rate on the relevant subset on average. Our evaluation reveals that GPT-4 hallucinates frequently in high-resource languages, such as French or English. This work highlights an important avenue for future research to improve LLM robustness to learn how to better reject non-relevant information in RAG.
InPars Toolkit: A Unified and Reproducible Synthetic Data Generation Pipeline for Neural Information Retrieval
Jul 10, 2023Recent work has explored Large Language Models (LLMs) to overcome the lack of training data for Information Retrieval (IR) tasks. The generalization abilities of these models have enabled the creation of synthetic in-domain data by providing instructions and a few examples on a prompt. InPars and Promptagator have pioneered this approach and both methods have demonstrated the potential of using LLMs as synthetic data generators for IR tasks. This makes them an attractive solution for IR tasks that suffer from a lack of annotated data. However, the reproducibility of these methods was limited, because InPars' training scripts are based on TPUs -- which are not widely accessible -- and because the code for Promptagator was not released and its proprietary LLM is not publicly accessible. To fully realize the potential of these methods and make their impact more widespread in the research community, the resources need to be accessible and easy to reproduce by researchers and practitioners. Our main contribution is a unified toolkit for end-to-end reproducible synthetic data generation research, which includes generation, filtering, training and evaluation. Additionally, we provide an interface to IR libraries widely used by the community and support for GPU. Our toolkit not only reproduces the InPars method and partially reproduces Promptagator, but also provides a plug-and-play functionality allowing the use of different LLMs, exploring filtering methods and finetuning various reranker models on the generated data. We also made available all the synthetic data generated in this work for the 18 different datasets in the BEIR benchmark which took more than 2,000 GPU hours to be generated as well as the reranker models finetuned on the synthetic data. Code and data are available at https://github.com/zetaalphavector/InPars
InPars-v2: Large Language Models as Efficient Dataset Generators for Information Retrieval
Jan 14, 2023Recently, InPars introduced a method to efficiently use large language models (LLMs) in information retrieval tasks: via few-shot examples, an LLM is induced to generate relevant queries for documents. These synthetic query-document pairs can then be used to train a retriever. However, InPars and, more recently, Promptagator, rely on proprietary LLMs such as GPT-3 and FLAN to generate such datasets. In this work we introduce InPars-v2, a dataset generator that uses open-source LLMs and existing powerful rerankers to select synthetic query-document pairs for training. A simple BM25 retrieval pipeline followed by a monoT5 reranker finetuned on InPars-v2 data achieves new state-of-the-art results on the BEIR benchmark. To allow researchers to further improve our method, we open source the code, synthetic data, and finetuned models: https://github.com/zetaalphavector/inPars/tree/master/tpu
In Defense of Cross-Encoders for Zero-Shot Retrieval
Dec 12, 2022Bi-encoders and cross-encoders are widely used in many state-of-the-art retrieval pipelines. In this work we study the generalization ability of these two types of architectures on a wide range of parameter count on both in-domain and out-of-domain scenarios. We find that the number of parameters and early query-document interactions of cross-encoders play a significant role in the generalization ability of retrieval models. Our experiments show that increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning. Furthermore, we show that cross-encoders largely outperform bi-encoders of similar size in several tasks. In the BEIR benchmark, our largest cross-encoder surpasses a state-of-the-art bi-encoder by more than 4 average points. Finally, we show that using bi-encoders as first-stage retrievers provides no gains in comparison to a simpler retriever such as BM25 on out-of-domain tasks. The code is available at https://github.com/guilhermemr04/scaling-zero-shot-retrieval.git
No Parameter Left Behind: How Distillation and Model Size Affect Zero-Shot Retrieval
Jun 06, 2022



Recent work has shown that small distilled language models are strong competitors to models that are orders of magnitude larger and slower in a wide range of information retrieval tasks. This has made distilled and dense models, due to latency constraints, the go-to choice for deployment in real-world retrieval applications. In this work, we question this practice by showing that the number of parameters and early query-document interaction play a significant role in the generalization ability of retrieval models. Our experiments show that increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning. Furthermore, we show that rerankers largely outperform dense ones of similar size in several tasks. Our largest reranker reaches the state of the art in 12 of the 18 datasets of the Benchmark-IR (BEIR) and surpasses the previous state of the art by 3 average points. Finally, we confirm that in-domain effectiveness is not a good indicator of zero-shot effectiveness. Code is available at https://github.com/guilhermemr04/scaling-zero-shot-retrieval.git
Billions of Parameters Are Worth More Than In-domain Training Data: A case study in the Legal Case Entailment Task
May 30, 2022
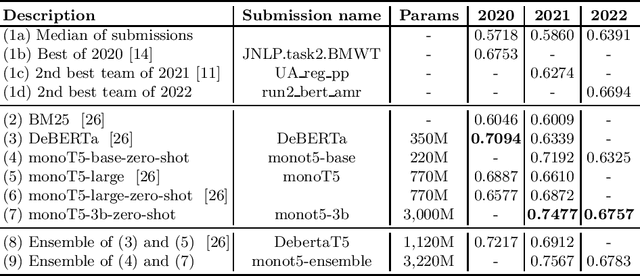
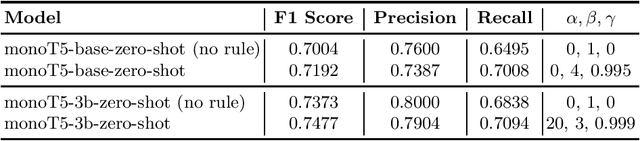
Recent work has shown that language models scaled to billions of parameters, such as GPT-3, perform remarkably well in zero-shot and few-shot scenarios. In this work, we experiment with zero-shot models in the legal case entailment task of the COLIEE 2022 competition. Our experiments show that scaling the number of parameters in a language model improves the F1 score of our previous zero-shot result by more than 6 points, suggesting that stronger zero-shot capability may be a characteristic of larger models, at least for this task. Our 3B-parameter zero-shot model outperforms all models, including ensembles, in the COLIEE 2021 test set and also achieves the best performance of a single model in the COLIEE 2022 competition, second only to the ensemble composed of the 3B model itself and a smaller version of the same model. Despite the challenges posed by large language models, mainly due to latency constraints in real-time applications, we provide a demonstration of our zero-shot monoT5-3b model being used in production as a search engine, including for legal documents. The code for our submission and the demo of our system are available at https://github.com/neuralmind-ai/coliee and https://neuralsearchx.neuralmind.ai, respectively.
InPars: Data Augmentation for Information Retrieval using Large Language Models
Feb 10, 2022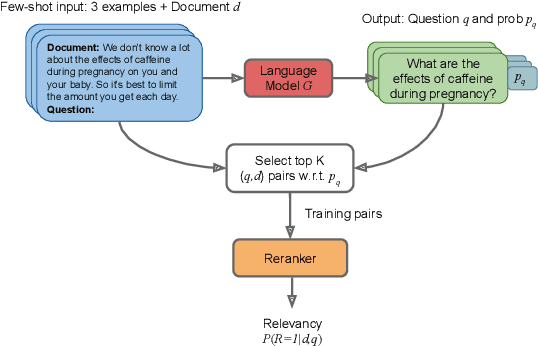



The information retrieval community has recently witnessed a revolution due to large pretrained transformer models. Another key ingredient for this revolution was the MS MARCO dataset, whose scale and diversity has enabled zero-shot transfer learning to various tasks. However, not all IR tasks and domains can benefit from one single dataset equally. Extensive research in various NLP tasks has shown that using domain-specific training data, as opposed to a general-purpose one, improves the performance of neural models. In this work, we harness the few-shot capabilities of large pretrained language models as synthetic data generators for IR tasks. We show that models finetuned solely on our unsupervised dataset outperform strong baselines such as BM25 as well as recently proposed self-supervised dense retrieval methods. Furthermore, retrievers finetuned on both supervised and our synthetic data achieve better zero-shot transfer than models finetuned only on supervised data. Code, models, and data are available at https://github.com/zetaalphavector/inpars .