 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Modules Improve Modern Image-Level Anomaly Detection: A DifferNet Case Study
Jan 13, 2024Within (semi-)automated visual inspection, learning-based approaches for assessing visual defects, including deep neural networks, enable the processing of otherwise small defect patterns in pixel size on high-resolution imagery. The emergence of these often rarely occurring defect patterns explains the general need for labeled data corpora. To not only alleviate this issue but to furthermore advance the current state of the art in unsupervised visual inspection, this contribution proposes a DifferNet-based solution enhanced with attention modules utilizing SENet and CBAM as backbone - AttentDifferNet - to improve the detection and classification capabilities on three different visual inspection and anomaly detection datasets: MVTec AD, InsPLAD-fault, and Semiconductor Wafer. In comparison to the current state of the art, it is shown that AttentDifferNet achieves improved results, which are, in turn, highlighted throughout our quantitative as well as qualitative evaluation, indicated by a general improvement in AUC of 94.34 vs. 92.46, 96.67 vs. 94.69, and 90.20 vs. 88.74%. As our variants to AttentDifferNet show great prospects in the context of currently investigated approaches, a baseline is formulated, emphasizing the importance of attention for anomaly detection.
Attention Modules Improve Image-Level Anomaly Detection for Industrial Inspection: A DifferNet Case Study
Nov 07, 2023



Within (semi-)automated visual industrial inspection, learning-based approaches for assessing visual defects, including deep neural networks, enable the processing of otherwise small defect patterns in pixel size on high-resolution imagery. The emergence of these often rarely occurring defect patterns explains the general need for labeled data corpora. To alleviate this issue and advance the current state of the art in unsupervised visual inspection, this work proposes a DifferNet-based solution enhanced with attention modules: AttentDifferNet. It improves image-level detection and classification capabilities on three visual anomaly detection datasets for industrial inspection: InsPLAD-fault, MVTec AD, and Semiconductor Wafer. In comparison to the state of the art, AttentDifferNet achieves improved results, which are, in turn, highlighted throughout our quali-quantitative study. Our quantitative evaluation shows an average improvement - compared to DifferNet - of 1.77 +/- 0.25 percentage points in overall AUROC considering all three datasets, reaching SOTA results in InsPLAD-fault, an industrial inspection in-the-wild dataset. As our variants to AttentDifferNet show great prospects in the context of currently investigated approaches, a baseline is formulated, emphasizing the importance of attention for industrial anomaly detection both in the wild and in controlled environments.
Generalizable Multi-Camera 3D Pedestrian Detection
Apr 12, 2021


We present a multi-camera 3D pedestrian detection method that does not need to train using data from the target scene. We estimate pedestrian location on the ground plane using a novel heuristic based on human body poses and person's bounding boxes from an off-the-shelf monocular detector. We then project these locations onto the world ground plane and fuse them with a new formulation of a clique cover problem. We also propose an optional step for exploiting pedestrian appearance during fusion by using a domain-generalizable person re-identification model. We evaluated the proposed approach on the challenging WILDTRACK dataset. It obtained a MODA of 0.569 and an F-score of 0.78, superior to state-of-the-art generalizable detection techniques.
Squeezed Deep 6DoF Object Detection Using Knowledge Distillation
Mar 31, 2020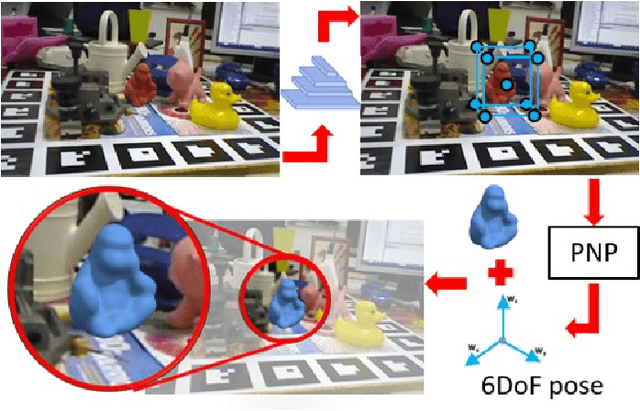
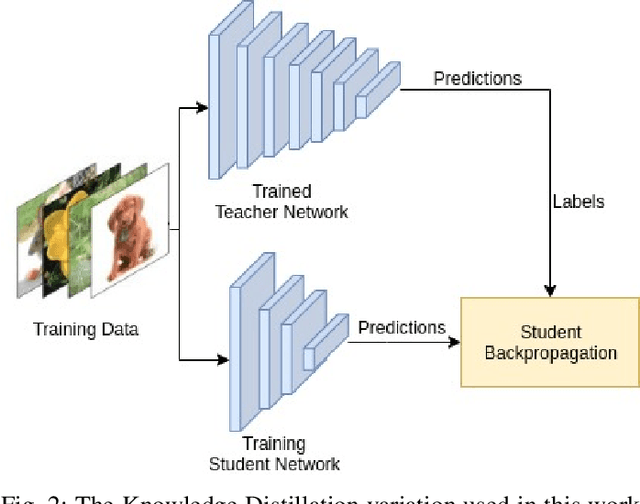


The detection of objects considering a 6DoF pose is common requisite to build virtual and augmented reality applications. It is usually a complex task witch requires real-time processing and high precision results for an adequate user experience. Recently, different deep learning techniques have been proposed to detect objects in 6DoF in RGB images but they rely on high complexity networks, requiring a computational power that prevents them to work on mobile devices. In this paper, we propose an approach to reduce the complexity of 6DoF detection networks while maintaining accuracy. We used Knowledge Distillation to teach portables Convolutional Neural Networks (CNN) to learn from a real-time 6DoF detection CNN. The proposed method allows real-time applications using only RGB images while decreasing the hardware requirements. We used the LINEMOD dataset to evaluate the proposed method and the experimental results show that the proposed method reduces the memory requirement almost 99\% in comparison to the original architecture reducing half the accuracy in one of the metrics. Code is available at https://github.com/heitorcfelix/singleshot6Dpose