 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Overlap Number of Balls (Fair-ONB): A Data-Morphology-based Undersampling Method for Bias Reduction
Paper and Code
Jul 19, 2024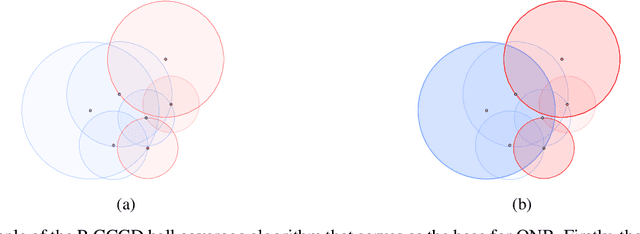
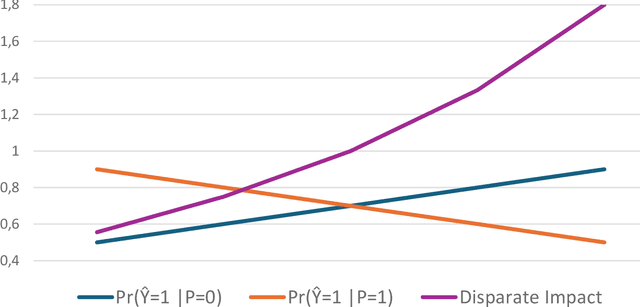
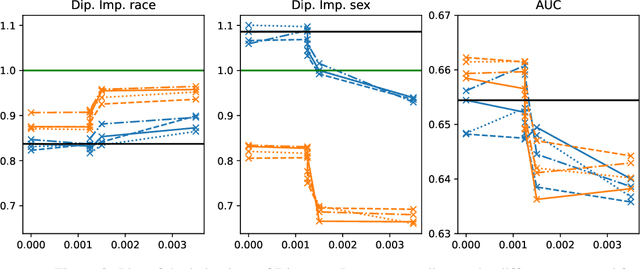
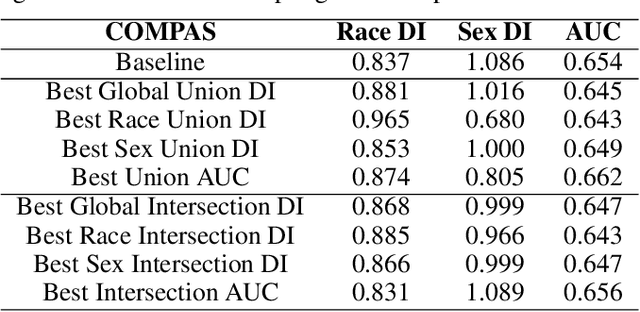
Given the magnitude of data generation currently, both in quantity and speed, the use of machine learning is increasingly important. When data include protected features that might give rise to discrimination, special care must be taken. Data quality is critical in these cases, as biases in training data can be reflected in classification models. This has devastating consequences and fails to comply with current regulations. Data-Centric Artificial Intelligence proposes dataset modifications to improve its quality. Instance selection via undersampling can foster balanced learning of classes and protected feature values in the classifier. When such undersampling is done close to the decision boundary, the effect on the classifier would be bolstered. This work proposes Fair Overlap Number of Balls (Fair-ONB), an undersampling method that harnesses the data morphology of the different data groups (obtained from the combination of classes and protected feature values) to perform guided undersampling in the areas where they overlap. It employs attributes of the ball coverage of the groups, such as the radius, number of covered instances and density, to select the most suitable areas for undersampling and reduce bias. Results show that the Fair-ONB method reduces bias with low impact on the classifier's predictive performance.