 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLissard: Multilingual Long and Simple Sequential Reasoning Benchmarks
Oct 08, 2024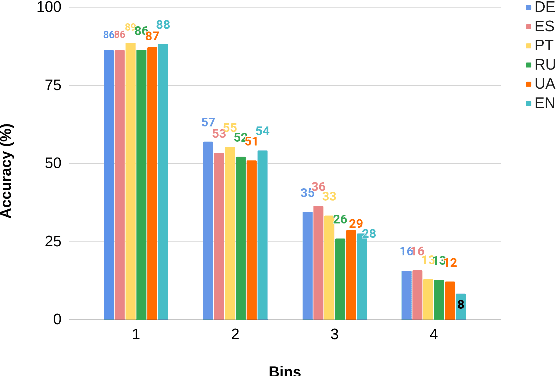

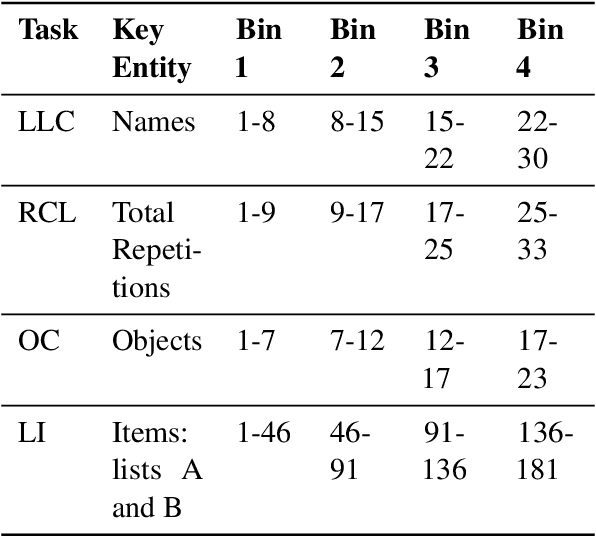
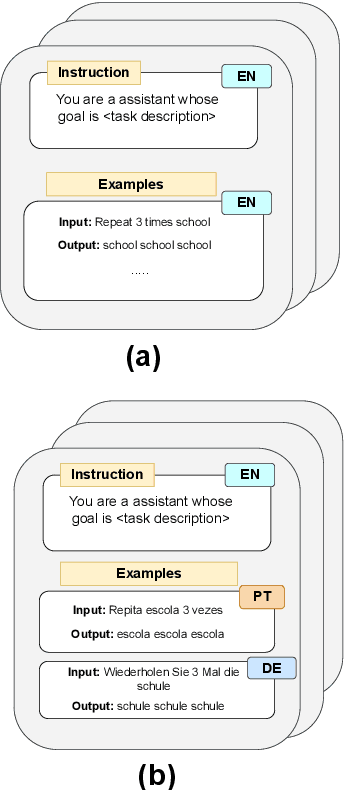
Language models are now capable of solving tasks that require dealing with long sequences consisting of hundreds of thousands of tokens. However, they often fail on tasks that require repetitive use of simple rules, even on sequences that are much shorter than those seen during training. For example, state-of-the-art LLMs can find common items in two lists with up to 20 items but fail when lists have 80 items. In this paper, we introduce MLissard, a multilingual benchmark designed to evaluate models' abilities to process and generate texts of varied lengths and offers a mechanism for controlling sequence complexity. Our evaluation of open-source and proprietary models show a consistent decline in performance across all models and languages as the complexity of the sequence increases. Surprisingly, the use of in-context examples in languages other than English helps increase extrapolation performance significantly. The datasets and code are available at https://github.com/unicamp-dl/Lissard
Quati: A Brazilian Portuguese Information Retrieval Dataset from Native Speakers
Apr 10, 2024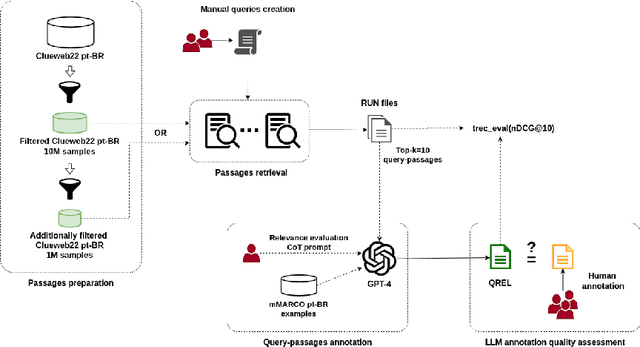
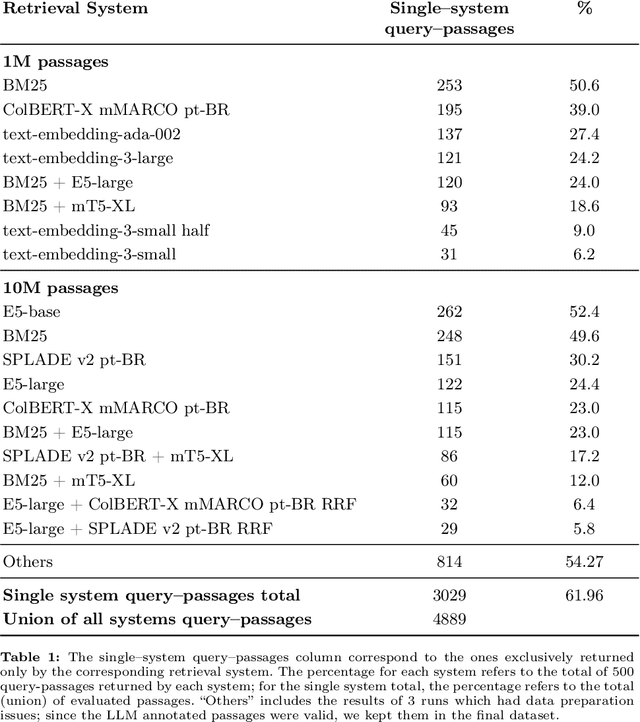
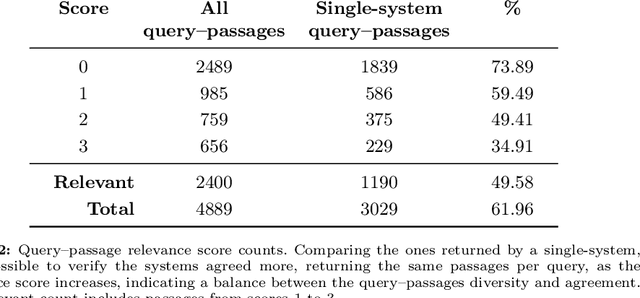
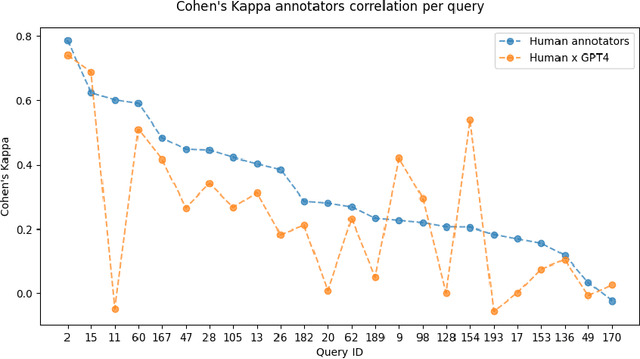
Despite Portuguese being one of the most spoken languages in the world, there is a lack of high-quality information retrieval datasets in that language. We present Quati, a dataset specifically designed for the Brazilian Portuguese language. It comprises a collection of queries formulated by native speakers and a curated set of documents sourced from a selection of high-quality Brazilian Portuguese websites. These websites are frequented more likely by real users compared to those randomly scraped, ensuring a more representative and relevant corpus. To label the query-document pairs, we use a state-of-the-art LLM, which shows inter-annotator agreement levels comparable to human performance in our assessments. We provide a detailed description of our annotation methodology to enable others to create similar datasets for other languages, providing a cost-effective way of creating high-quality IR datasets with an arbitrary number of labeled documents per query. Finally, we evaluate a diverse range of open-source and commercial retrievers to serve as baseline systems. Quati is publicly available at https://huggingface.co/datasets/unicamp-dl/quati and all scripts at https://github.com/unicamp-dl/quati .
Lissard: Long and Simple Sequential Reasoning Datasets
Feb 20, 2024Language models are now capable of solving tasks that require dealing with long sequences consisting of hundreds of thousands of tokens. However, they often fail on tasks that require repetitive use of simple rules, even on sequences that are much shorter than those seen during training. For example, state-of-the-art LLMs can find common items in two lists with up to 20 items but fail when lists have 80 items. In this paper, we introduce Lissard, a benchmark comprising seven tasks whose goal is to assess the ability of models to process and generate wide-range sequence lengths, requiring repetitive procedural execution. Our evaluation of open-source (Mistral-7B and Mixtral-8x7B) and proprietary models (GPT-3.5 and GPT-4) show a consistent decline in performance across all models as the complexity of the sequence increases. The datasets and code are available at https://github.com/unicamp-dl/Lissard
Induced Natural Language Rationales and Interleaved Markup Tokens Enable Extrapolation in Large Language Models
Aug 24, 2022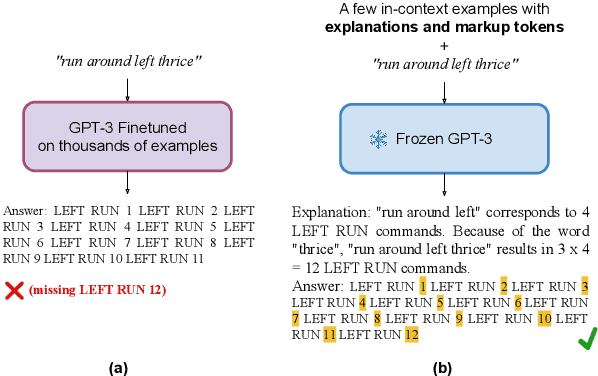
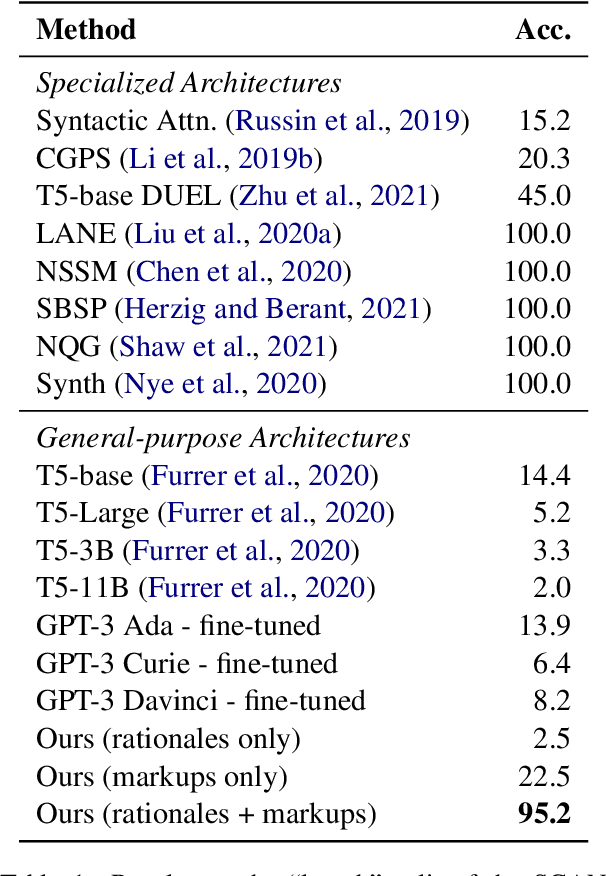
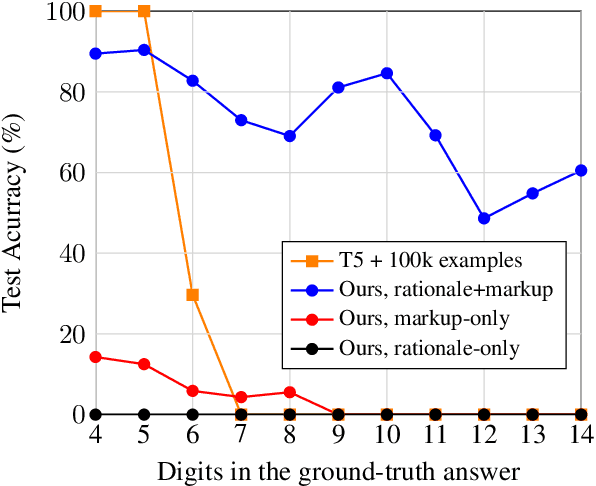

The ability to extrapolate, i.e., to make predictions on sequences that are longer than those presented as training examples, is a challenging problem for current deep learning models. Recent work shows that this limitation persists in state-of-the-art Transformer-based models. Most solutions to this problem use specific architectures or training methods that do not generalize to other tasks. We demonstrate that large language models can succeed in extrapolation without modifying their architecture or training procedure. Experimental results show that generating step-by-step rationales and introducing marker tokens are both required for effective extrapolation. First, we induce it to produce step-by-step rationales before outputting the answer to effectively communicate the task to the model. However, as sequences become longer, we find that current models struggle to keep track of token positions. To address this issue, we interleave output tokens with markup tokens that act as explicit positional and counting symbols. Our findings show how these two complementary approaches enable remarkable sequence extrapolation and highlight a limitation of current architectures to effectively generalize without explicit surface form guidance. Code available at https://github.com/MirelleB/induced-rationales-markup-tokens