 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Dataset and Framework for Robust Road Surface Classification via Camera-IMU Fusion
Jan 29, 2026Road surface classification (RSC) is a key enabler for environment-aware predictive maintenance systems. However, existing RSC techniques often fail to generalize beyond narrow operational conditions due to limited sensing modalities and datasets that lack environmental diversity. This work addresses these limitations by introducing a multimodal framework that fuses images and inertial measurements using a lightweight bidirectional cross-attention module followed by an adaptive gating layer that adjusts modality contributions under domain shifts. Given the limitations of current benchmarks, especially regarding lack of variability, we introduce ROAD, a new dataset composed of three complementary subsets: (i) real-world multimodal recordings with RGB-IMU streams synchronized using a gold-standard industry datalogger, captured across diverse lighting, weather, and surface conditions; (ii) a large vision-only subset designed to assess robustness under adverse illumination and heterogeneous capture setups; and (iii) a synthetic subset generated to study out-of-distribution generalization in scenarios difficult to obtain in practice. Experiments show that our method achieves a +1.4 pp improvement over the previous state-of-the-art on the PVS benchmark and an +11.6 pp improvement on our multimodal ROAD subset, with consistently higher F1-scores on minority classes. The framework also demonstrates stable performance across challenging visual conditions, including nighttime, heavy rain, and mixed-surface transitions. These findings indicate that combining affordable camera and IMU sensors with multimodal attention mechanisms provides a scalable, robust foundation for road surface understanding, particularly relevant for regions where environmental variability and cost constraints limit the adoption of high-end sensing suites.
VWise: A novel benchmark for evaluating scene classification for vehicular applications
Jun 05, 2024



Current datasets for vehicular applications are mostly collected in North America or Europe. Models trained or evaluated on these datasets might suffer from geographical bias when deployed in other regions. Specifically, for scene classification, a highway in a Latin American country differs drastically from an Autobahn, for example, both in design and maintenance levels. We propose VWise, a novel benchmark for road-type classification and scene classification tasks, in addition to tasks focused on external contexts related to vehicular applications in LatAm. We collected over 520 video clips covering diverse urban and rural environments across Latin American countries, annotated with six classes of road types. We also evaluated several state-of-the-art classification models in baseline experiments, obtaining over 84% accuracy. With this dataset, we aim to enhance research on vehicular tasks in Latin America.
ST-Gait++: Leveraging spatio-temporal convolutions for gait-based emotion recognition on videos
May 22, 2024
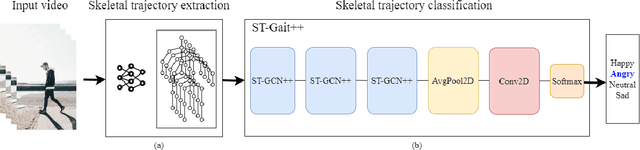
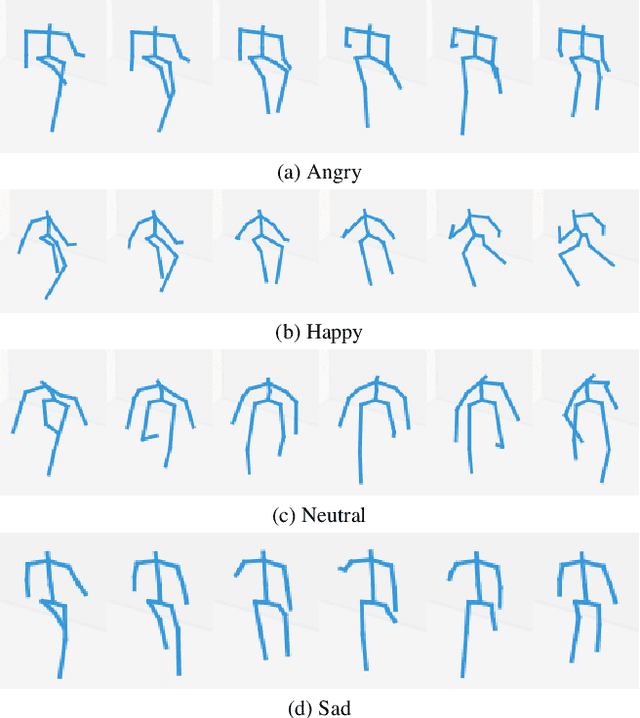

Emotion recognition is relevant for human behaviour understanding, where facial expression and speech recognition have been widely explored by the computer vision community. Literature in the field of behavioural psychology indicates that gait, described as the way a person walks, is an additional indicator of emotions. In this work, we propose a deep framework for emotion recognition through the analysis of gait. More specifically, our model is composed of a sequence of spatial-temporal Graph Convolutional Networks that produce a robust skeleton-based representation for the task of emotion classification. We evaluate our proposed framework on the E-Gait dataset, composed of a total of 2177 samples. The results obtained represent an improvement of approximately 5% in accuracy compared to the state of the art. In addition, during training we observed a faster convergence of our model compared to the state-of-the-art methodologies.
Attention Modules Improve Modern Image-Level Anomaly Detection: A DifferNet Case Study
Jan 13, 2024Within (semi-)automated visual inspection, learning-based approaches for assessing visual defects, including deep neural networks, enable the processing of otherwise small defect patterns in pixel size on high-resolution imagery. The emergence of these often rarely occurring defect patterns explains the general need for labeled data corpora. To not only alleviate this issue but to furthermore advance the current state of the art in unsupervised visual inspection, this contribution proposes a DifferNet-based solution enhanced with attention modules utilizing SENet and CBAM as backbone - AttentDifferNet - to improve the detection and classification capabilities on three different visual inspection and anomaly detection datasets: MVTec AD, InsPLAD-fault, and Semiconductor Wafer. In comparison to the current state of the art, it is shown that AttentDifferNet achieves improved results, which are, in turn, highlighted throughout our quantitative as well as qualitative evaluation, indicated by a general improvement in AUC of 94.34 vs. 92.46, 96.67 vs. 94.69, and 90.20 vs. 88.74%. As our variants to AttentDifferNet show great prospects in the context of currently investigated approaches, a baseline is formulated, emphasizing the importance of attention for anomaly detection.
Leveraging Previous Facial Action Units Knowledge for Emotion Recognition on Faces
Nov 20, 2023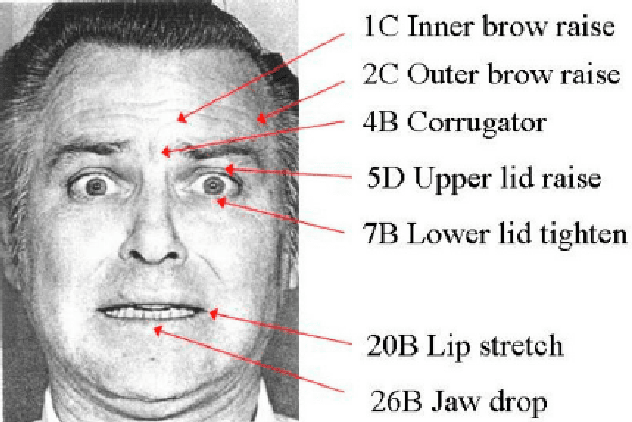
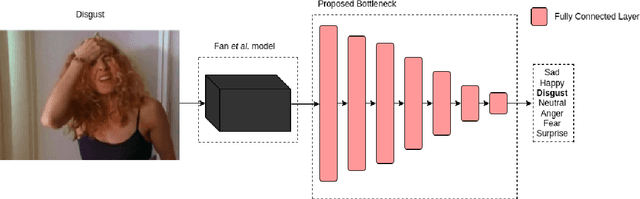


People naturally understand emotions, thus permitting a machine to do the same could open new paths for human-computer interaction. Facial expressions can be very useful for emotion recognition techniques, as these are the biggest transmitters of non-verbal cues capable of being correlated with emotions. Several techniques are based on Convolutional Neural Networks (CNNs) to extract information in a machine learning process. However, simple CNNs are not always sufficient to locate points of interest on the face that can be correlated with emotions. In this work, we intend to expand the capacity of emotion recognition techniques by proposing the usage of Facial Action Units (AUs) recognition techniques to recognize emotions. This recognition will be based on the Facial Action Coding System (FACS) and computed by a machine learning system. In particular, our method expands over EmotiRAM, an approach for multi-cue emotion recognition, in which we improve over their facial encoding module.
Attention Modules Improve Image-Level Anomaly Detection for Industrial Inspection: A DifferNet Case Study
Nov 07, 2023



Within (semi-)automated visual industrial inspection, learning-based approaches for assessing visual defects, including deep neural networks, enable the processing of otherwise small defect patterns in pixel size on high-resolution imagery. The emergence of these often rarely occurring defect patterns explains the general need for labeled data corpora. To alleviate this issue and advance the current state of the art in unsupervised visual inspection, this work proposes a DifferNet-based solution enhanced with attention modules: AttentDifferNet. It improves image-level detection and classification capabilities on three visual anomaly detection datasets for industrial inspection: InsPLAD-fault, MVTec AD, and Semiconductor Wafer. In comparison to the state of the art, AttentDifferNet achieves improved results, which are, in turn, highlighted throughout our quali-quantitative study. Our quantitative evaluation shows an average improvement - compared to DifferNet - of 1.77 +/- 0.25 percentage points in overall AUROC considering all three datasets, reaching SOTA results in InsPLAD-fault, an industrial inspection in-the-wild dataset. As our variants to AttentDifferNet show great prospects in the context of currently investigated approaches, a baseline is formulated, emphasizing the importance of attention for industrial anomaly detection both in the wild and in controlled environments.
InsPLAD: A Dataset and Benchmark for Power Line Asset Inspection in UAV Images
Nov 02, 2023Power line maintenance and inspection are essential to avoid power supply interruptions, reducing its high social and financial impacts yearly. Automating power line visual inspections remains a relevant open problem for the industry due to the lack of public real-world datasets of power line components and their various defects to foster new research. This paper introduces InsPLAD, a Power Line Asset Inspection Dataset and Benchmark containing 10,607 high-resolution Unmanned Aerial Vehicles colour images. The dataset contains seventeen unique power line assets captured from real-world operating power lines. Additionally, five of those assets present six defects: four of which are corrosion, one is a broken component, and one is a bird's nest presence. All assets were labelled according to their condition, whether normal or the defect name found on an image level. We thoroughly evaluate state-of-the-art and popular methods for three image-level computer vision tasks covered by InsPLAD: object detection, through the AP metric; defect classification, through Balanced Accuracy; and anomaly detection, through the AUROC metric. InsPLAD offers various vision challenges from uncontrolled environments, such as multi-scale objects, multi-size class instances, multiple objects per image, intra-class variation, cluttered background, distinct point-of-views, perspective distortion, occlusion, and varied lighting conditions. To the best of our knowledge, InsPLAD is the first large real-world dataset and benchmark for power line asset inspection with multiple components and defects for various computer vision tasks, with a potential impact to improve state-of-the-art methods in the field. It will be publicly available in its integrity on a repository with a thorough description. It can be found at https://github.com/andreluizbvs/InsPLAD.
Toward unlabeled multi-view 3D pedestrian detection by generalizable AI: techniques and performance analysis
Aug 08, 2023



We unveil how generalizable AI can be used to improve multi-view 3D pedestrian detection in unlabeled target scenes. One way to increase generalization to new scenes is to automatically label target data, which can then be used for training a detector model. In this context, we investigate two approaches for automatically labeling target data: pseudo-labeling using a supervised detector and automatic labeling using an untrained detector (that can be applied out of the box without any training). We adopt a training framework for optimizing detector models using automatic labeling procedures. This framework encompasses different training sets/modes and multi-round automatic labeling strategies. We conduct our analyses on the publicly-available WILDTRACK and MultiviewX datasets. We show that, by using the automatic labeling approach based on an untrained detector, we can obtain superior results than directly using the untrained detector or a detector trained with an existing labeled source dataset. It achieved a MODA about 4% and 1% better than the best existing unlabeled method when using WILDTRACK and MultiviewX as target datasets, respectively.
High-Level Context Representation for Emotion Recognition in Images
May 05, 2023



Emotion recognition is the task of classifying perceived emotions in people. Previous works have utilized various nonverbal cues to extract features from images and correlate them to emotions. Of these cues, situational context is particularly crucial in emotion perception since it can directly influence the emotion of a person. In this paper, we propose an approach for high-level context representation extraction from images. The model relies on a single cue and a single encoding stream to correlate this representation with emotions. Our model competes with the state-of-the-art, achieving an mAP of 0.3002 on the EMOTIC dataset while also being capable of execution on consumer-grade hardware at approximately 90 frames per second. Overall, our approach is more efficient than previous models and can be easily deployed to address real-world problems related to emotion recognition.
Multi-Cue Adaptive Emotion Recognition Network
Nov 03, 2021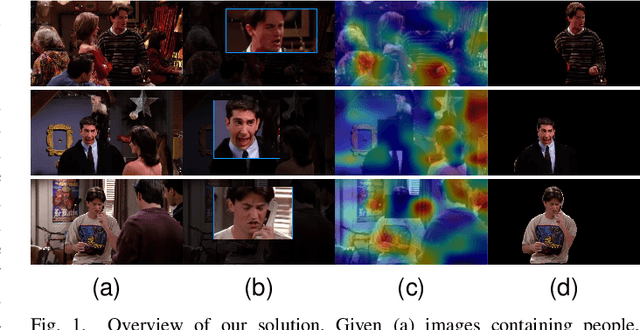
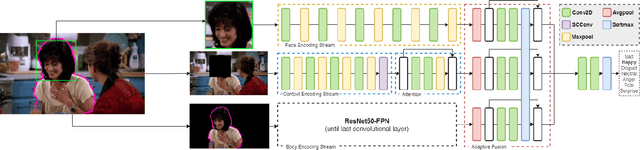

Expressing and identifying emotions through facial and physical expressions is a significant part of social interaction. Emotion recognition is an essential task in computer vision due to its various applications and mainly for allowing a more natural interaction between humans and machines. The common approaches for emotion recognition focus on analyzing facial expressions and requires the automatic localization of the face in the image. Although these methods can correctly classify emotion in controlled scenarios, such techniques are limited when dealing with unconstrained daily interactions. We propose a new deep learning approach for emotion recognition based on adaptive multi-cues that extract information from context and body poses, which humans commonly use in social interaction and communication. We compare the proposed approach with the state-of-art approaches in the CAER-S dataset, evaluating different components in a pipeline that reached an accuracy of 89.30%