 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphological Skip-Gram: Using morphological knowledge to improve word representation
Jul 21, 2020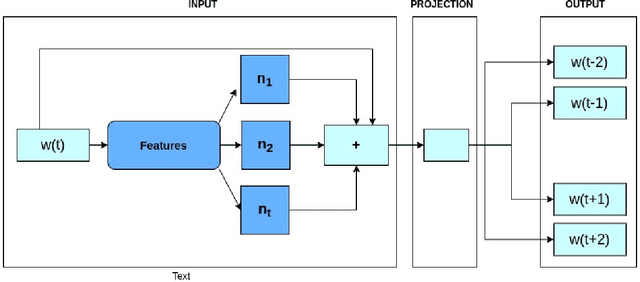
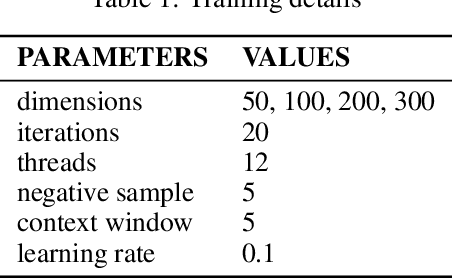

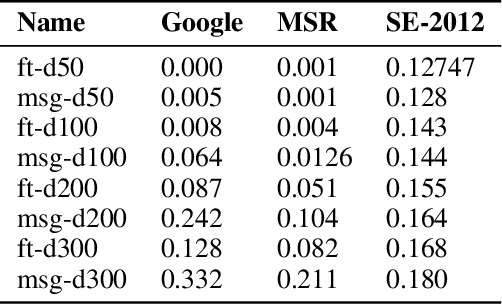
Natural language processing models have attracted much interest in the deep learning community. This branch of study is composed of some applications such as machine translation, sentiment analysis, named entity recognition, question and answer, and others. Word embeddings are continuous word representations, they are an essential module for those applications and are generally used as input word representation to the deep learning models. Word2Vec and GloVe are two popular methods to learn word embeddings. They achieve good word representations, however, they learn representations with limited information because they ignore the morphological information of the words and consider only one representation vector for each word. This approach implies that Word2Vec and GloVe are unaware of the word inner structure. To mitigate this problem, the FastText model represents each word as a bag of characters n-grams. Hence, each n-gram has a continuous vector representation, and the final word representation is the sum of its characters n-grams vectors. Nevertheless, the use of all n-grams character of a word is a poor approach since some n-grams have no semantic relation with their words and increase the amount of potentially useless information. This approach also increases the training phase time. In this work, we propose a new method for training word embeddings, and its goal is to replace the FastText bag of character n-grams for a bag of word morphemes through the morphological analysis of the word. Thus, words with similar context and morphemes are represented by vectors close to each other. To evaluate our new approach, we performed intrinsic evaluations considering 15 different tasks, and the results show a competitive performance compared to FastText.
Learning to associate detections for real-time multiple object tracking
Jul 12, 2020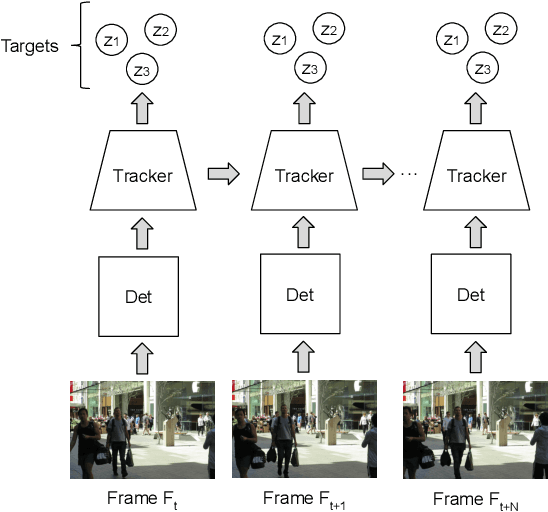
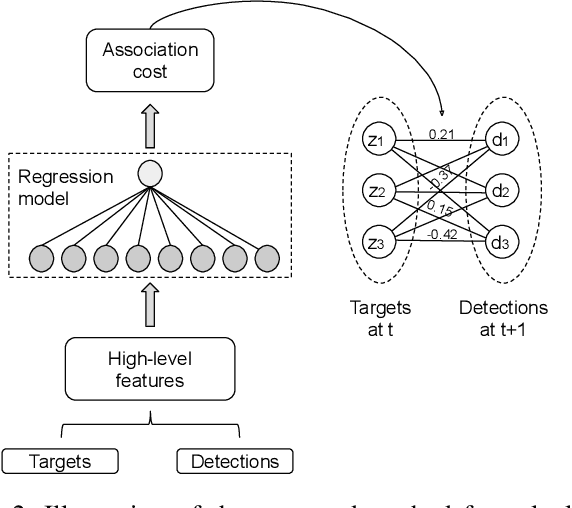
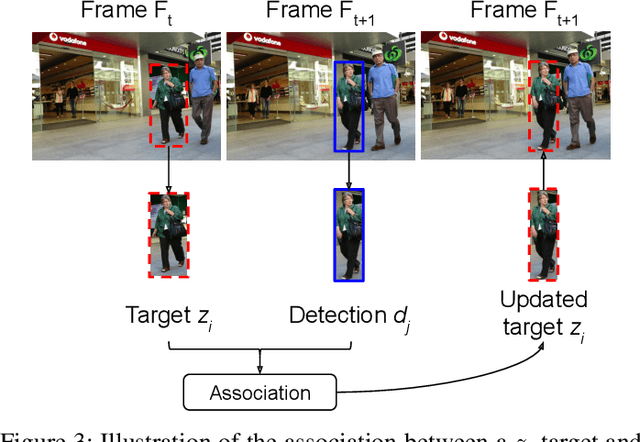
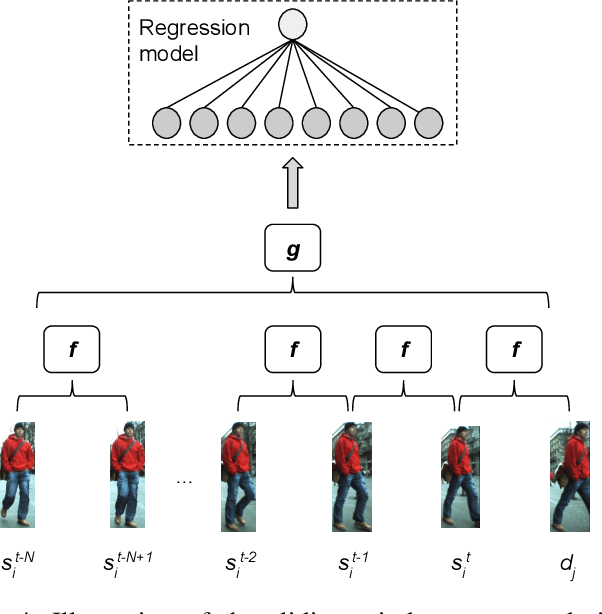
With the recent advances in the object detection research field, tracking-by-detection has become the leading paradigm adopted by multi-object tracking algorithms. By extracting different features from detected objects, those algorithms can estimate the objects' similarities and association patterns along successive frames. However, since similarity functions applied by tracking algorithms are handcrafted, it is difficult to employ them in new contexts. In this study, it is investigated the use of artificial neural networks to learning a similarity function that can be used among detections. During training, the networks were introduced to correct and incorrect association patterns, sampled from a pedestrian tracking data set. For such, different motion and appearance features combinations have been explored. Finally, a trained network has been inserted into a multiple-object tracking framework, which has been assessed on the MOT Challenge benchmark. Throughout the experiments, the proposed tracker matched the results obtained by state-of-the-art methods, it has run 58\% faster than a recent and similar method, used as baseline.