 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Interpretability Methods in Active Image Augmentation Method
Feb 24, 2021
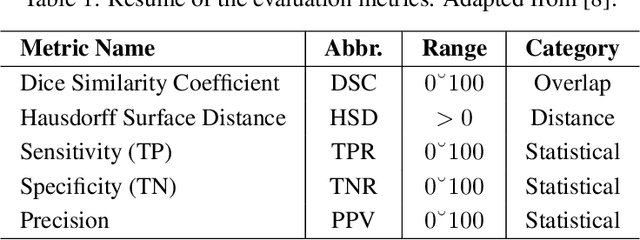
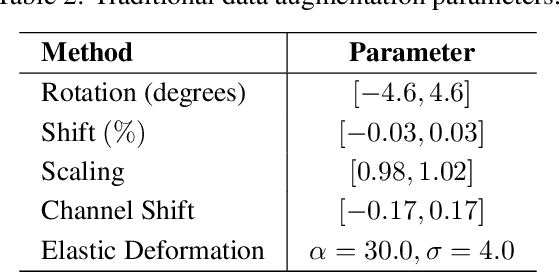
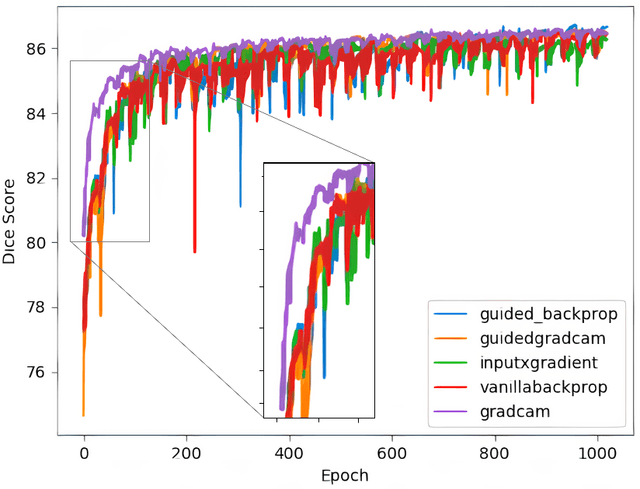
Robustness is a significant constraint in machine learning models. The performance of the algorithms must not deteriorate when training and testing with slightly different data. Deep neural network models achieve awe-inspiring results in a wide range of applications of computer vision. Still, in the presence of noise or region occlusion, some models exhibit inaccurate performance even with data handled in training. Besides, some experiments suggest deep learning models sometimes use incorrect parts of the input information to perform inference. Activate Image Augmentation (ADA) is an augmentation method that uses interpretability methods to augment the training data and improve its robustness to face the described problems. Although ADA presented interesting results, its original version only used the Vanilla Backpropagation interpretability to train the U-Net model. In this work, we propose an extensive experimental analysis of the interpretability method's impact on ADA. We use five interpretability methods: Vanilla Backpropagation, Guided Backpropagation, GradCam, Guided GradCam, and InputXGradient. The results show that all methods achieve similar performance at the ending of training, but when combining ADA with GradCam, the U-Net model presented an impressive fast convergence.
* published in Logic Journal of the IGPL (2021)
Learning to associate detections for real-time multiple object tracking
Jul 12, 2020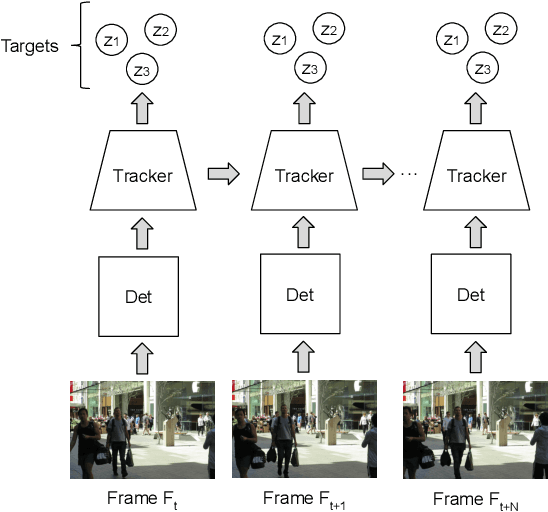
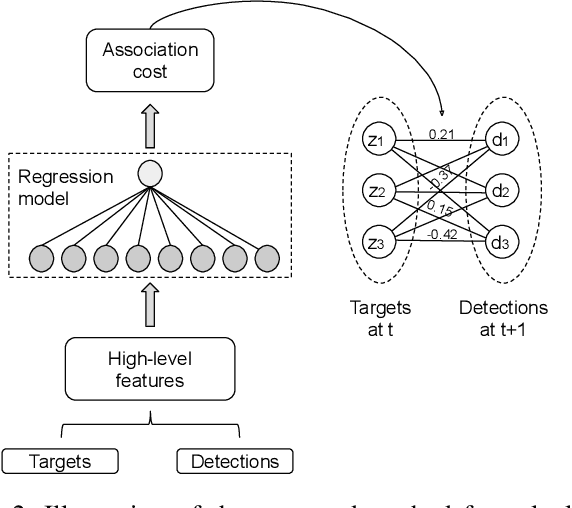
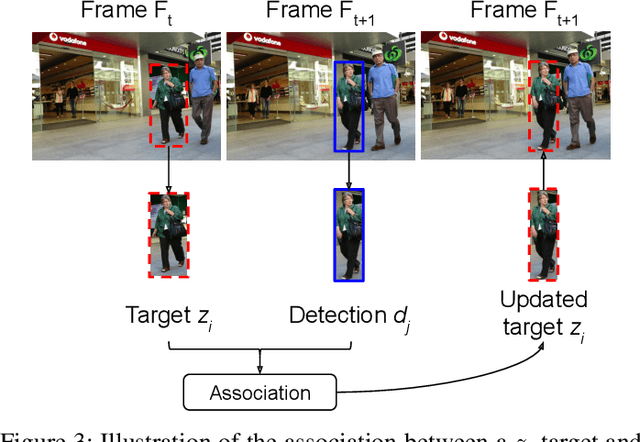
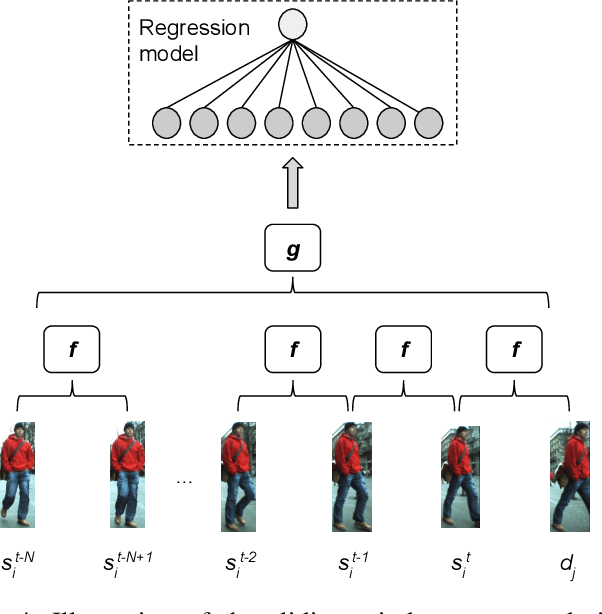
With the recent advances in the object detection research field, tracking-by-detection has become the leading paradigm adopted by multi-object tracking algorithms. By extracting different features from detected objects, those algorithms can estimate the objects' similarities and association patterns along successive frames. However, since similarity functions applied by tracking algorithms are handcrafted, it is difficult to employ them in new contexts. In this study, it is investigated the use of artificial neural networks to learning a similarity function that can be used among detections. During training, the networks were introduced to correct and incorrect association patterns, sampled from a pedestrian tracking data set. For such, different motion and appearance features combinations have been explored. Finally, a trained network has been inserted into a multiple-object tracking framework, which has been assessed on the MOT Challenge benchmark. Throughout the experiments, the proposed tracker matched the results obtained by state-of-the-art methods, it has run 58\% faster than a recent and similar method, used as baseline.