 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Based Intrusion Detection for Automotive Ethernet: Evaluating & Optimizing Fast Inference Techniques for Deployment on Low-Cost Platform
Jul 01, 2025Modern vehicles are increasingly connected, and in this context, automotive Ethernet is one of the technologies that promise to provide the necessary infrastructure for intra-vehicle communication. However, these systems are subject to attacks that can compromise safety, including flow injection attacks. Deep Learning-based Intrusion Detection Systems (IDS) are often designed to combat this problem, but they require expensive hardware to run in real time. In this work, we propose to evaluate and apply fast neural network inference techniques like Distilling and Prunning for deploying IDS models on low-cost platforms in real time. The results show that these techniques can achieve intrusion detection times of up to 727 {\mu}s using a Raspberry Pi 4, with AUCROC values of 0.9890.
Enhancing Augmentative and Alternative Communication with Card Prediction and Colourful Semantics
May 24, 2024This paper presents an approach to enhancing Augmentative and Alternative Communication (AAC) systems by integrating Colourful Semantics (CS) with transformer-based language models specifically tailored for Brazilian Portuguese. We introduce an adapted BERT model, BERTptCS, which incorporates the CS framework for improved prediction of communication cards. The primary aim is to enhance the accuracy and contextual relevance of communication card predictions, which are essential in AAC systems for individuals with complex communication needs (CCN). We compared BERTptCS with a baseline model, BERTptAAC, which lacks CS integration. Our results demonstrate that BERTptCS significantly outperforms BERTptAAC in various metrics, including top-k accuracy, Mean Reciprocal Rank (MRR), and Entropy@K. Integrating CS into the language model improves prediction accuracy and offers a more intuitive and contextual understanding of user inputs, facilitating more effective communication.
Planning the path with Reinforcement Learning: Optimal Robot Motion Planning in RoboCup Small Size League Environments
Apr 23, 2024This work investigates the potential of Reinforcement Learning (RL) to tackle robot motion planning challenges in the dynamic RoboCup Small Size League (SSL). Using a heuristic control approach, we evaluate RL's effectiveness in obstacle-free and single-obstacle path-planning environments. Ablation studies reveal significant performance improvements. Our method achieved a 60% time gain in obstacle-free environments compared to baseline algorithms. Additionally, our findings demonstrated dynamic obstacle avoidance capabilities, adeptly navigating around moving blocks. These findings highlight the potential of RL to enhance robot motion planning in the challenging and unpredictable SSL environment.
Predictive Authoring for Brazilian Portuguese Augmentative and Alternative Communication
Aug 18, 2023



Individuals with complex communication needs (CCN) often rely on augmentative and alternative communication (AAC) systems to have conversations and communique their wants. Such systems allow message authoring by arranging pictograms in sequence. However, the difficulty of finding the desired item to complete a sentence can increase as the user's vocabulary increases. This paper proposes using BERTimbau, a Brazilian Portuguese version of BERT, for pictogram prediction in AAC systems. To finetune BERTimbau, we constructed an AAC corpus for Brazilian Portuguese to use as a training corpus. We tested different approaches to representing a pictogram for prediction: as a word (using pictogram captions), as a concept (using a dictionary definition), and as a set of synonyms (using related terms). We also evaluated the usage of images for pictogram prediction. The results demonstrate that using embeddings computed from the pictograms' caption, synonyms, or definitions have a similar performance. Using synonyms leads to lower perplexity, but using captions leads to the highest accuracies. This paper provides insight into how to represent a pictogram for prediction using a BERT-like model and the potential of using images for pictogram prediction.
Distinction Maximization Loss: Efficiently Improving Classification Accuracy, Uncertainty Estimation, and Out-of-Distribution Detection Simply Replacing the Loss and Calibrating
May 19, 2022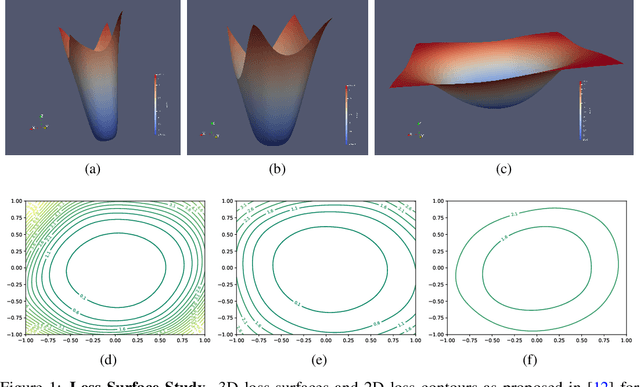
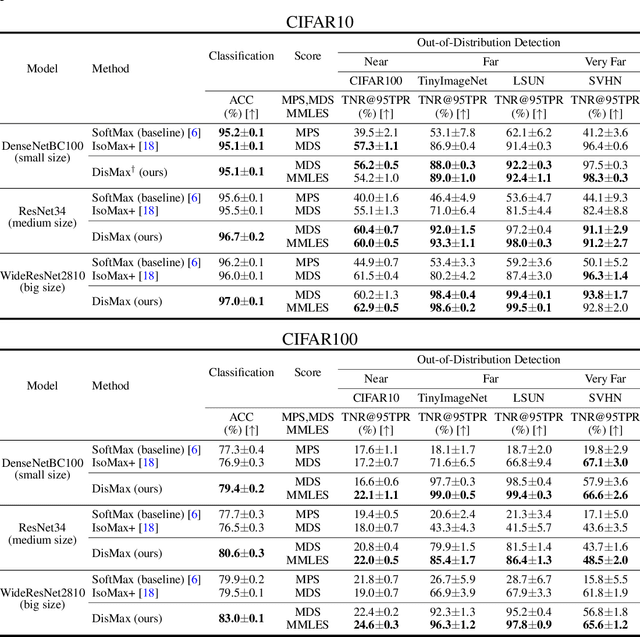
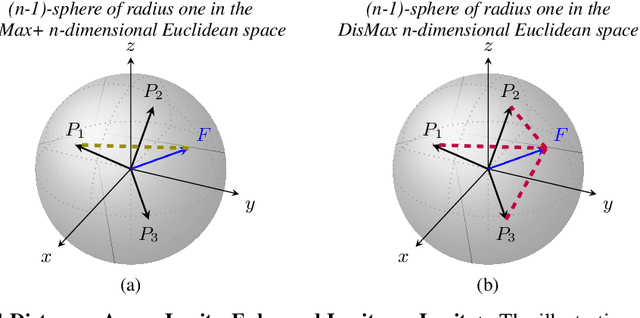
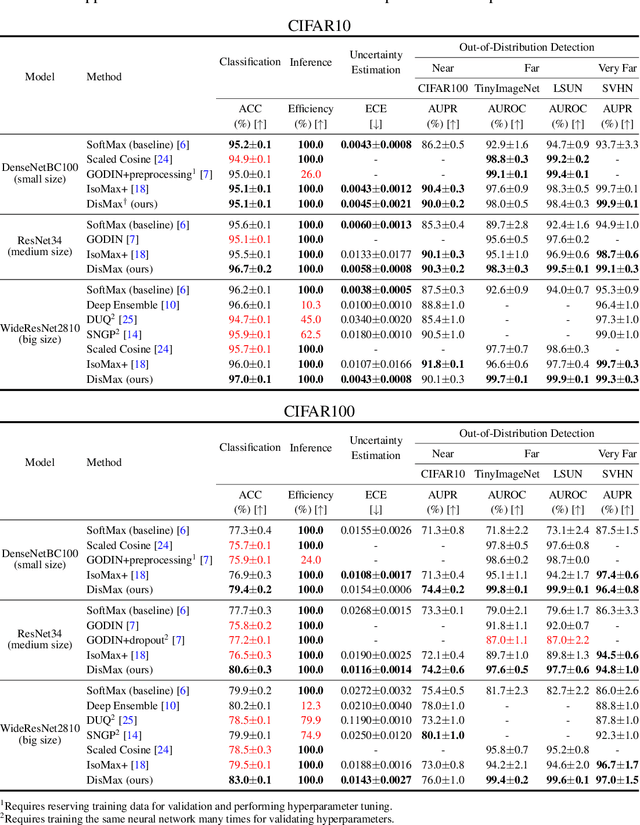
Building robust deterministic neural networks remains a challenge. On the one hand, some approaches improve out-of-distribution detection at the cost of reducing classification accuracy in some situations. On the other hand, some methods simultaneously increase classification accuracy, uncertainty estimation, and out-of-distribution detection at the expense of reducing the inference efficiency and requiring training the same model many times to tune hyperparameters. In this paper, we propose training deterministic neural networks using our DisMax loss, which works as a drop-in replacement for the usual SoftMax loss (i.e., the combination of the linear output layer, the SoftMax activation, and the cross-entropy loss). Starting from the IsoMax+ loss, we create each logit based on the distances to all prototypes rather than just the one associated with the correct class. We also introduce a mechanism to combine images to construct what we call fractional probability regularization. Moreover, we present a fast way to calibrate the network after training. Finally, we propose a composite score to perform out-of-distribution detection. Our experiments show that DisMax usually outperforms current approaches simultaneously in classification accuracy, uncertainty estimation, and out-of-distribution detection while maintaining deterministic neural network inference efficiency and avoiding training the same model repetitively for hyperparameter tuning. The code to reproduce the results is available at https://github.com/dlmacedo/distinction-maximization-loss.
ASL-Skeleton3D and ASL-Phono: Two Novel Datasets for the American Sign Language
Jan 06, 2022
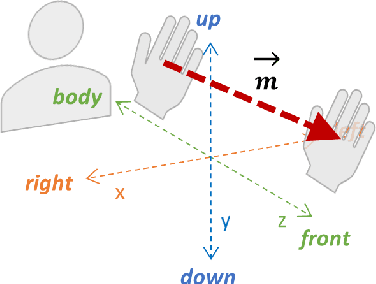
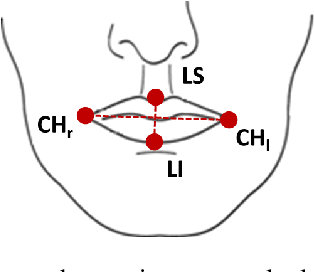
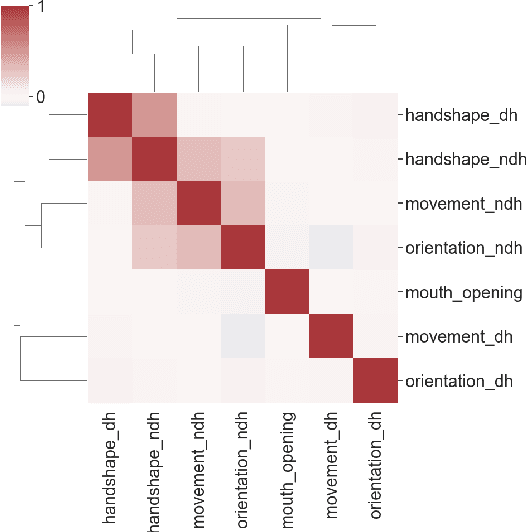
Sign language is an essential resource enabling access to communication and proper socioemotional development for individuals suffering from disabling hearing loss. As this population is expected to reach 700 million by 2050, the importance of the language becomes even more essential as it plays a critical role to ensure the inclusion of such individuals in society. The Sign Language Recognition field aims to bridge the gap between users and non-users of sign languages. However, the scarcity in quantity and quality of datasets is one of the main challenges limiting the exploration of novel approaches that could lead to significant advancements in this research area. Thus, this paper contributes by introducing two new datasets for the American Sign Language: the first is composed of the three-dimensional representation of the signers and, the second, by an unprecedented linguistics-based representation containing a set of phonological attributes of the signs.
Multi-Cue Adaptive Emotion Recognition Network
Nov 03, 2021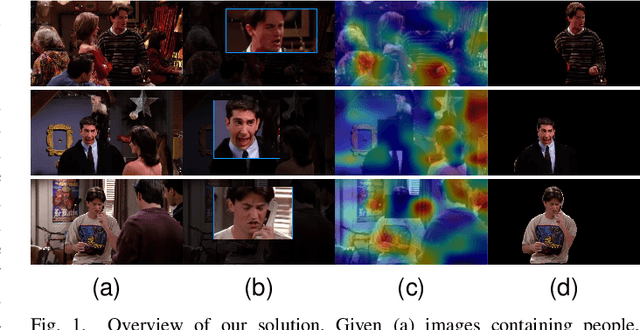
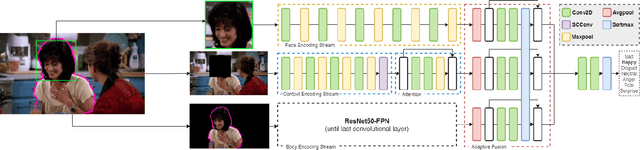
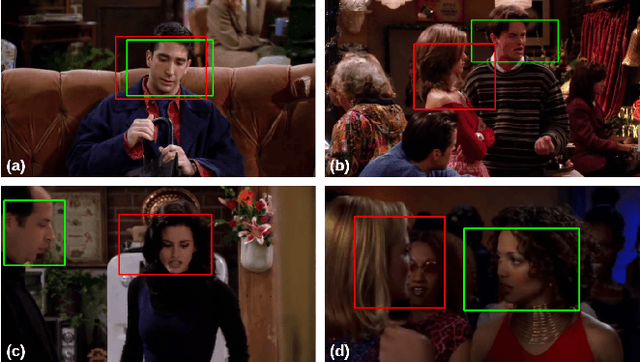

Expressing and identifying emotions through facial and physical expressions is a significant part of social interaction. Emotion recognition is an essential task in computer vision due to its various applications and mainly for allowing a more natural interaction between humans and machines. The common approaches for emotion recognition focus on analyzing facial expressions and requires the automatic localization of the face in the image. Although these methods can correctly classify emotion in controlled scenarios, such techniques are limited when dealing with unconstrained daily interactions. We propose a new deep learning approach for emotion recognition based on adaptive multi-cues that extract information from context and body poses, which humans commonly use in social interaction and communication. We compare the proposed approach with the state-of-art approaches in the CAER-S dataset, evaluating different components in a pipeline that reached an accuracy of 89.30%
On the Impact of Interpretability Methods in Active Image Augmentation Method
Feb 24, 2021
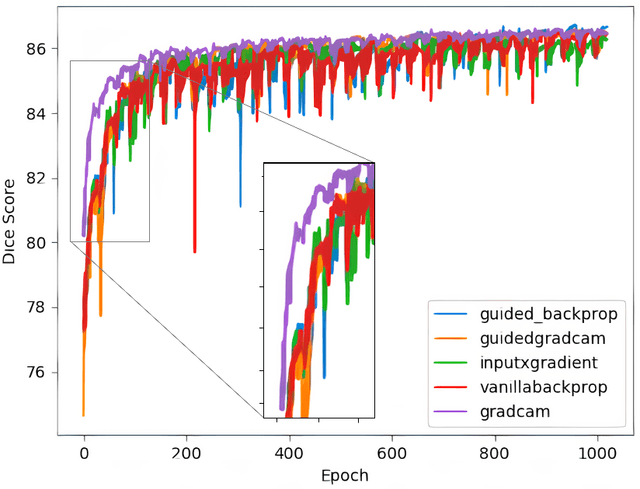
Robustness is a significant constraint in machine learning models. The performance of the algorithms must not deteriorate when training and testing with slightly different data. Deep neural network models achieve awe-inspiring results in a wide range of applications of computer vision. Still, in the presence of noise or region occlusion, some models exhibit inaccurate performance even with data handled in training. Besides, some experiments suggest deep learning models sometimes use incorrect parts of the input information to perform inference. Activate Image Augmentation (ADA) is an augmentation method that uses interpretability methods to augment the training data and improve its robustness to face the described problems. Although ADA presented interesting results, its original version only used the Vanilla Backpropagation interpretability to train the U-Net model. In this work, we propose an extensive experimental analysis of the interpretability method's impact on ADA. We use five interpretability methods: Vanilla Backpropagation, Guided Backpropagation, GradCam, Guided GradCam, and InputXGradient. The results show that all methods achieve similar performance at the ending of training, but when combining ADA with GradCam, the U-Net model presented an impressive fast convergence.
* published in Logic Journal of the IGPL (2021)
Training Aware Sigmoidal Optimizer
Feb 17, 2021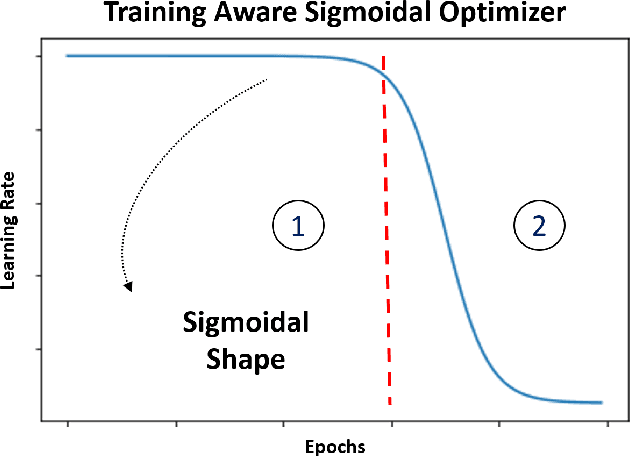

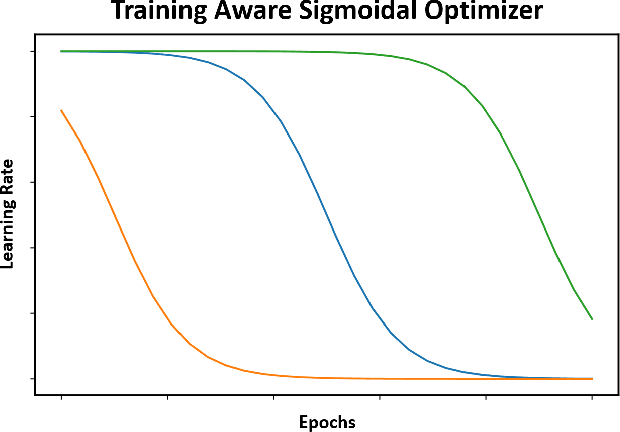
Proper optimization of deep neural networks is an open research question since an optimal procedure to change the learning rate throughout training is still unknown. Manually defining a learning rate schedule involves troublesome time-consuming try and error procedures to determine hyperparameters such as learning rate decay epochs and learning rate decay rates. Although adaptive learning rate optimizers automatize this process, recent studies suggest they may produce overffiting and reduce performance when compared to fine-tuned learning rate schedules. Considering that deep neural networks loss functions present landscapes with much more saddle points than local minima, we proposed the Training Aware Sigmoidal Optimizer (TASO), which consists of a two-phases automated learning rate schedule. The first phase uses a high learning rate to fast traverse the numerous saddle point, while the second phase uses low learning rate to slowly approach the center of the local minimum previously found. We compared the proposed approach with commonly used adaptive learning rate schedules such as Adam, RMSProp, and Adagrad. Our experiments showed that TASO outperformed all competing methods in both optimal (i.e., performing hyperparameter validation) and suboptimal (i.e., using default hyperparameters) scenarios.
KutralNet: A Portable Deep Learning Model for Fire Recognition
Aug 16, 2020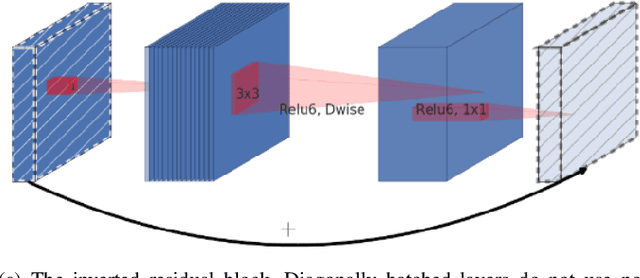
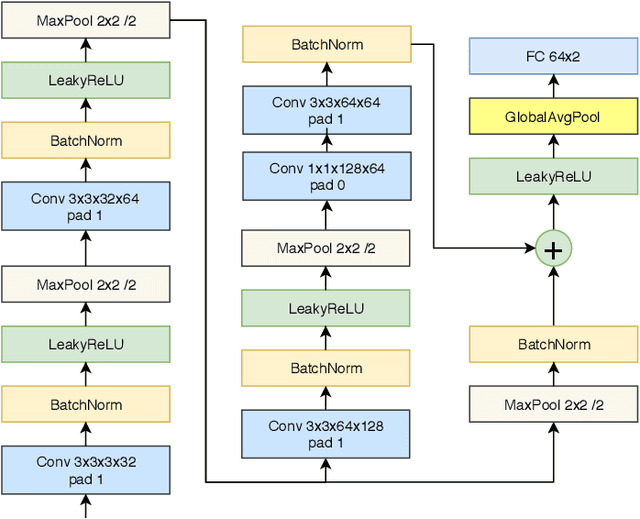
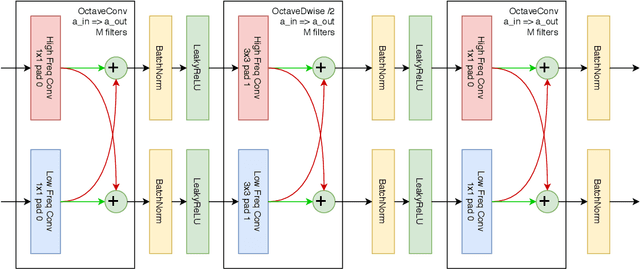
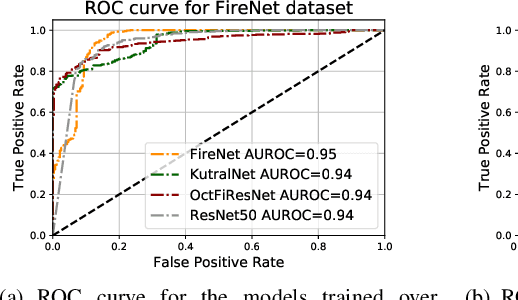
Most of the automatic fire alarm systems detect the fire presence through sensors like thermal, smoke, or flame. One of the new approaches to the problem is the use of images to perform the detection. The image approach is promising since it does not need specific sensors and can be easily embedded in different devices. However, besides the high performance, the computational cost of the used deep learning methods is a challenge to their deployment in portable devices. In this work, we propose a new deep learning architecture that requires fewer floating-point operations (flops) for fire recognition. Additionally, we propose a portable approach for fire recognition and the use of modern techniques such as inverted residual block, convolutions like depth-wise, and octave, to reduce the model's computational cost. The experiments show that our model keeps high accuracy while substantially reducing the number of parameters and flops. One of our models presents 71\% fewer parameters than FireNet, while still presenting competitive accuracy and AUROC performance. The proposed methods are evaluated on FireNet and FiSmo datasets. The obtained results are promising for the implementation of the model in a mobile device, considering the reduced number of flops and parameters acquired.