 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARCA: A Checklist-Based Benchmark for Multilingual Web Search
Apr 15, 2026Large language models (LLMs) are increasingly used as sources of information, yet their reliability depends on the ability to search the web, select relevant evidence, and synthesize complete answers. While recent benchmarks evaluate web-browsing and agentic tool use, multilingual settings, and Portuguese in particular, remain underexplored. We present \textsc{MARCA}, a bilingual (English and Portuguese) benchmark for evaluating LLMs on web-based information seeking. \textsc{MARCA} consists of 52 manually authored multi-entity questions, paired with manually validated checklist-style rubrics that explicitly measure answer completeness and correctness. We evaluate 14 models under two interaction settings: a Basic framework with direct web search and scraping, and an Orchestrator framework that enables task decomposition via delegated subagents. To capture stochasticity, each question is executed multiple times and performance is reported with run-level uncertainty. Across models, we observe large performance differences, find that orchestration often improves coverage, and identify substantial variability in how models transfer from English to Portuguese. The benchmark is available at https://github.com/maritaca-ai/MARCA
Synthetic Rewriting as a Quality Multiplier: Evidence from Portuguese Continued Pretraining
Mar 25, 2026Synthetic data generation through document rewriting has emerged as a promising technique for improving language model pretraining, yet most studies focus on English and do not systematically control for the quality of the source data being rewritten. We present a controlled study of how synthetic rewriting interacts with source data quality in the context of Portuguese continued pretraining. Starting from ClassiCC-PT, a Portuguese corpus annotated with STEM and Educational quality scores, we construct two 10B-token subsets at different quality levels and rewrite each into four styles using a 7B instruction-tuned model, producing approximately 40B tokens of synthetic data per condition. We train two English-centric base models (1.1B and 7B parameters) on each condition and evaluate on PoETa V2, a comprehensive 44-task Portuguese benchmark. At the 7B scale, rewriting high-quality data yields a +3.4 NPM gain over the same data unmodified, while rewriting low-quality data provides only +0.5 NPM. At the 1.1B scale, this interaction is weaker, with unmodified low-quality data performing comparably to rewritten high-quality data. Our results demonstrate that synthetic rewriting acts primarily as a quality multiplier rather than a substitute for data curation, and that this effect is scale-dependent.
CAPITU: A Benchmark for Evaluating Instruction-Following in Brazilian Portuguese with Literary Context
Mar 23, 2026We introduce CAPITU, a benchmark for evaluating instruction-following capabilities of Large Language Models (LLMs) in Brazilian Portuguese. Unlike existing benchmarks that focus on English or use generic prompts, CAPITU contextualizes all tasks within eight canonical works of Brazilian literature, combining verifiable instruction constraints with culturally-grounded content. The benchmark comprises 59 instruction types organized into seven categories, all designed to be automatically verifiable without requiring LLM judges or human evaluation. Instruction types include Portuguese-specific linguistic constraints (word termination patterns like -ando/-endo/-indo, -inho/-inha, -mente) and structural requirements. We evaluate 18 state-of-the-art models across single-turn and multi-turn settings. Our results show that frontier reasoning models achieve strong performance (GPT-5.2 with reasoning: 98.5% strict accuracy), while Portuguese-specialized models offer competitive cost-efficiency (Sabiazinho-4: 87.0% at \$0.13 vs Claude-Haiku-4.5: 73.5% at \$1.12). Multi-turn evaluation reveals significant variation in constraint persistence, with conversation-level accuracy ranging from 60% to 96% across models. We identify specific challenges in morphological constraints, exact counting, and constraint persistence degradation across turns. We release the complete benchmark, evaluation code, and baseline results to facilitate research on instruction-following in Portuguese.
Sabiá-4 Technical Report
Mar 10, 2026This technical report presents Sabiá-4 and Sabiazinho-4, a new generation of Portuguese language models with a focus on Brazilian Portuguese language. The models were developed through a four-stage training pipeline: continued pre-training on Portuguese and Brazilian legal corpora, long-context extension to 128K tokens, supervised fine-tuning on instruction data spanning chat, code, legal tasks, and function calling, and preference alignment. We evaluate the models on six benchmark categories: conversational capabilities in Brazilian Portuguese, knowledge of Brazilian legislation, long-context understanding, instruction following, standardized exams, and agentic capabilities including tool use and web navigation. Results show that Sabiá-4 and Sabiazinho-4 achieve a favorable cost-performance trade-off compared to other models, positioning them in the upper-left region of the pricing-accuracy chart. The models show improvements over previous generations in legal document drafting, multi-turn dialogue quality, and agentic task completion.
Curió-Edu 7B: Examining Data Selection Impacts in LLM Continued Pretraining
Dec 14, 2025Continued pretraining extends a language model's capabilities by further exposing it to additional data, often tailored to a specific linguistic or domain context. This strategy has emerged as an efficient alternative to full retraining when adapting general-purpose models to new settings. In this work, we investigate this paradigm through Curió 7B, a 7-billion-parameter model derived from LLaMA-2 and trained on 100 billion Portuguese tokens from the ClassiCC-PT corpus - the most extensive Portuguese-specific continued-pretraining effort above the three-billion-parameter scale to date. Beyond scale, we investigate whether quantity alone suffices or whether data quality plays a decisive role in linguistic adaptation. To this end, we introduce Curió-Edu 7B, a variant trained exclusively on the educational and STEM-filtered subset of the same corpus, totaling just 10 billion tokens. Despite using only 10% of the data and 20% of the computation, Curió-Edu 7B surpasses the full-corpus model in our evaluations, demonstrating that data selection can be fundamental even when adapting models with limited prior exposure to the target language. The developed models are available at https://huggingface.co/collections/ClassiCC-Corpus/curio-edu
Building High-Quality Datasets for Portuguese LLMs: From Common Crawl Snapshots to Industrial-Grade Corpora
Sep 10, 2025The performance of large language models (LLMs) is deeply influenced by the quality and composition of their training data. While much of the existing work has centered on English, there remains a gap in understanding how to construct effective training corpora for other languages. We explore scalable methods for building web-based corpora for LLMs. We apply them to build a new 120B token corpus in Portuguese that achieves competitive results to an industrial-grade corpus. Using a continual pretraining setup, we study how different data selection and preprocessing strategies affect LLM performance when transitioning a model originally trained in English to another language. Our findings demonstrate the value of language-specific filtering pipelines, including classifiers for education, science, technology, engineering, and mathematics (STEM), as well as toxic content. We show that adapting a model to the target language leads to performance improvements, reinforcing the importance of high-quality, language-specific data. While our case study focuses on Portuguese, our methods are applicable to other languages, offering insights for multilingual LLM development.
Comparing Knowledge Injection Methods for LLMs in a Low-Resource Regime
Aug 08, 2025Large language models (LLMs) often require vast amounts of text to effectively acquire new knowledge. While continuing pre-training on large corpora or employing retrieval-augmented generation (RAG) has proven successful, updating an LLM with only a few thousand or million tokens remains challenging. In this work, we investigate the task of injecting small, unstructured information into LLMs and its relation to the catastrophic forgetting phenomenon. We use a dataset of recent news -- ensuring no overlap with the model's pre-training data -- to evaluate the knowledge acquisition by probing the model with question-answer pairs related the learned information. Starting from a continued pre-training baseline, we explored different augmentation algorithms to generate synthetic data to improve the knowledge acquisition capabilities. Our experiments show that simply continuing pre-training on limited data yields modest improvements, whereas exposing the model to diverse textual variations significantly improves the learning of new facts -- particularly with methods that induce greater variability through diverse prompting. Furthermore, we shed light on the forgetting phenomenon in small-data regimes, illustrating the delicate balance between learning new content and retaining existing capabilities. We also confirm the sensitivity of RAG-based approaches for knowledge injection, which often lead to greater degradation on control datasets compared to parametric methods. Finally, we demonstrate that models can generate effective synthetic training data themselves, suggesting a pathway toward self-improving model updates. All code and generated data used in our experiments are publicly available, providing a resource for studying efficient knowledge injection in LLMs with limited data at https://github.com/hugoabonizio/knowledge-injection-methods.
Automatic Legal Writing Evaluation of LLMs
Apr 29, 2025Despite the recent advances in Large Language Models, benchmarks for evaluating legal writing remain scarce due to the inherent complexity of assessing open-ended responses in this domain. One of the key challenges in evaluating language models on domain-specific tasks is finding test datasets that are public, frequently updated, and contain comprehensive evaluation guidelines. The Brazilian Bar Examination meets these requirements. We introduce oab-bench, a benchmark comprising 105 questions across seven areas of law from recent editions of the exam. The benchmark includes comprehensive evaluation guidelines and reference materials used by human examiners to ensure consistent grading. We evaluate the performance of four LLMs on oab-bench, finding that Claude-3.5 Sonnet achieves the best results with an average score of 7.93 out of 10, passing all 21 exams. We also investigated whether LLMs can serve as reliable automated judges for evaluating legal writing. Our experiments show that frontier models like OpenAI's o1 achieve a strong correlation with human scores when evaluating approved exams, suggesting their potential as reliable automated evaluators despite the inherently subjective nature of legal writing assessment. The source code and the benchmark -- containing questions, evaluation guidelines, model-generated responses, and their respective automated evaluations -- are publicly available.
TiEBe: A Benchmark for Assessing the Current Knowledge of Large Language Models
Jan 13, 2025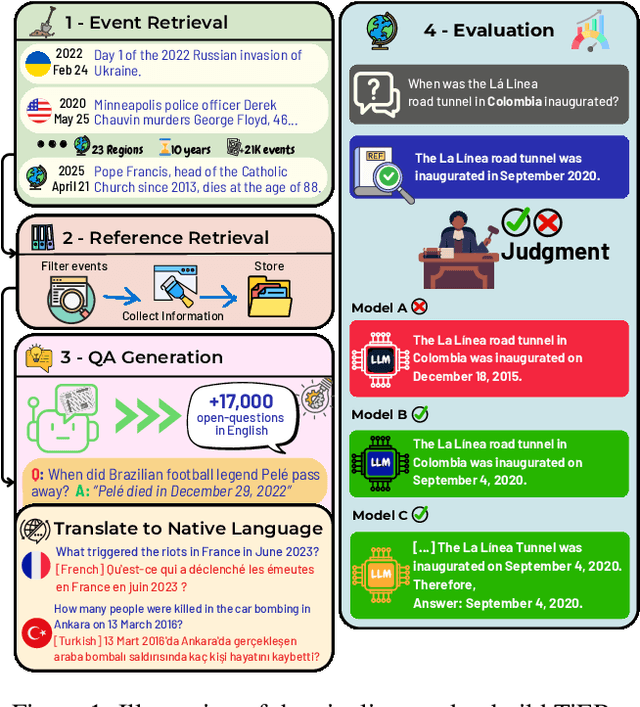
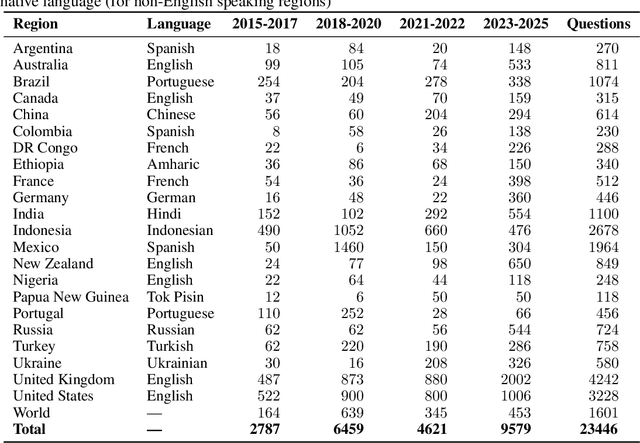

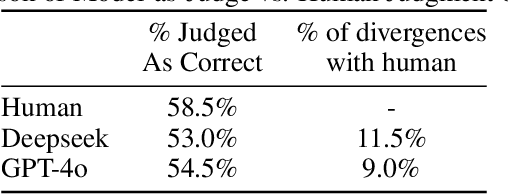
In a rapidly evolving knowledge landscape and the increasing adoption of large language models, a need has emerged to keep these models continuously updated with current events. While existing benchmarks evaluate general factual recall, they often overlook two critical aspects: the ability of models to integrate evolving knowledge through continual learning and the significant regional disparities in their performance. To address these gaps, we introduce the Timely Events Benchmark (TiEBe), a dataset containing over 11,000 question-answer pairs focused on globally and regionally significant events. TiEBe leverages structured retrospective data from Wikipedia, enabling continuous updates to assess LLMs' knowledge of evolving global affairs and their understanding of events across different regions. Our benchmark demonstrates that LLMs exhibit substantial geographic disparities in factual recall, emphasizing the need for more balanced global knowledge representation. Furthermore, TiEBe serves as a tool for evaluating continual learning strategies, providing insights into models' ability to acquire new information without forgetting past knowledge.
The interplay between domain specialization and model size: a case study in the legal domain
Jan 03, 2025Scaling laws for language models so far focused on finding the compute-optimal model size and token count for training from scratch. However, achieving this optimal balance requires significant compute resources due to the extensive data demands when training models from randomly-initialized weights. Continual pre-training offers a cost-effective alternative, leveraging the compute investment from pre-trained models to incorporate new knowledge without requiring extensive new data. Recent findings suggest that data quality influences constants in scaling laws, thereby altering the optimal parameter-token allocation ratio. Building on this insight, we investigate the interplay between domain specialization and model size during continual pre-training under compute-constrained scenarios. Our goal is to identify a compute-efficient training regime for this scenario and, potentially, detect patterns in this interplay that can be generalized across different model sizes and domains. To compare general and specialized training, we filtered a web-based dataset to extract legal domain data. We pre-trained models with 1.5B, 3B, 7B and 14B parameters on both the unfiltered and filtered datasets, then evaluated their performance on legal exams. Results show that as model size increases, the compute-effectiveness gap between specialized and general models widens.