 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralSearchX: Serving a Multi-billion-parameter Reranker for Multilingual Metasearch at a Low Cost
Oct 26, 2022



The widespread availability of search API's (both free and commercial) brings the promise of increased coverage and quality of search results for metasearch engines, while decreasing the maintenance costs of the crawling and indexing infrastructures. However, merging strategies frequently comprise complex pipelines that require careful tuning, which is often overlooked in the literature. In this work, we describe NeuralSearchX, a metasearch engine based on a multi-purpose large reranking model to merge results and highlight sentences. Due to the homogeneity of our architecture, we could focus our optimization efforts on a single component. We compare our system with Microsoft's Biomedical Search and show that our design choices led to a much cost-effective system with competitive QPS while having close to state-of-the-art results on a wide range of public benchmarks. Human evaluation on two domain-specific tasks shows that our retrieval system outperformed Google API by a large margin in terms of nDCG@10 scores. By describing our architecture and implementation in detail, we hope that the community will build on our design choices. The system is available at https://neuralsearchx.nsx.ai.
* published as a full paper at the DESIRES 2022 Conference. 13 pages
mMARCO: A Multilingual Version of MS MARCO Passage Ranking Dataset
Aug 31, 2021
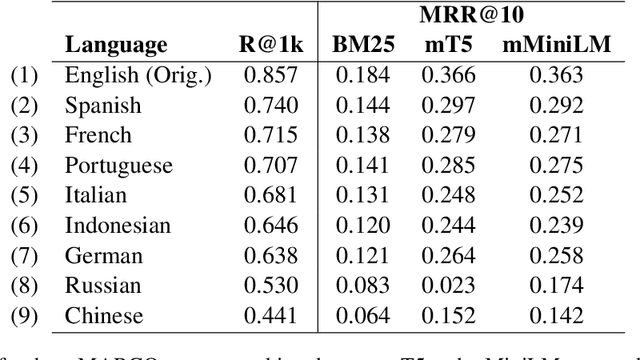
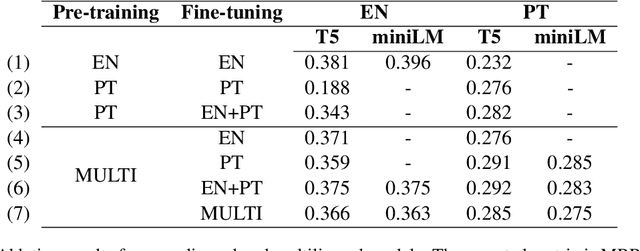
The MS MARCO ranking dataset has been widely used for training deep learning models for IR tasks, achieving considerable effectiveness on diverse zero-shot scenarios. However, this type of resource is scarce in other languages than English. In this work we present mMARCO, a multilingual version of the MS MARCO passage ranking dataset comprising 8 languages that was created using machine translation. We evaluated mMARCO by fine-tuning mono and multilingual re-ranking models on it. Experimental results demonstrate that multilingual models fine-tuned on our translated dataset achieve superior effectiveness than models fine-tuned on the original English version alone. Also, our distilled multilingual re-ranker is competitive with non-distilled models while having 5.4 times fewer parameters. The translated datasets as well as fine-tuned models are available at https://github.com/unicamp-dl/mMARCO.git.
A cost-benefit analysis of cross-lingual transfer methods
May 29, 2021
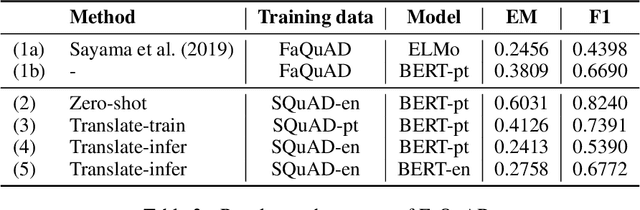
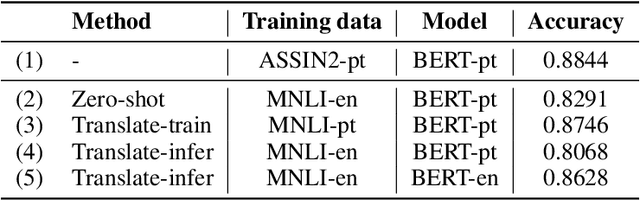
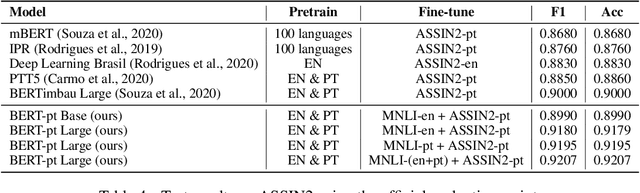
An effective method for cross-lingual transfer is to fine-tune a bilingual or multilingual model on a supervised dataset in one language and evaluating it on another language in a zero-shot manner. Translating examples at training time or inference time are also viable alternatives. However, there are costs associated with these methods that are rarely addressed in the literature. In this work, we analyze cross-lingual methods in terms of their effectiveness (e.g., accuracy), development and deployment costs, as well as their latencies at inference time. Our experiments on three tasks indicate that the best cross-lingual method is highly task-dependent. Finally, by combining zero-shot and translation methods, we achieve the state-of-the-art in two of the three datasets used in this work. Based on these results, we question the need for manually labeled training data in a target language. Code, models and translated datasets are available at https://github.com/unicamp-dl/cross-lingual-analysis