 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Value Systems of Agents with Preference-based and Inverse Reinforcement Learning
Feb 04, 2026Agreement Technologies refer to open computer systems in which autonomous software agents interact with one another, typically on behalf of humans, in order to come to mutually acceptable agreements. With the advance of AI systems in recent years, it has become apparent that such agreements, in order to be acceptable to the involved parties, must remain aligned with ethical principles and moral values. However, this is notoriously difficult to ensure, especially as different human users (and their software agents) may hold different value systems, i.e. they may differently weigh the importance of individual moral values. Furthermore, it is often hard to specify the precise meaning of a value in a particular context in a computational manner. Methods to estimate value systems based on human-engineered specifications, e.g. based on value surveys, are limited in scale due to the need for intense human moderation. In this article, we propose a novel method to automatically \emph{learn} value systems from observations and human demonstrations. In particular, we propose a formal model of the \emph{value system learning} problem, its instantiation to sequential decision-making domains based on multi-objective Markov decision processes, as well as tailored preference-based and inverse reinforcement learning algorithms to infer value grounding functions and value systems. The approach is illustrated and evaluated by two simulated use cases.
* 42 pages, 5 figures. Published in Journal of Autonomous Agents and Multi-Agent Systems
Fair Overlap Number of Balls (Fair-ONB): A Data-Morphology-based Undersampling Method for Bias Reduction
Jul 19, 2024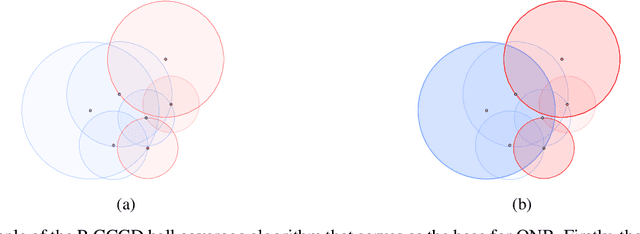
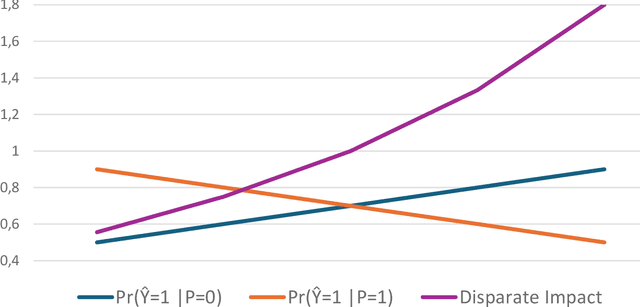
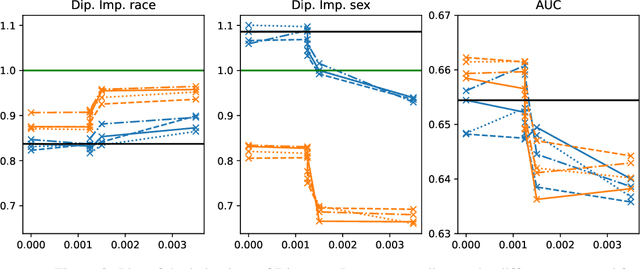
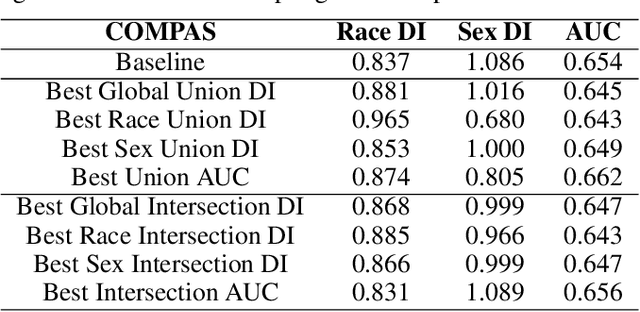
Given the magnitude of data generation currently, both in quantity and speed, the use of machine learning is increasingly important. When data include protected features that might give rise to discrimination, special care must be taken. Data quality is critical in these cases, as biases in training data can be reflected in classification models. This has devastating consequences and fails to comply with current regulations. Data-Centric Artificial Intelligence proposes dataset modifications to improve its quality. Instance selection via undersampling can foster balanced learning of classes and protected feature values in the classifier. When such undersampling is done close to the decision boundary, the effect on the classifier would be bolstered. This work proposes Fair Overlap Number of Balls (Fair-ONB), an undersampling method that harnesses the data morphology of the different data groups (obtained from the combination of classes and protected feature values) to perform guided undersampling in the areas where they overlap. It employs attributes of the ball coverage of the groups, such as the radius, number of covered instances and density, to select the most suitable areas for undersampling and reduce bias. Results show that the Fair-ONB method reduces bias with low impact on the classifier's predictive performance.
Overlap Number of Balls Model-Agnostic CounterFactuals (ONB-MACF): A Data-Morphology-based Counterfactual Generation Method for Trustworthy Artificial Intelligence
May 20, 2024Explainable Artificial Intelligence (XAI) is a pivotal research domain aimed at understanding the operational mechanisms of AI systems, particularly those considered ``black boxes'' due to their complex, opaque nature. XAI seeks to make these AI systems more understandable and trustworthy, providing insight into their decision-making processes. By producing clear and comprehensible explanations, XAI enables users, practitioners, and stakeholders to trust a model's decisions. This work analyses the value of data morphology strategies in generating counterfactual explanations. It introduces the Overlap Number of Balls Model-Agnostic CounterFactuals (ONB-MACF) method, a model-agnostic counterfactual generator that leverages data morphology to estimate a model's decision boundaries. The ONB-MACF method constructs hyperspheres in the data space whose covered points share a class, mapping the decision boundary. Counterfactuals are then generated by incrementally adjusting an instance's attributes towards the nearest alternate-class hypersphere, crossing the decision boundary with minimal modifications. By design, the ONB-MACF method generates feasible and sparse counterfactuals that follow the data distribution. Our comprehensive benchmark from a double perspective (quantitative and qualitative) shows that the ONB-MACF method outperforms existing state-of-the-art counterfactual generation methods across multiple quality metrics on diverse tabular datasets. This supports our hypothesis, showcasing the potential of data-morphology-based explainability strategies for trustworthy AI.
Smart Recommendations for Renting Bikes in Bike Sharing Systems
Jan 22, 2024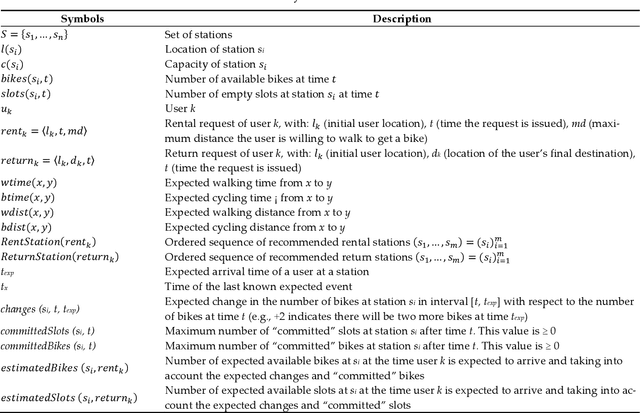
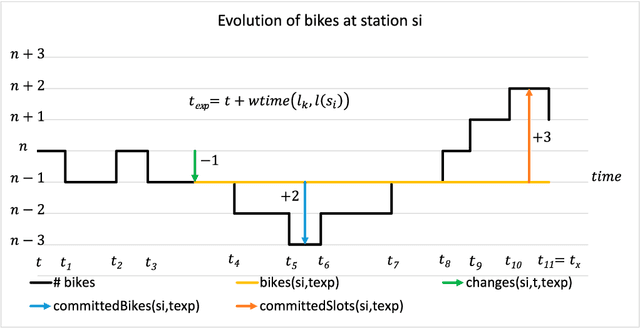

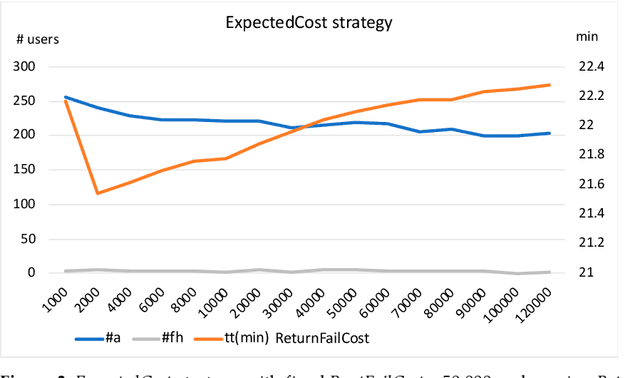
Vehicle-sharing systems -- such as bike-, car-, or motorcycle-sharing systems -- have become increasingly popular in big cities in recent years. On the one hand, they provide a cheaper and environmentally friendlier means of transportation than private cars, and on the other hand, they satisfy the individual mobility demands of citizens better than traditional public transport systems. One of their advantages in this regard is their availability, e.g., the possibility of taking (or leaving) a vehicle almost anywhere in a city. This availability obviously depends on different strategic and operational management decisions and policies, such as the dimension of the fleet or the (re)distribution of vehicles. Agglutination problems -- where, due to usage patterns, available vehicles are concentrated in certain areas, whereas no vehicles are available in others -- are quite common in such systems, and need to be dealt with. Research has been dedicated to this problem, specifying different techniques to reduce imbalanced situations. In this paper, we present and compare strategies for recommending stations to users who wish to rent or return bikes in station-based bike-sharing systems. Our first contribution is a novel recommendation strategy based on queuing theory that recommends stations based on their utility to the user in terms of lower distance and higher probability of finding a bike or slot. Then, we go one step further, defining a strategy that recommends stations by combining the utility of a particular user with the utility of the global system, measured in terms of the improvement in the distribution of bikes and slots with respect to the expected future demand, with the aim of implicitly avoiding or alleviating balancing problems. We present several experiments to evaluate our proposal with real data from the bike sharing system BiciMAD in Madrid.
Towards a prioritised use of transportation infrastructures: the case of vehicle-specific dynamic access restrictions to city centres
Jan 22, 2024One of the main problems that local authorities of large cities have to face is the regulation of urban mobility. They need to provide the means to allow for the efficient movement of people and distribution of goods. However, the provisioning of transportation services needs to take into account general global objectives, like reducing emissions and having more healthy living environments, which may not always be aligned with individual interests. Urban mobility is usually provided through a transport infrastructure that includes all the elements that support mobility. On many occasions, the capacity of the elements of this infrastructure is lower than the actual demand and thus different transportation activities compete for their use. In this paper, we argue that scarce transport infrastructure elements should be assigned dynamically and in a prioritised manner to transport activities that have a higher utility from the point of view of society; for example, activities that produce less pollution and provide more value to society. In this paper, we define a general model for prioritizing the use of a particular type of transportation infrastructure element called time-unlimited elements, whose usage time is unknown a priori, and illustrate its dynamics through two use cases: vehicle-specific dynamic access restriction in city centres (i) based on the usage levels of available parking spaces and (ii) to assure sustained admissible air quality levels in the city centre. We carry out several experiments using the SUMO traffic simulation tool to evaluate our proposal.
Streamlining Advanced Taxi Assignment Strategies based on Legal Analysis
Jan 22, 2024In recent years many novel applications have appeared that promote the provision of services and activities in a collaborative manner. The key idea behind such systems is to take advantage of idle or underused capacities of existing resources, in order to provide improved services that assist people in their daily tasks, with additional functionality, enhanced efficiency, and/or reduced cost. Particularly in the domain of urban transportation, many researchers have put forward novel ideas, which are then implemented and evaluated through prototypes that usually draw upon AI methods and tools. However, such proposals also bring up multiple non-technical issues that need to be identified and addressed adequately if such systems are ever meant to be applied to the real world. While, in practice, legal and ethical aspects related to such AI-based systems are seldomly considered in the beginning of the research and development process, we argue that they not only restrict design decisions, but can also help guiding them. In this manuscript, we set out from a prototype of a taxi coordination service that mediates between individual (and autonomous) taxis and potential customers. After representing key aspects of its operation in a semi-structured manner, we analyse its viability from the viewpoint of current legal restrictions and constraints, so as to identify additional non-functional requirements as well as options to address them. Then, we go one step ahead, and actually modify the existing prototype to incorporate the previously identified recommendations. Performing experiments with this improved system helps us identify the most adequate option among several legally admissible alternatives.
Taxi dispatching strategies with compensations
Jan 21, 2024Urban mobility efficiency is of utmost importance in big cities. Taxi vehicles are key elements in daily traffic activity. The advance of ICT and geo-positioning systems has given rise to new opportunities for improving the efficiency of taxi fleets in terms of waiting times of passengers, cost and time for drivers, traffic density, CO2 emissions, etc., by using more informed, intelligent dispatching. Still, the explicit spatial and temporal components, as well as the scale and, in particular, the dynamicity of the problem of pairing passengers and taxis in big towns, render traditional approaches for solving standard assignment problem useless for this purpose, and call for intelligent approximation strategies based on domain-specific heuristics. Furthermore, taxi drivers are often autonomous actors and may not agree to participate in assignments that, though globally efficient, may not be sufficently beneficial for them individually. This paper presents a new heuristic algorithm for taxi assignment to customers that considers taxi reassignments if this may lead to globally better solutions. In addition, as such new assignments may reduce the expected revenues of individual drivers, we propose an economic compensation scheme to make individually rational drivers agree to proposed modifications in their assigned clients. We carried out a set of experiments, where several commonly used assignment strategies are compared to three different instantiations of our heuristic algorithm. The results indicate that our proposal has the potential to reduce customer waiting times in fleets of autonomous taxis, while being also beneficial from an economic point of view.
Agreement Technologies for Coordination in Smart Cities
Jan 21, 2024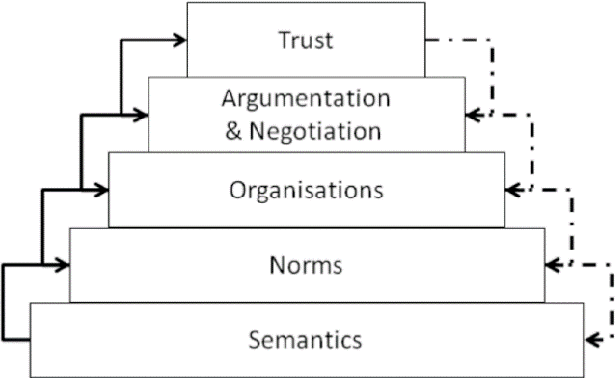
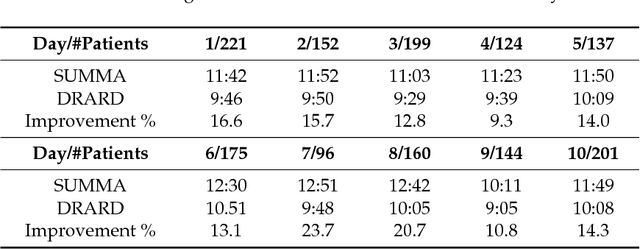
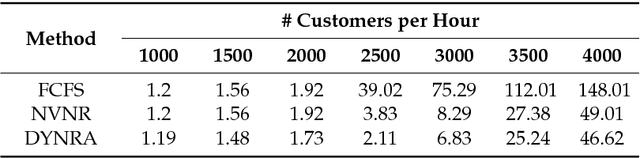
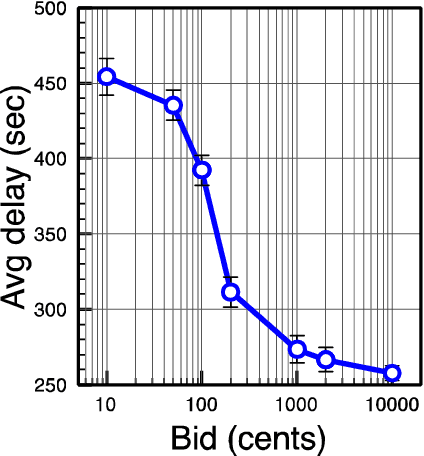
Many challenges in today's society can be tackled by distributed open systems. This is particularly true for domains that are commonly perceived under the umbrella of smart cities, such as intelligent transportation, smart energy grids, or participative governance. When designing computer applications for these domains, it is necessary to account for the fact that the elements of such systems, often called software agents, are usually made by different designers and act on behalf of particular stakeholders. Furthermore, it is unknown at design time when such agents will enter or leave the system, and what interests new agents will represent. To instil coordination in such systems is particularly demanding, as usually only part of them can be directly controlled at runtime. Agreement technologies refer to a sandbox of tools and mechanisms for the development of such open multiagent systems, which are based on the notion of agreement. In this paper, we argue that agreement technologies are a suitable means for achieving coordination in smart city domains, and back our claim through examples of several real-world applications.
Legal and ethical implications of applications based on agreement technologies: the case of auction-based road intersections
Jan 18, 2024Agreement Technologies refer to a novel paradigm for the construction of distributed intelligent systems, where autonomous software agents negotiate to reach agreements on behalf of their human users. Smart Cities are a key application domain for Agreement Technologies. While several proofs of concept and prototypes exist, such systems are still far from ready for being deployed in the real-world. In this paper we focus on a novel method for managing elements of smart road infrastructures of the future, namely the case of auction-based road intersections. We show that, even though the key technological elements for such methods are already available, there are multiple non-technical issues that need to be tackled before they can be applied in practice. For this purpose, we analyse legal and ethical implications of auction-based road intersections in the context of international regulations and from the standpoint of the Spanish legislation. From this exercise, we extract a set of required modifications, of both technical and legal nature, which need to be addressed so as to pave the way for the potential real-world deployment of such systems in a future that may not be too far away.
mdendro: An R package for extended agglomerative hierarchical clustering
Sep 23, 2023"mdendro" is an R package that provides a comprehensive collection of linkage methods for agglomerative hierarchical clustering on a matrix of proximity data (distances or similarities), returning a multifurcated dendrogram or multidendrogram. Multidendrograms can group more than two clusters at the same time, solving the nonuniqueness problem that arises when there are ties in the data. This problem causes that different binary dendrograms are possible depending both on the order of the input data and on the criterion used to break ties. Weighted and unweighted versions of the most common linkage methods are included in the package, which also implements two parametric linkage methods. In addition, package "mdendro" provides five descriptive measures to analyze the resulting dendrograms: cophenetic correlation coefficient, space distortion ratio, agglomerative coefficient, chaining coefficient and tree balance.