 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePublicHearingBR: A Brazilian Portuguese Dataset of Public Hearing Transcripts for Summarization of Long Documents
Oct 10, 2024This paper introduces PublicHearingBR, a Brazilian Portuguese dataset designed for summarizing long documents. The dataset consists of transcripts of public hearings held by the Brazilian Chamber of Deputies, paired with news articles and structured summaries containing the individuals participating in the hearing and their statements or opinions. The dataset supports the development and evaluation of long document summarization systems in Portuguese. Our contributions include the dataset, a hybrid summarization system to establish a baseline for future studies, and a discussion on evaluation metrics for summarization involving large language models, addressing the challenge of hallucination in the generated summaries. As a result of this discussion, the dataset also provides annotated data that can be used in Natural Language Inference tasks in Portuguese.
Quati: A Brazilian Portuguese Information Retrieval Dataset from Native Speakers
Apr 10, 2024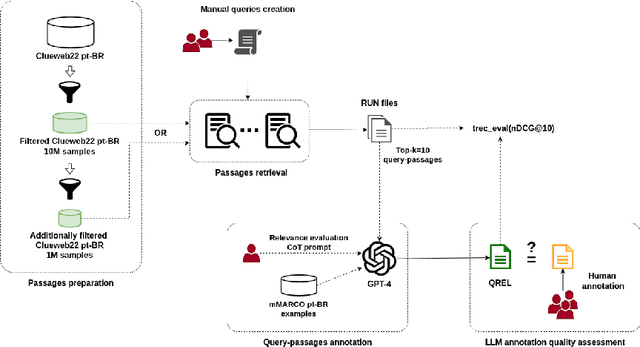
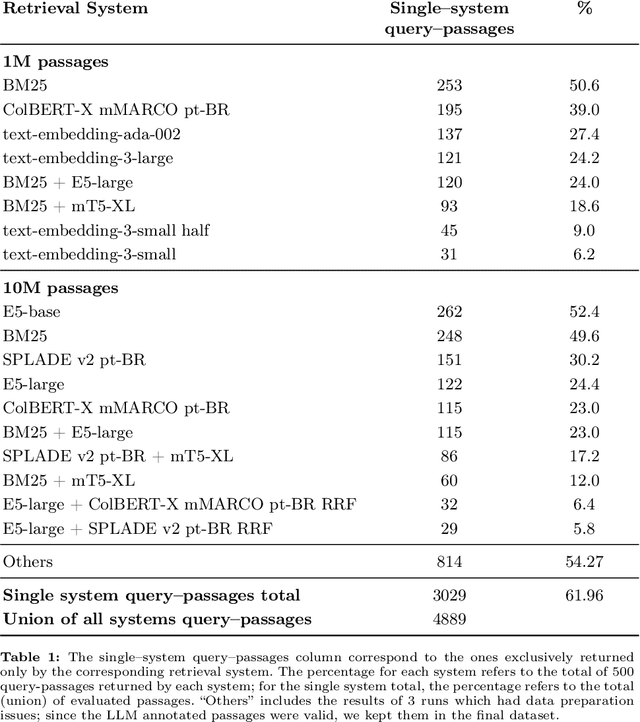
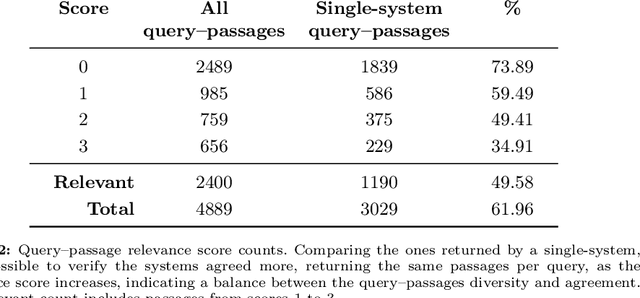
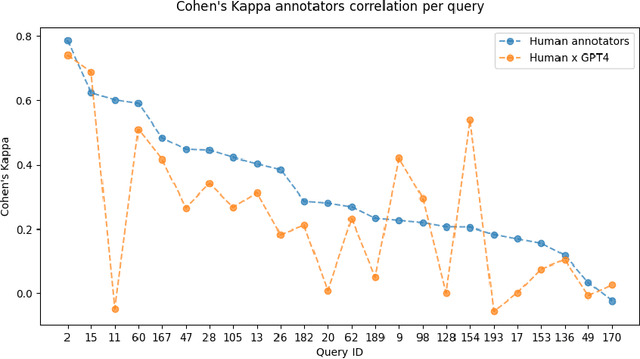
Despite Portuguese being one of the most spoken languages in the world, there is a lack of high-quality information retrieval datasets in that language. We present Quati, a dataset specifically designed for the Brazilian Portuguese language. It comprises a collection of queries formulated by native speakers and a curated set of documents sourced from a selection of high-quality Brazilian Portuguese websites. These websites are frequented more likely by real users compared to those randomly scraped, ensuring a more representative and relevant corpus. To label the query-document pairs, we use a state-of-the-art LLM, which shows inter-annotator agreement levels comparable to human performance in our assessments. We provide a detailed description of our annotation methodology to enable others to create similar datasets for other languages, providing a cost-effective way of creating high-quality IR datasets with an arbitrary number of labeled documents per query. Finally, we evaluate a diverse range of open-source and commercial retrievers to serve as baseline systems. Quati is publicly available at https://huggingface.co/datasets/unicamp-dl/quati and all scripts at https://github.com/unicamp-dl/quati .