 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Adaptive Dense Retrieval for Brazilian Legal Search
May 05, 2026Brazilian legal retrieval is heterogeneous, covering case law, legislation, and question-based search. This makes training dense retrievers a trade-off between stronger domain specialization and broader robustness across retrieval types of search. In this paper, we explore this trade-off using three training setups based on Qwen3-Embedding-4B: a base model with no fine-tuning, a version trained only on legal data, and a mixed setup that combines legal data with SQuAD-pt supervised dataset. We evaluate these models on five legal datasets from the JUÁ leaderboard, along with Quati dataset as an extra Portuguese retrieval benchmark to test out-of-domain generalization. The legal-only model performs best on the most specialized legal tasks. The mixed setup keeps strong performance on legal data while offering a better overall balance, improving average NDCG@10 from 0.414 to 0.447, MRR@10 from 0.586 to 0.595, and MAP@10 from 0.270 to 0.308 across all six datasets. The biggest improvement appears on Quati, where the mixed model clearly outperforms the legal-only one. Overall, the results show that legal-only and mixed training lead to different strengths: the first is better for specialization, while the second is more robust across different types of search, especially question-based ones. Both adapted models are available on Hugging Face
JUÁ - A Benchmark for Information Retrieval in Brazilian Legal Text Collections
Apr 07, 2026Legal information retrieval in Portuguese remains difficult to evaluate systematically because available datasets differ widely in document type, query style, and relevance definition. We present \textsc{JUÁ}, a public benchmark for Brazilian legal retrieval designed to support more reproducible and comparable evaluation across heterogeneous legal collections. More broadly, \textsc{JUÁ} is intended not only as a benchmark, but as a continuous evaluation infrastructure for Brazilian legal IR, combining shared protocols, common ranking metrics, fixed splits when applicable, and a public leaderboard. The benchmark covers jurisprudence retrieval as well as broader legislative, regulatory, and question-driven legal search. We evaluate lexical, dense, and BM25-based reranking pipelines, including a domain-adapted Qwen embedding model fine-tuned on \textsc{JUÁ}-aligned supervision. Results show that the benchmark is sufficiently heterogeneous to distinguish retrieval paradigms and reveal substantial cross-dataset trade-offs. Domain adaptation yields its clearest gains on the supervision-aligned \textsc{JUÁ-Juris} subset, while BM25 remains highly competitive on other collections, especially in settings with strong lexical and institutional phrasing cues. Overall, \textsc{JUÁ} provides a practical evaluation framework for studying legal retrieval across multiple Brazilian legal domains under a common benchmark design.
BR-TaxQA-R: A Dataset for Question Answering with References for Brazilian Personal Income Tax Law, including case law
May 21, 2025This paper presents BR-TaxQA-R, a novel dataset designed to support question answering with references in the context of Brazilian personal income tax law. The dataset contains 715 questions from the 2024 official Q\&A document published by Brazil's Internal Revenue Service, enriched with statutory norms and administrative rulings from the Conselho Administrativo de Recursos Fiscais (CARF). We implement a Retrieval-Augmented Generation (RAG) pipeline using OpenAI embeddings for searching and GPT-4o-mini for answer generation. We compare different text segmentation strategies and benchmark our system against commercial tools such as ChatGPT and Perplexity.ai using RAGAS-based metrics. Results show that our custom RAG pipeline outperforms commercial systems in Response Relevancy, indicating stronger alignment with user queries, while commercial models achieve higher scores in Factual Correctness and fluency. These findings highlight a trade-off between legally grounded generation and linguistic fluency. Crucially, we argue that human expert evaluation remains essential to ensure the legal validity of AI-generated answers in high-stakes domains such as taxation. BR-TaxQA-R is publicly available at https://huggingface.co/datasets/unicamp-dl/BR-TaxQA-R.
Aplicação de Large Language Models na Análise e Síntese de Documentos Jurídicos: Uma Revisão de Literatura
Apr 01, 2025Large Language Models (LLMs) have been increasingly used to optimize the analysis and synthesis of legal documents, enabling the automation of tasks such as summarization, classification, and retrieval of legal information. This study aims to conduct a systematic literature review to identify the state of the art in prompt engineering applied to LLMs in the legal context. The results indicate that models such as GPT-4, BERT, Llama 2, and Legal-Pegasus are widely employed in the legal field, and techniques such as Few-shot Learning, Zero-shot Learning, and Chain-of-Thought prompting have proven effective in improving the interpretation of legal texts. However, challenges such as biases in models and hallucinations still hinder their large-scale implementation. It is concluded that, despite the great potential of LLMs for the legal field, there is a need to improve prompt engineering strategies to ensure greater accuracy and reliability in the generated results.
SurveySum: A Dataset for Summarizing Multiple Scientific Articles into a Survey Section
Aug 29, 2024



Document summarization is a task to shorten texts into concise and informative summaries. This paper introduces a novel dataset designed for summarizing multiple scientific articles into a section of a survey. Our contributions are: (1) SurveySum, a new dataset addressing the gap in domain-specific summarization tools; (2) two specific pipelines to summarize scientific articles into a section of a survey; and (3) the evaluation of these pipelines using multiple metrics to compare their performance. Our results highlight the importance of high-quality retrieval stages and the impact of different configurations on the quality of generated summaries.
Check-Eval: A Checklist-based Approach for Evaluating Text Quality
Jul 19, 2024



Evaluating the quality of text generated by large language models (LLMs) remains a significant challenge. Traditional metrics often fail to align well with human judgments, particularly in tasks requiring creativity and nuance. In this paper, we propose Check-Eval, a novel evaluation framework leveraging LLMs to assess the quality of generated text through a checklist-based approach. Check-Eval can be employed as both a reference-free and reference-dependent evaluation method, providing a structured and interpretable assessment of text quality. The framework consists of two main stages: checklist generation and checklist evaluation. We validate Check-Eval on two benchmark datasets: Portuguese Legal Semantic Textual Similarity and SummEval. Our results demonstrate that Check-Eval achieves higher correlations with human judgments compared to existing metrics, such as G-Eval and GPTScore, underscoring its potential as a more reliable and effective evaluation framework for natural language generation tasks. The code for our experiments is available at https://anonymous.4open.science/r/check-eval-0DB4.
Enhancing Augmentative and Alternative Communication with Card Prediction and Colourful Semantics
May 24, 2024This paper presents an approach to enhancing Augmentative and Alternative Communication (AAC) systems by integrating Colourful Semantics (CS) with transformer-based language models specifically tailored for Brazilian Portuguese. We introduce an adapted BERT model, BERTptCS, which incorporates the CS framework for improved prediction of communication cards. The primary aim is to enhance the accuracy and contextual relevance of communication card predictions, which are essential in AAC systems for individuals with complex communication needs (CCN). We compared BERTptCS with a baseline model, BERTptAAC, which lacks CS integration. Our results demonstrate that BERTptCS significantly outperforms BERTptAAC in various metrics, including top-k accuracy, Mean Reciprocal Rank (MRR), and Entropy@K. Integrating CS into the language model improves prediction accuracy and offers a more intuitive and contextual understanding of user inputs, facilitating more effective communication.
INACIA: Integrating Large Language Models in Brazilian Audit Courts: Opportunities and Challenges
Jan 19, 2024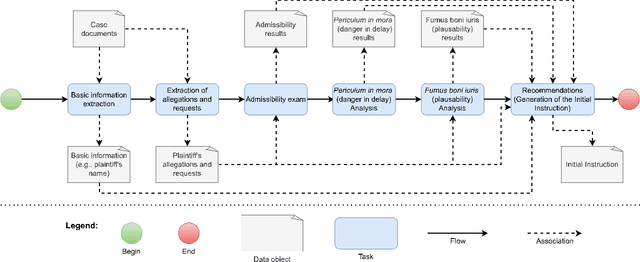


This paper introduces INACIA (Instru\c{c}\~ao Assistida com Intelig\^encia Artificial), a groundbreaking system designed to integrate Large Language Models (LLMs) into the operational framework of Brazilian Federal Court of Accounts (TCU). The system automates various stages of case analysis, including basic information extraction, admissibility examination, Periculum in mora and Fumus boni iuris analyses, and recommendations generation. Through a series of experiments, we demonstrate INACIA's potential in extracting relevant information from case documents, evaluating its legal plausibility, and formulating propositions for judicial decision-making. Utilizing a validation dataset alongside LLMs, our evaluation methodology presents an innovative approach to assessing system performance, correlating highly with human judgment. The results highlight INACIA's proficiency in handling complex legal tasks, indicating its suitability for augmenting efficiency and judicial fairness within legal systems. The paper also discusses potential enhancements and future applications, positioning INACIA as a model for worldwide AI integration in legal domains.
An experiment on an automated literature survey of data-driven speech enhancement methods
Oct 10, 2023



The increasing number of scientific publications in acoustics, in general, presents difficulties in conducting traditional literature surveys. This work explores the use of a generative pre-trained transformer (GPT) model to automate a literature survey of 116 articles on data-driven speech enhancement methods. The main objective is to evaluate the capabilities and limitations of the model in providing accurate responses to specific queries about the papers selected from a reference human-based survey. While we see great potential to automate literature surveys in acoustics, improvements are needed to address technical questions more clearly and accurately.
Predictive Authoring for Brazilian Portuguese Augmentative and Alternative Communication
Aug 18, 2023



Individuals with complex communication needs (CCN) often rely on augmentative and alternative communication (AAC) systems to have conversations and communique their wants. Such systems allow message authoring by arranging pictograms in sequence. However, the difficulty of finding the desired item to complete a sentence can increase as the user's vocabulary increases. This paper proposes using BERTimbau, a Brazilian Portuguese version of BERT, for pictogram prediction in AAC systems. To finetune BERTimbau, we constructed an AAC corpus for Brazilian Portuguese to use as a training corpus. We tested different approaches to representing a pictogram for prediction: as a word (using pictogram captions), as a concept (using a dictionary definition), and as a set of synonyms (using related terms). We also evaluated the usage of images for pictogram prediction. The results demonstrate that using embeddings computed from the pictograms' caption, synonyms, or definitions have a similar performance. Using synonyms leads to lower perplexity, but using captions leads to the highest accuracies. This paper provides insight into how to represent a pictogram for prediction using a BERT-like model and the potential of using images for pictogram prediction.