 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurió-Edu 7B: Examining Data Selection Impacts in LLM Continued Pretraining
Dec 14, 2025Continued pretraining extends a language model's capabilities by further exposing it to additional data, often tailored to a specific linguistic or domain context. This strategy has emerged as an efficient alternative to full retraining when adapting general-purpose models to new settings. In this work, we investigate this paradigm through Curió 7B, a 7-billion-parameter model derived from LLaMA-2 and trained on 100 billion Portuguese tokens from the ClassiCC-PT corpus - the most extensive Portuguese-specific continued-pretraining effort above the three-billion-parameter scale to date. Beyond scale, we investigate whether quantity alone suffices or whether data quality plays a decisive role in linguistic adaptation. To this end, we introduce Curió-Edu 7B, a variant trained exclusively on the educational and STEM-filtered subset of the same corpus, totaling just 10 billion tokens. Despite using only 10% of the data and 20% of the computation, Curió-Edu 7B surpasses the full-corpus model in our evaluations, demonstrating that data selection can be fundamental even when adapting models with limited prior exposure to the target language. The developed models are available at https://huggingface.co/collections/ClassiCC-Corpus/curio-edu
Ticket-Bench: A Kickoff for Multilingual and Regionalized Agent Evaluation
Sep 17, 2025
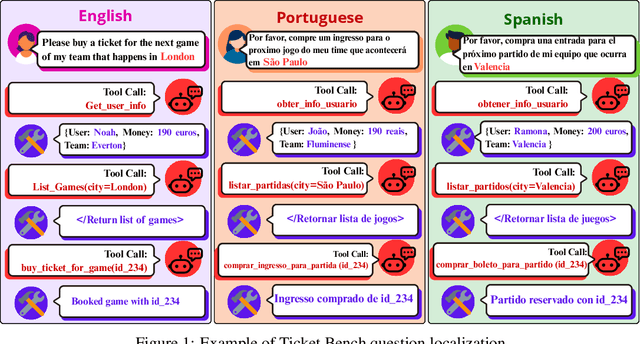
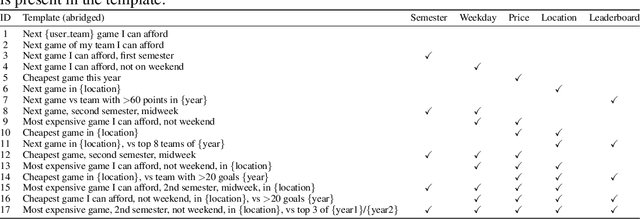
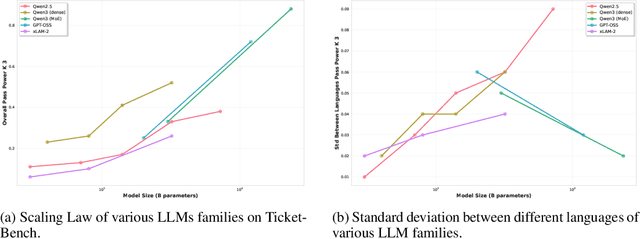
Large language models (LLMs) are increasingly deployed as task-oriented agents, where success depends on their ability to generate accurate function calls under realistic, multilingual conditions. However, existing agent evaluations largely overlook cultural and linguistic diversity, often relying on monolingual or naively translated benchmarks. We introduce Ticket-Bench, a benchmark for multilingual agent evaluation in task-oriented scenarios. Ticket-Bench simulates the domain of soccer ticket purchases across six major languages: Portuguese, English, Spanish, German, Italian, and French. Using localized teams, cities, and user profiles to provide a higher level of realism. We evaluate a wide range of commercial and open-source LLMs, measuring function-calling accuracy and consistency across languages. Results show that reasoning-oriented models (e.g., GPT-5, Qwen3-235B) dominate performance but still exhibit notable cross-lingual disparities. These findings underscore the need for culturally aware, multilingual benchmarks to guide the development of robust LLM agents.
Building High-Quality Datasets for Portuguese LLMs: From Common Crawl Snapshots to Industrial-Grade Corpora
Sep 10, 2025The performance of large language models (LLMs) is deeply influenced by the quality and composition of their training data. While much of the existing work has centered on English, there remains a gap in understanding how to construct effective training corpora for other languages. We explore scalable methods for building web-based corpora for LLMs. We apply them to build a new 120B token corpus in Portuguese that achieves competitive results to an industrial-grade corpus. Using a continual pretraining setup, we study how different data selection and preprocessing strategies affect LLM performance when transitioning a model originally trained in English to another language. Our findings demonstrate the value of language-specific filtering pipelines, including classifiers for education, science, technology, engineering, and mathematics (STEM), as well as toxic content. We show that adapting a model to the target language leads to performance improvements, reinforcing the importance of high-quality, language-specific data. While our case study focuses on Portuguese, our methods are applicable to other languages, offering insights for multilingual LLM development.
BRoverbs -- Measuring how much LLMs understand Portuguese proverbs
Sep 10, 2025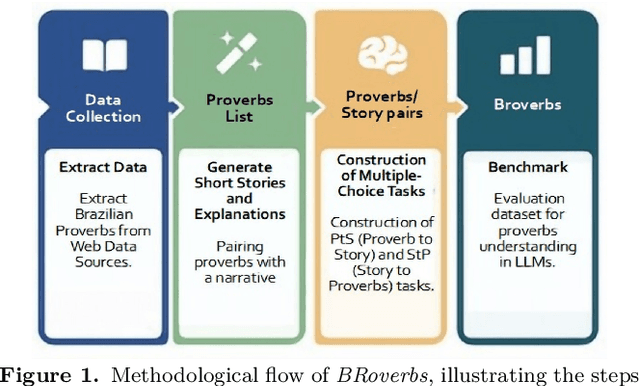
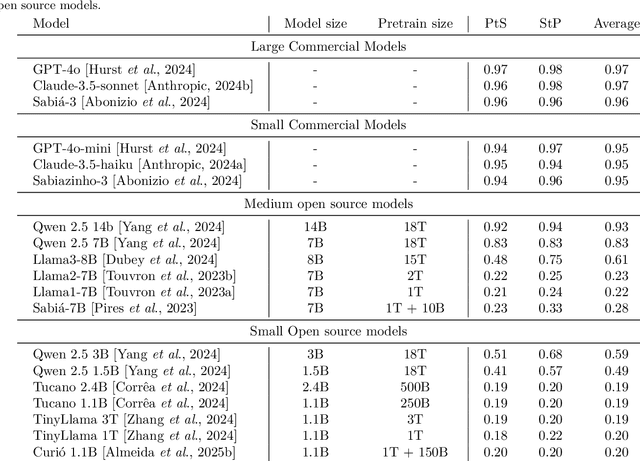
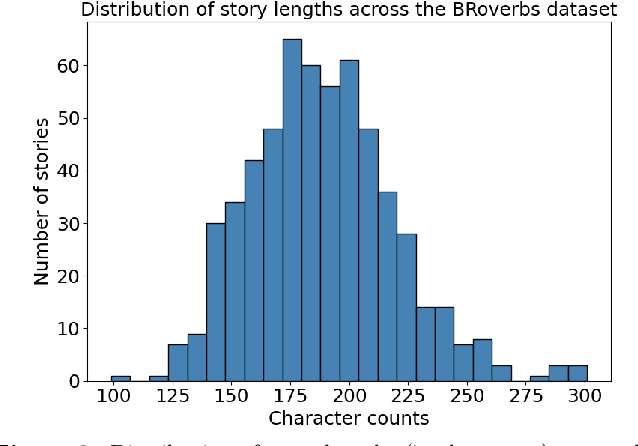
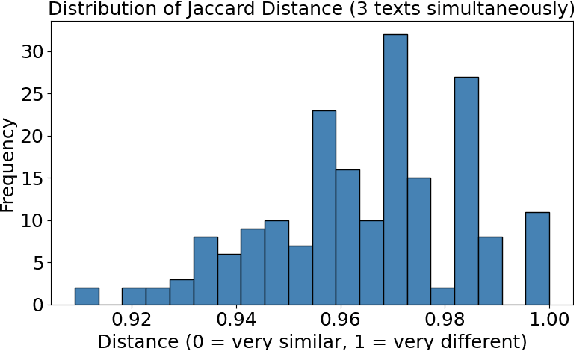
Large Language Models (LLMs) exhibit significant performance variations depending on the linguistic and cultural context in which they are applied. This disparity signals the necessity of mature evaluation frameworks that can assess their capabilities in specific regional settings. In the case of Portuguese, existing evaluations remain limited, often relying on translated datasets that may not fully capture linguistic nuances or cultural references. Meanwhile, native Portuguese-language datasets predominantly focus on structured national exams or sentiment analysis of social media interactions, leaving gaps in evaluating broader linguistic understanding. To address this limitation, we introduce BRoverbs, a dataset specifically designed to assess LLM performance through Brazilian proverbs. Proverbs serve as a rich linguistic resource, encapsulating cultural wisdom, figurative expressions, and complex syntactic structures that challenge the model comprehension of regional expressions. BRoverbs aims to provide a new evaluation tool for Portuguese-language LLMs, contributing to advancing regionally informed benchmarking. The benchmark is available at https://huggingface.co/datasets/Tropic-AI/BRoverbs.
TiEBe: A Benchmark for Assessing the Current Knowledge of Large Language Models
Jan 13, 2025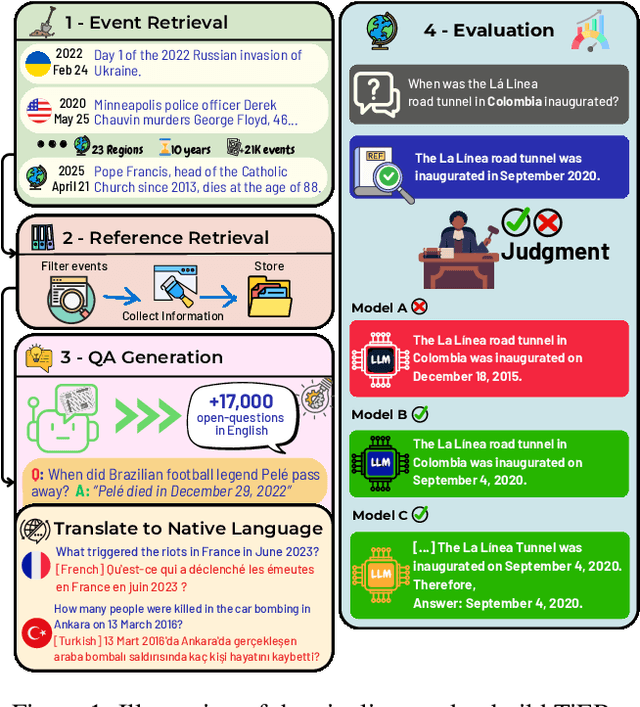
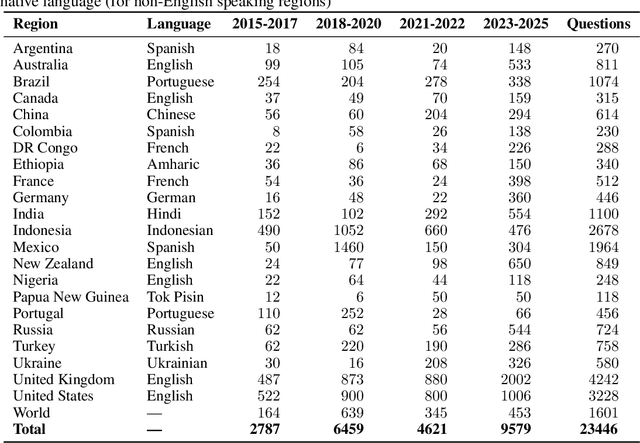

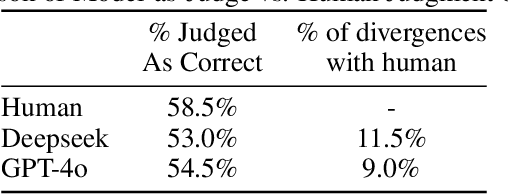
In a rapidly evolving knowledge landscape and the increasing adoption of large language models, a need has emerged to keep these models continuously updated with current events. While existing benchmarks evaluate general factual recall, they often overlook two critical aspects: the ability of models to integrate evolving knowledge through continual learning and the significant regional disparities in their performance. To address these gaps, we introduce the Timely Events Benchmark (TiEBe), a dataset containing over 11,000 question-answer pairs focused on globally and regionally significant events. TiEBe leverages structured retrospective data from Wikipedia, enabling continuous updates to assess LLMs' knowledge of evolving global affairs and their understanding of events across different regions. Our benchmark demonstrates that LLMs exhibit substantial geographic disparities in factual recall, emphasizing the need for more balanced global knowledge representation. Furthermore, TiEBe serves as a tool for evaluating continual learning strategies, providing insights into models' ability to acquire new information without forgetting past knowledge.
The interplay between domain specialization and model size: a case study in the legal domain
Jan 03, 2025Scaling laws for language models so far focused on finding the compute-optimal model size and token count for training from scratch. However, achieving this optimal balance requires significant compute resources due to the extensive data demands when training models from randomly-initialized weights. Continual pre-training offers a cost-effective alternative, leveraging the compute investment from pre-trained models to incorporate new knowledge without requiring extensive new data. Recent findings suggest that data quality influences constants in scaling laws, thereby altering the optimal parameter-token allocation ratio. Building on this insight, we investigate the interplay between domain specialization and model size during continual pre-training under compute-constrained scenarios. Our goal is to identify a compute-efficient training regime for this scenario and, potentially, detect patterns in this interplay that can be generalized across different model sizes and domains. To compare general and specialized training, we filtered a web-based dataset to extract legal domain data. We pre-trained models with 1.5B, 3B, 7B and 14B parameters on both the unfiltered and filtered datasets, then evaluated their performance on legal exams. Results show that as model size increases, the compute-effectiveness gap between specialized and general models widens.
Sabiá-3 Technical Report
Oct 15, 2024This report presents Sabi\'a-3, our new flagship language model trained on a large brazilian-centric corpus. Evaluations across diverse professional and academic benchmarks show a strong performance on Portuguese and Brazil-related tasks. Sabi\'a-3 shows large improvements in comparison to our previous best of model, Sabi\'a-2 Medium, especially in reasoning-intensive tasks. Notably, Sabi\'a-3's average performance matches frontier LLMs, while it is offered at a three to four times lower cost per token, reinforcing the benefits of domain specialization.
SurveySum: A Dataset for Summarizing Multiple Scientific Articles into a Survey Section
Aug 29, 2024



Document summarization is a task to shorten texts into concise and informative summaries. This paper introduces a novel dataset designed for summarizing multiple scientific articles into a section of a survey. Our contributions are: (1) SurveySum, a new dataset addressing the gap in domain-specific summarization tools; (2) two specific pipelines to summarize scientific articles into a section of a survey; and (3) the evaluation of these pipelines using multiple metrics to compare their performance. Our results highlight the importance of high-quality retrieval stages and the impact of different configurations on the quality of generated summaries.
Measuring Cross-lingual Transfer in Bytes
Apr 12, 2024Multilingual pretraining has been a successful solution to the challenges posed by the lack of resources for languages. These models can transfer knowledge to target languages with minimal or no examples. Recent research suggests that monolingual models also have a similar capability, but the mechanisms behind this transfer remain unclear. Some studies have explored factors like language contamination and syntactic similarity. An emerging line of research suggests that the representations learned by language models contain two components: a language-specific and a language-agnostic component. The latter is responsible for transferring a more universal knowledge. However, there is a lack of comprehensive exploration of these properties across diverse target languages. To investigate this hypothesis, we conducted an experiment inspired by the work on the Scaling Laws for Transfer. We measured the amount of data transferred from a source language to a target language and found that models initialized from diverse languages perform similarly to a target language in a cross-lingual setting. This was surprising because the amount of data transferred to 10 diverse target languages, such as Spanish, Korean, and Finnish, was quite similar. We also found evidence that this transfer is not related to language contamination or language proximity, which strengthens the hypothesis that the model also relies on language-agnostic knowledge. Our experiments have opened up new possibilities for measuring how much data represents the language-agnostic representations learned during pretraining.
Sabiá-2: A New Generation of Portuguese Large Language Models
Mar 26, 2024We introduce Sabi\'a-2, a family of large language models trained on Portuguese texts. The models are evaluated on a diverse range of exams, including entry-level tests for Brazilian universities, professional certification exams, and graduate-level exams for various disciplines such as accounting, economics, engineering, law and medicine. Our results reveal that our best model so far, Sabi\'a-2 Medium, matches or surpasses GPT-4's performance in 23 out of 64 exams and outperforms GPT-3.5 in 58 out of 64 exams. Notably, specialization has a significant impact on a model's performance without the need to increase its size, allowing us to offer Sabi\'a-2 Medium at a price per token that is 10 times cheaper than GPT-4. Finally, we identified that math and coding are key abilities that need improvement.