 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards General Urban Monitoring with Vision-Language Models: A Review, Evaluation, and a Research Agenda
Oct 14, 2025Urban monitoring of public infrastructure (such as waste bins, road signs, vegetation, sidewalks, and construction sites) poses significant challenges due to the diversity of objects, environments, and contextual conditions involved. Current state-of-the-art approaches typically rely on a combination of IoT sensors and manual inspections, which are costly, difficult to scale, and often misaligned with citizens' perception formed through direct visual observation. This raises a critical question: Can machines now "see" like citizens and infer informed opinions about the condition of urban infrastructure? Vision-Language Models (VLMs), which integrate visual understanding with natural language reasoning, have recently demonstrated impressive capabilities in processing complex visual information, turning them into a promising technology to address this challenge. This systematic review investigates the role of VLMs in urban monitoring, with particular emphasis on zero-shot applications. Following the PRISMA methodology, we analyzed 32 peer-reviewed studies published between 2021 and 2025 to address four core research questions: (1) What urban monitoring tasks have been effectively addressed using VLMs? (2) Which VLM architectures and frameworks are most commonly used and demonstrate superior performance? (3) What datasets and resources support this emerging field? (4) How are VLM-based applications evaluated, and what performance levels have been reported?
The Impact of Artificial Intelligence on Emergency Medicine: A Review of Recent Advances
Mar 17, 2025Artificial Intelligence (AI) is revolutionizing emergency medicine by enhancing diagnostic processes and improving patient outcomes. This article provides a review of the current applications of AI in emergency imaging studies, focusing on the last five years of advancements. AI technologies, particularly machine learning and deep learning, are pivotal in interpreting complex imaging data, offering rapid, accurate diagnoses and potentially surpassing traditional diagnostic methods. Studies highlighted within the article demonstrate AI's capabilities in accurately detecting conditions such as fractures, pneumothorax, and pulmonary diseases from various imaging modalities including X-rays, CT scans, and MRIs. Furthermore, AI's ability to predict clinical outcomes like mechanical ventilation needs illustrates its potential in crisis resource optimization. Despite these advancements, the integration of AI into clinical practice presents challenges such as data privacy, algorithmic bias, and the need for extensive validation across diverse settings. This review underscores the transformative potential of AI in emergency settings, advocating for a future where AI and clinical expertise synergize to elevate patient care standards.
Fair Overlap Number of Balls (Fair-ONB): A Data-Morphology-based Undersampling Method for Bias Reduction
Jul 19, 2024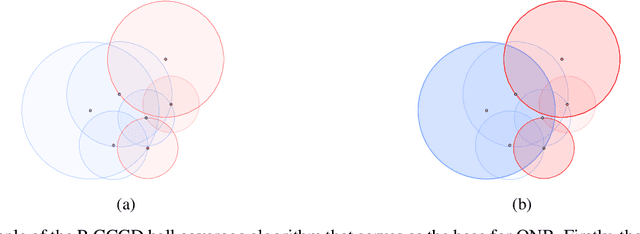
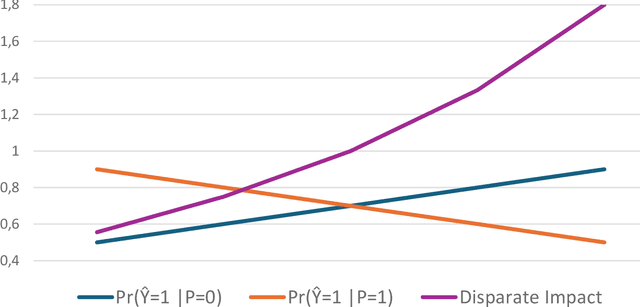
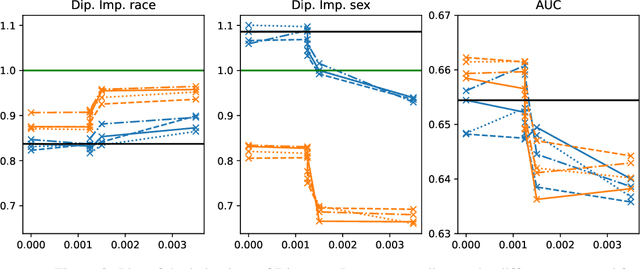
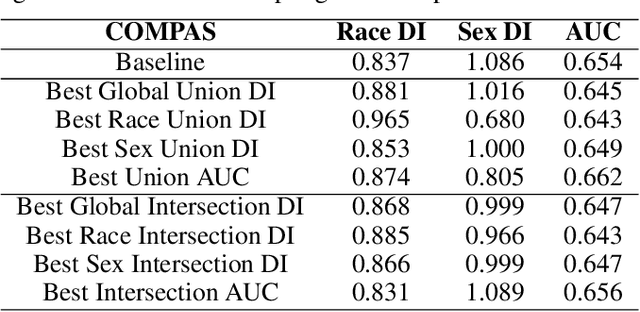
Given the magnitude of data generation currently, both in quantity and speed, the use of machine learning is increasingly important. When data include protected features that might give rise to discrimination, special care must be taken. Data quality is critical in these cases, as biases in training data can be reflected in classification models. This has devastating consequences and fails to comply with current regulations. Data-Centric Artificial Intelligence proposes dataset modifications to improve its quality. Instance selection via undersampling can foster balanced learning of classes and protected feature values in the classifier. When such undersampling is done close to the decision boundary, the effect on the classifier would be bolstered. This work proposes Fair Overlap Number of Balls (Fair-ONB), an undersampling method that harnesses the data morphology of the different data groups (obtained from the combination of classes and protected feature values) to perform guided undersampling in the areas where they overlap. It employs attributes of the ball coverage of the groups, such as the radius, number of covered instances and density, to select the most suitable areas for undersampling and reduce bias. Results show that the Fair-ONB method reduces bias with low impact on the classifier's predictive performance.
On the Impact of Interpretability Methods in Active Image Augmentation Method
Feb 24, 2021
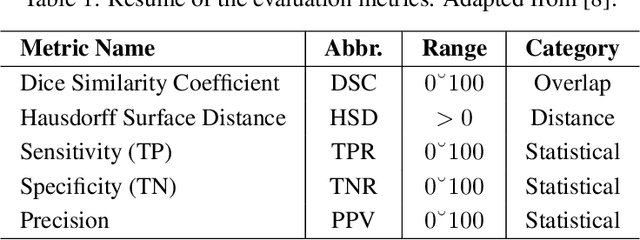
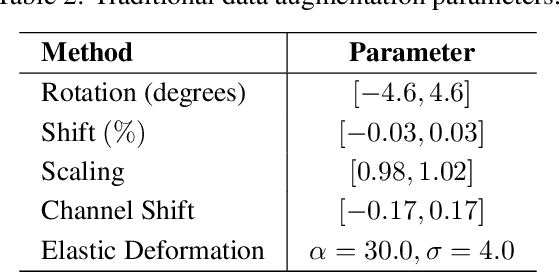
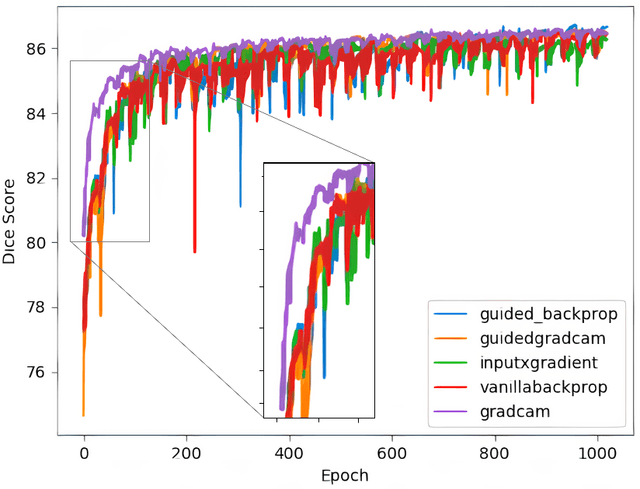
Robustness is a significant constraint in machine learning models. The performance of the algorithms must not deteriorate when training and testing with slightly different data. Deep neural network models achieve awe-inspiring results in a wide range of applications of computer vision. Still, in the presence of noise or region occlusion, some models exhibit inaccurate performance even with data handled in training. Besides, some experiments suggest deep learning models sometimes use incorrect parts of the input information to perform inference. Activate Image Augmentation (ADA) is an augmentation method that uses interpretability methods to augment the training data and improve its robustness to face the described problems. Although ADA presented interesting results, its original version only used the Vanilla Backpropagation interpretability to train the U-Net model. In this work, we propose an extensive experimental analysis of the interpretability method's impact on ADA. We use five interpretability methods: Vanilla Backpropagation, Guided Backpropagation, GradCam, Guided GradCam, and InputXGradient. The results show that all methods achieve similar performance at the ending of training, but when combining ADA with GradCam, the U-Net model presented an impressive fast convergence.
* published in Logic Journal of the IGPL (2021)