 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgoaling Relaxation-based Heuristics for Numeric Planning with Infinite Actions
Dec 26, 2025Numeric planning with control parameters extends the standard numeric planning model by introducing action parameters as free numeric variables that must be instantiated during planning. This results in a potentially infinite number of applicable actions in a state. In this setting, off-the-shelf numeric heuristics that leverage the action structure are not feasible. In this paper, we identify a tractable subset of these problems--namely, controllable, simple numeric problems--and propose an optimistic compilation approach that transforms them into simple numeric tasks. To do so, we abstract control-dependent expressions into bounded constant effects and relaxed preconditions. The proposed compilation makes it possible to effectively use subgoaling heuristics to estimate goal distance in numeric planning problems involving control parameters. Our results demonstrate that this approach is an effective and computationally feasible way of applying traditional numeric heuristics to settings with an infinite number of possible actions, pushing the boundaries of the current state of the art.
Handling Infinite Domain Parameters in Planning Through Best-First Search with Delayed Partial Expansions
Sep 04, 2025In automated planning, control parameters extend standard action representations through the introduction of continuous numeric decision variables. Existing state-of-the-art approaches have primarily handled control parameters as embedded constraints alongside other temporal and numeric restrictions, and thus have implicitly treated them as additional constraints rather than as decision points in the search space. In this paper, we propose an efficient alternative that explicitly handles control parameters as true decision points within a systematic search scheme. We develop a best-first, heuristic search algorithm that operates over infinite decision spaces defined by control parameters and prove a notion of completeness in the limit under certain conditions. Our algorithm leverages the concept of delayed partial expansion, where a state is not fully expanded but instead incrementally expands a subset of its successors. Our results demonstrate that this novel search algorithm is a competitive alternative to existing approaches for solving planning problems involving control parameters.
An Efficient Approach for Cooperative Multi-Agent Learning Problems
Apr 07, 2025In this article, we propose a centralized Multi-Agent Learning framework for learning a policy that models the simultaneous behavior of multiple agents that need to coordinate to solve a certain task. Centralized approaches often suffer from the explosion of an action space that is defined by all possible combinations of individual actions, known as joint actions. Our approach addresses the coordination problem via a sequential abstraction, which overcomes the scalability problems typical to centralized methods. It introduces a meta-agent, called \textit{supervisor}, which abstracts joint actions as sequential assignments of actions to each agent. This sequential abstraction not only simplifies the centralized joint action space but also enhances the framework's scalability and efficiency. Our experimental results demonstrate that the proposed approach successfully coordinates agents across a variety of Multi-Agent Learning environments of diverse sizes.
* Accepted at ICTAI 2024
Meta-operators for Enabling Parallel Planning Using Deep Reinforcement Learning
Mar 13, 2024



There is a growing interest in the application of Reinforcement Learning (RL) techniques to AI planning with the aim to come up with general policies. Typically, the mapping of the transition model of AI planning to the state transition system of a Markov Decision Process is established by assuming a one-to-one correspondence of the respective action spaces. In this paper, we introduce the concept of meta-operator as the result of simultaneously applying multiple planning operators, and we show that including meta-operators in the RL action space enables new planning perspectives to be addressed using RL, such as parallel planning. Our research aims to analyze the performance and complexity of including meta-operators in the RL process, concretely in domains where satisfactory outcomes have not been previously achieved using usual generalized planning models. The main objective of this article is thus to pave the way towards a redefinition of the RL action space in a manner that is more closely aligned with the planning perspective.
Multimodal Classification of Teaching Activities from University Lecture Recordings
Dec 24, 2023The way of understanding online higher education has greatly changed due to the worldwide pandemic situation. Teaching is undertaken remotely, and the faculty incorporate lecture audio recordings as part of the teaching material. This new online teaching-learning setting has largely impacted university classes. While online teaching technology that enriches virtual classrooms has been abundant over the past two years, the same has not occurred in supporting students during online learning. {To overcome this limitation, our aim is to work toward enabling students to easily access the piece of the lesson recording in which the teacher explains a theoretical concept, solves an exercise, or comments on organizational issues of the course. To that end, we present a multimodal classification algorithm that identifies the type of activity that is being carried out at any time of the lesson by using a transformer-based language model that exploits features from the audio file and from the automated lecture transcription. The experimental results will show that some academic activities are more easily identifiable with the audio signal while resorting to the text transcription is needed to identify others. All in all, our contribution aims to recognize the academic activities of a teacher during a lesson.
* 18 pages
Deliberative Context-Aware Ambient Intelligence System for Assisted Living Homes
Sep 16, 2023Monitoring wellbeing and stress is one of the problems covered by ambient intelligence, as stress is a significant cause of human illnesses directly affecting our emotional state. The primary aim was to propose a deliberation architecture for an ambient intelligence healthcare application. The architecture provides a plan for comforting stressed seniors suffering from negative emotions in an assisted living home and executes the plan considering the environment's dynamic nature. Literature was reviewed to identify the convergence between deliberation and ambient intelligence and the latter's latest healthcare trends. A deliberation function was designed to achieve context-aware dynamic human-robot interaction, perception, planning capabilities, reactivity, and context-awareness with regard to the environment. A number of experimental case studies in a simulated assisted living home scenario were conducted to demonstrate the approach's behavior and validity. The proposed methods were validated to show classification accuracy. The validation showed that the deliberation function has effectively achieved its deliberative objectives.
Spillover Algorithm: A Decentralized Coordination Approach for Multi-Robot Production Planning in Open Shared Factories
Jan 23, 2021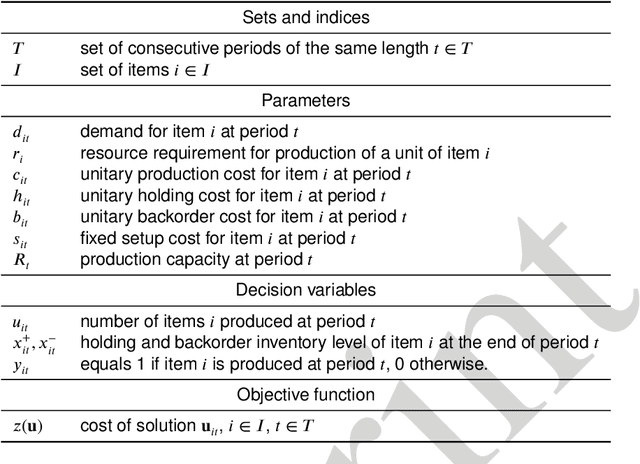
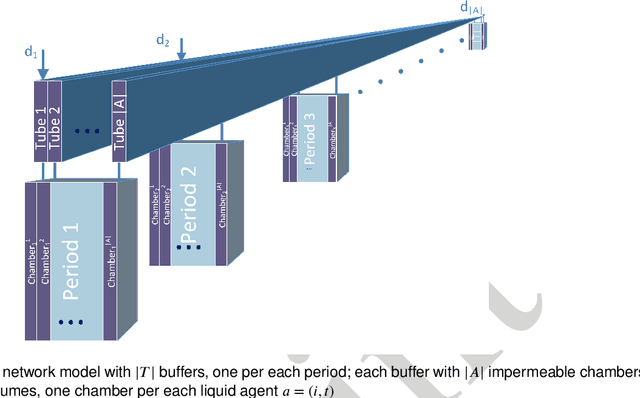

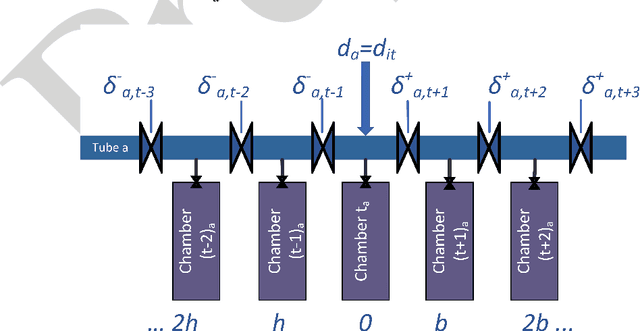
Open and shared manufacturing factories typically dispose of a limited number of robots that should be properly allocated to tasks in time and space for an effective and efficient system performance. In particular, we deal with the dynamic capacitated production planning problem with sequence independent setup costs where quantities of products to manufacture and location of robots need to be determined at consecutive periods within a given time horizon and products can be anticipated or backordered related to the demand period. We consider a decentralized multi-agent variant of this problem in an open factory setting with multiple owners of robots as well as different owners of the items to be produced, both considered self-interested and individually rational. Existing solution approaches to the classic constrained lot-sizing problem are centralized exact methods that require sharing of global knowledge of all the participants' private and sensitive information and are not applicable in the described multi-agent context. Therefore, we propose a computationally efficient decentralized approach based on the spillover effect that solves this NP-hard problem by distributing decisions in an intrinsically decentralized multi-agent system environment while protecting private and sensitive information. To the best of our knowledge, this is the first decentralized algorithm for the solution of the studied problem in intrinsically decentralized environments where production resources and/or products are owned by multiple stakeholders with possibly conflicting objectives. To show its efficiency, the performance of the Spillover Algorithm is benchmarked against state-of-the-art commercial solver CPLEX 12.8.
A context-aware knowledge acquisition for planning applications using ontologies
Apr 19, 2019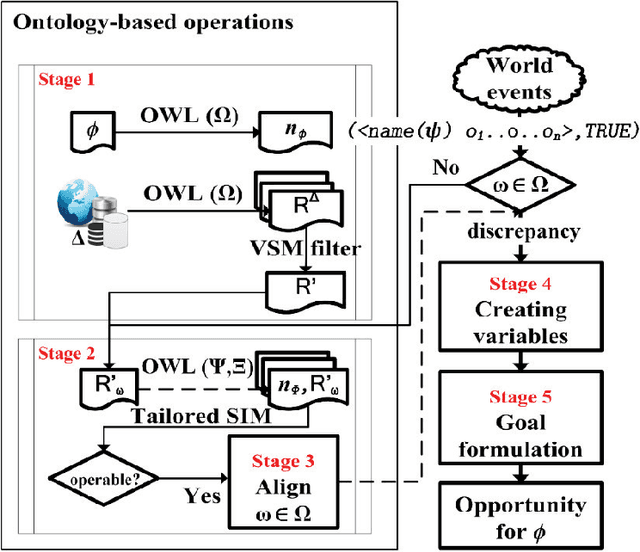
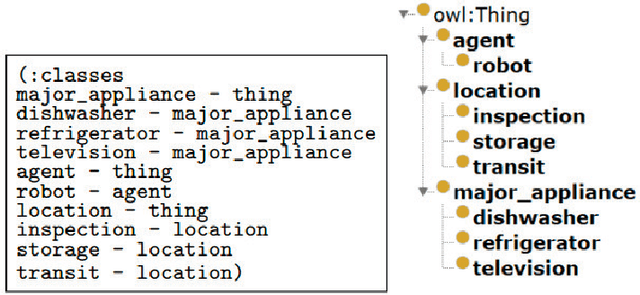
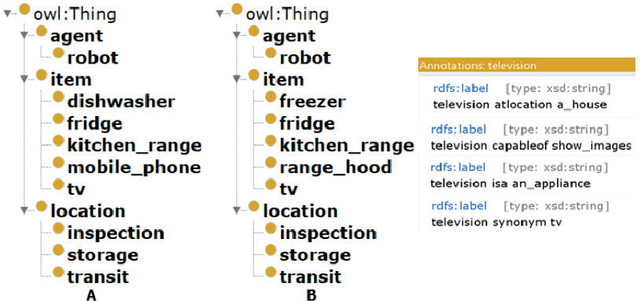

Automated planning technology has developed significantly. Designing a planning model that allows an automated agent to be capable of reacting intelligently to unexpected events in a real execution environment yet remains a challenge. This article describes a domain-independent approach to allow the agent to be context-aware of its execution environment and the task it performs, acquire new information that is guaranteed to be related and more importantly manageable, and integrate such information into its model through the use of ontologies and semantic operations to autonomously formulate new objectives, resulting in a more human-like behaviour for handling unexpected events in the context of opportunities.
* 13 pages, 11 Figures, conference. arXiv admin note: text overlap with arXiv:1904.03606
Extending planning knowledge using ontologies for goal opportunities
Apr 07, 2019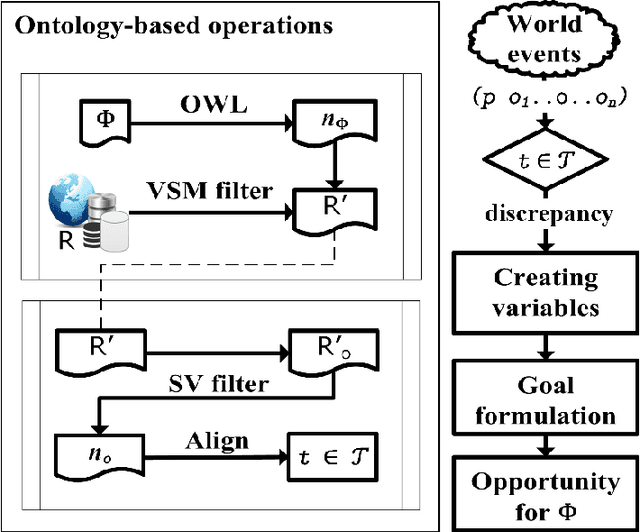


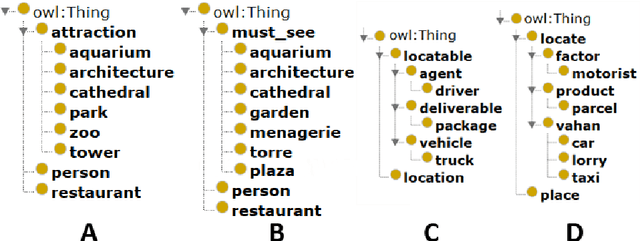
Approaches to goal-directed behaviour including online planning and opportunistic planning tackle a change in the environment by generating alternative goals to avoid failures or seize opportunities. However, current approaches only address unanticipated changes related to objects or object types already defined in the planning task that is being solved. This article describes a domain-independent approach that advances the state of the art by extending the knowledge of a planning task with relevant objects of new types. The approach draws upon the use of ontologies, semantic measures, and ontology alignment to accommodate newly acquired data that trigger the formulation of goal opportunities inducing a better-valued plan.
* 10 pages, 8 Figures, 31st International-Business-Information-Management-Association Conference, Milan ITALY, date: APR 25-26, 2018
Learning STRIPS Action Models with Classical Planning
Mar 04, 2019
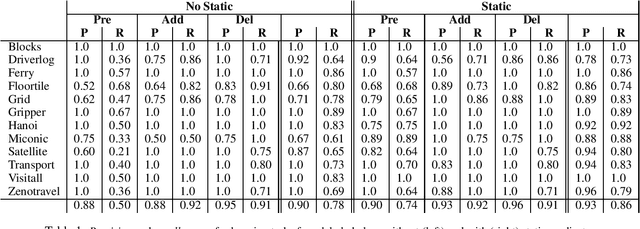

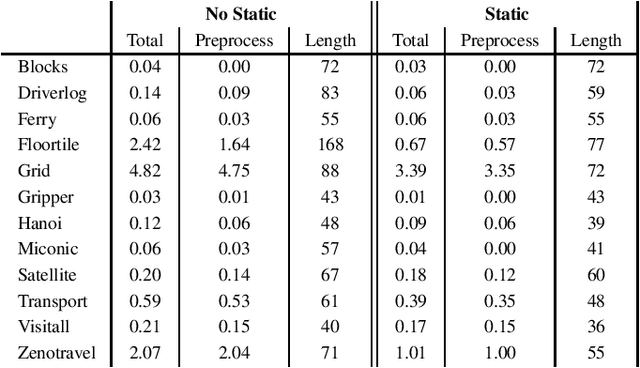
This paper presents a novel approach for learning STRIPS action models from examples that compiles this inductive learning task into a classical planning task. Interestingly, the compilation approach is flexible to different amounts of available input knowledge; the learning examples can range from a set of plans (with their corresponding initial and final states) to just a pair of initial and final states (no intermediate action or state is given). Moreover, the compilation accepts partially specified action models and it can be used to validate whether the observation of a plan execution follows a given STRIPS action model, even if this model is not fully specified.
* 8+1 pages, 4 figures, 6 tables