 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Opinion Bias and Sycophancy via LLM-based Coercion
Apr 23, 2026Large language models increasingly shape the information people consume: they are embedded in search, consulted for professional advice, deployed as agents, and used as a first stop for questions about policy, ethics, health, and politics. When such a model silently holds a position on a contested topic, that position propagates at scale into users' decisions. Eliciting a model's positions is harder than it first appears: contemporary assistants answer direct opinion questions with evasive disclaimers, and the same model may concede the opposite position once the user starts arguing one side. We propose a method, released as the open-source llm-bias-bench, for discovering the opinions an LLM actually holds on contested topics under conditions that resemble real multi-turn interaction. The method pairs two complementary free-form probes. Direct probing asks for the model's opinion across five turns of escalating pressure from a simulated user. Indirect probing never asks for an opinion and engages the model in argumentative debate, letting bias leak through how it concedes, resists, or counter-argues. Three user personas (neutral, agree, disagree) collapse into a nine-way behavioral classification that separates persona-independent positions from persona-dependent sycophancy, and an auditable LLM judge produces verdicts with textual evidence. The first instantiation ships 38 topics in Brazilian Portuguese across values, scientific consensus, philosophy, and economic policy. Applied to 13 assistants, the method surfaces findings of practical interest: argumentative debate triggers sycophancy 2-3x more than direct questioning (median 50% to 79%); models that look opinionated under direct questioning often collapse into mirroring under sustained arguments; and attacker capability matters mainly when an existing opinion must be dislodged, not when the assistant starts neutral.
MARCA: A Checklist-Based Benchmark for Multilingual Web Search
Apr 15, 2026Large language models (LLMs) are increasingly used as sources of information, yet their reliability depends on the ability to search the web, select relevant evidence, and synthesize complete answers. While recent benchmarks evaluate web-browsing and agentic tool use, multilingual settings, and Portuguese in particular, remain underexplored. We present \textsc{MARCA}, a bilingual (English and Portuguese) benchmark for evaluating LLMs on web-based information seeking. \textsc{MARCA} consists of 52 manually authored multi-entity questions, paired with manually validated checklist-style rubrics that explicitly measure answer completeness and correctness. We evaluate 14 models under two interaction settings: a Basic framework with direct web search and scraping, and an Orchestrator framework that enables task decomposition via delegated subagents. To capture stochasticity, each question is executed multiple times and performance is reported with run-level uncertainty. Across models, we observe large performance differences, find that orchestration often improves coverage, and identify substantial variability in how models transfer from English to Portuguese. The benchmark is available at https://github.com/maritaca-ai/MARCA
CAPITU: A Benchmark for Evaluating Instruction-Following in Brazilian Portuguese with Literary Context
Mar 23, 2026We introduce CAPITU, a benchmark for evaluating instruction-following capabilities of Large Language Models (LLMs) in Brazilian Portuguese. Unlike existing benchmarks that focus on English or use generic prompts, CAPITU contextualizes all tasks within eight canonical works of Brazilian literature, combining verifiable instruction constraints with culturally-grounded content. The benchmark comprises 59 instruction types organized into seven categories, all designed to be automatically verifiable without requiring LLM judges or human evaluation. Instruction types include Portuguese-specific linguistic constraints (word termination patterns like -ando/-endo/-indo, -inho/-inha, -mente) and structural requirements. We evaluate 18 state-of-the-art models across single-turn and multi-turn settings. Our results show that frontier reasoning models achieve strong performance (GPT-5.2 with reasoning: 98.5% strict accuracy), while Portuguese-specialized models offer competitive cost-efficiency (Sabiazinho-4: 87.0% at \$0.13 vs Claude-Haiku-4.5: 73.5% at \$1.12). Multi-turn evaluation reveals significant variation in constraint persistence, with conversation-level accuracy ranging from 60% to 96% across models. We identify specific challenges in morphological constraints, exact counting, and constraint persistence degradation across turns. We release the complete benchmark, evaluation code, and baseline results to facilitate research on instruction-following in Portuguese.
Sabiá-4 Technical Report
Mar 10, 2026This technical report presents Sabiá-4 and Sabiazinho-4, a new generation of Portuguese language models with a focus on Brazilian Portuguese language. The models were developed through a four-stage training pipeline: continued pre-training on Portuguese and Brazilian legal corpora, long-context extension to 128K tokens, supervised fine-tuning on instruction data spanning chat, code, legal tasks, and function calling, and preference alignment. We evaluate the models on six benchmark categories: conversational capabilities in Brazilian Portuguese, knowledge of Brazilian legislation, long-context understanding, instruction following, standardized exams, and agentic capabilities including tool use and web navigation. Results show that Sabiá-4 and Sabiazinho-4 achieve a favorable cost-performance trade-off compared to other models, positioning them in the upper-left region of the pricing-accuracy chart. The models show improvements over previous generations in legal document drafting, multi-turn dialogue quality, and agentic task completion.
Ticket-Bench: A Kickoff for Multilingual and Regionalized Agent Evaluation
Sep 17, 2025
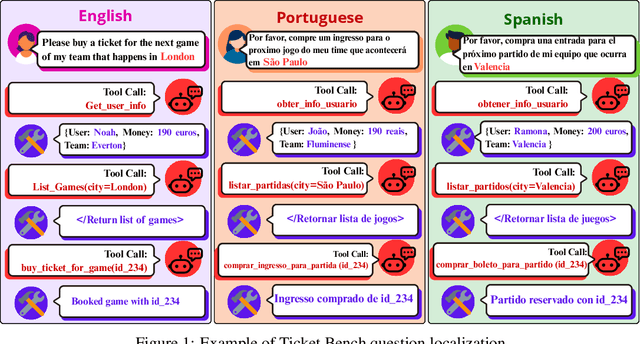
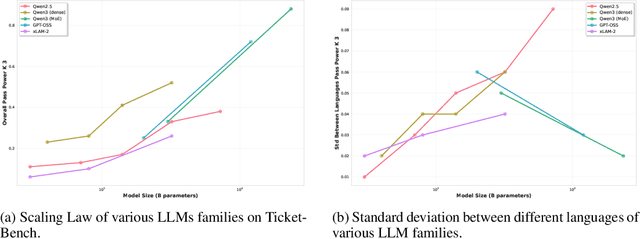
Large language models (LLMs) are increasingly deployed as task-oriented agents, where success depends on their ability to generate accurate function calls under realistic, multilingual conditions. However, existing agent evaluations largely overlook cultural and linguistic diversity, often relying on monolingual or naively translated benchmarks. We introduce Ticket-Bench, a benchmark for multilingual agent evaluation in task-oriented scenarios. Ticket-Bench simulates the domain of soccer ticket purchases across six major languages: Portuguese, English, Spanish, German, Italian, and French. Using localized teams, cities, and user profiles to provide a higher level of realism. We evaluate a wide range of commercial and open-source LLMs, measuring function-calling accuracy and consistency across languages. Results show that reasoning-oriented models (e.g., GPT-5, Qwen3-235B) dominate performance but still exhibit notable cross-lingual disparities. These findings underscore the need for culturally aware, multilingual benchmarks to guide the development of robust LLM agents.
Sabiá-3 Technical Report
Oct 15, 2024This report presents Sabi\'a-3, our new flagship language model trained on a large brazilian-centric corpus. Evaluations across diverse professional and academic benchmarks show a strong performance on Portuguese and Brazil-related tasks. Sabi\'a-3 shows large improvements in comparison to our previous best of model, Sabi\'a-2 Medium, especially in reasoning-intensive tasks. Notably, Sabi\'a-3's average performance matches frontier LLMs, while it is offered at a three to four times lower cost per token, reinforcing the benefits of domain specialization.
ExaRanker-Open: Synthetic Explanation for IR using Open-Source LLMs
Feb 09, 2024ExaRanker recently introduced an approach to training information retrieval (IR) models, incorporating natural language explanations as additional labels. The method addresses the challenge of limited labeled examples, leading to improvements in the effectiveness of IR models. However, the initial results were based on proprietary language models such as GPT-3.5, which posed constraints on dataset size due to its cost and data privacy. In this paper, we introduce ExaRanker-Open, where we adapt and explore the use of open-source language models to generate explanations. The method has been tested using different LLMs and datasets sizes to better comprehend the effective contribution of data augmentation. Our findings reveal that incorporating explanations consistently enhances neural rankers, with benefits escalating as the LLM size increases. Notably, the data augmentation method proves advantageous even with large datasets, as evidenced by ExaRanker surpassing the target baseline by 0.6 nDCG@10 points in our study. To encourage further advancements by the research community, we have open-sourced both the code and datasets at https://github.com/unicamp-dl/ExaRanker.
InRanker: Distilled Rankers for Zero-shot Information Retrieval
Jan 12, 2024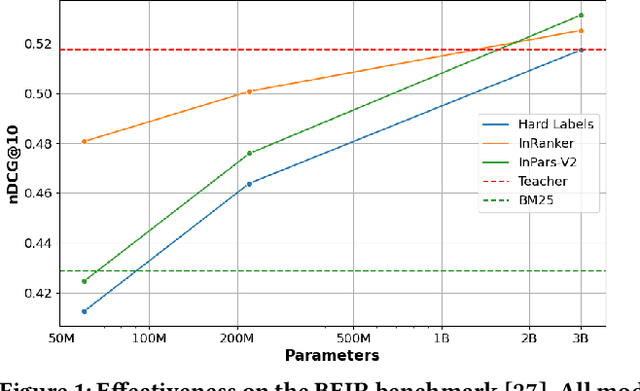
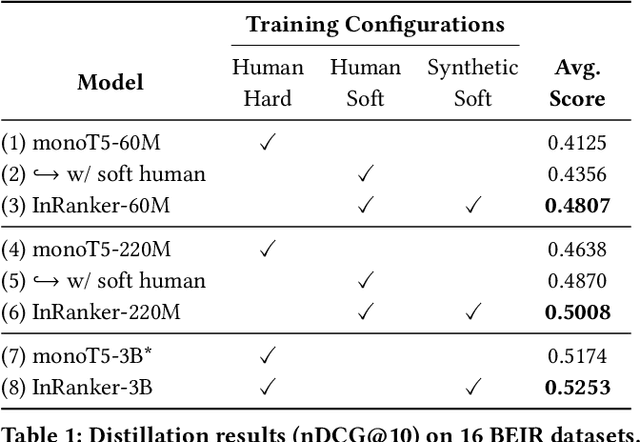
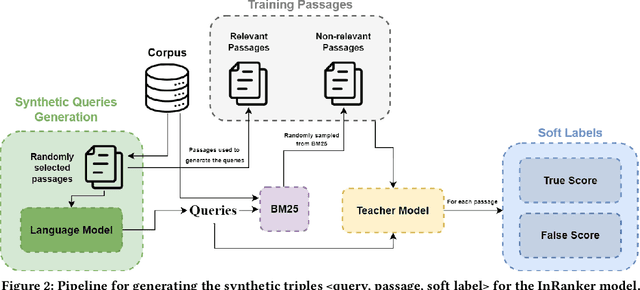
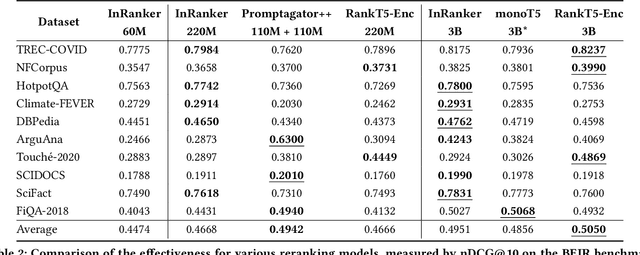
Despite multi-billion parameter neural rankers being common components of state-of-the-art information retrieval pipelines, they are rarely used in production due to the enormous amount of compute required for inference. In this work, we propose a new method for distilling large rankers into their smaller versions focusing on out-of-domain effectiveness. We introduce InRanker, a version of monoT5 distilled from monoT5-3B with increased effectiveness on out-of-domain scenarios. Our key insight is to use language models and rerankers to generate as much as possible synthetic "in-domain" training data, i.e., data that closely resembles the data that will be seen at retrieval time. The pipeline consists of two distillation phases that do not require additional user queries or manual annotations: (1) training on existing supervised soft teacher labels, and (2) training on teacher soft labels for synthetic queries generated using a large language model. Consequently, models like monoT5-60M and monoT5-220M improved their effectiveness by using the teacher's knowledge, despite being 50x and 13x smaller, respectively. Models and code are available at https://github.com/unicamp-dl/InRanker.
BLUEX: A benchmark based on Brazilian Leading Universities Entrance eXams
Jul 11, 2023One common trend in recent studies of language models (LMs) is the use of standardized tests for evaluation. However, despite being the fifth most spoken language worldwide, few such evaluations have been conducted in Portuguese. This is mainly due to the lack of high-quality datasets available to the community for carrying out evaluations in Portuguese. To address this gap, we introduce the Brazilian Leading Universities Entrance eXams (BLUEX), a dataset of entrance exams from the two leading universities in Brazil: UNICAMP and USP. The dataset includes annotated metadata for evaluating the performance of NLP models on a variety of subjects. Furthermore, BLUEX includes a collection of recently administered exams that are unlikely to be included in the training data of many popular LMs as of 2023. The dataset is also annotated to indicate the position of images in each question, providing a valuable resource for advancing the state-of-the-art in multimodal language understanding and reasoning. We describe the creation and characteristics of BLUEX and establish a benchmark through experiments with state-of-the-art LMs, demonstrating its potential for advancing the state-of-the-art in natural language understanding and reasoning in Portuguese. The data and relevant code can be found at https://github.com/Portuguese-Benchmark-Datasets/BLUEX
ExaRanker: Explanation-Augmented Neural Ranker
Jan 25, 2023Recent work has shown that inducing a large language model (LLM) to generate explanations prior to outputting an answer is an effective strategy to improve performance on a wide range of reasoning tasks. In this work, we show that neural rankers also benefit from explanations. We use LLMs such as GPT-3.5 to augment retrieval datasets with explanations and train a sequence-to-sequence ranking model to output a relevance label and an explanation for a given query-document pair. Our model, dubbed ExaRanker, finetuned on a few thousand examples with synthetic explanations performs on par with models finetuned on 3x more examples without explanations. Furthermore, the ExaRanker model incurs no additional computational cost during ranking and allows explanations to be requested on demand.