 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLOWING: Implicit Neural Flows for Structure-Preserving Morphing
Oct 10, 2025



Morphing is a long-standing problem in vision and computer graphics, requiring a time-dependent warping for feature alignment and a blending for smooth interpolation. Recently, multilayer perceptrons (MLPs) have been explored as implicit neural representations (INRs) for modeling such deformations, due to their meshlessness and differentiability; however, extracting coherent and accurate morphings from standard MLPs typically relies on costly regularizations, which often lead to unstable training and prevent effective feature alignment. To overcome these limitations, we propose FLOWING (FLOW morphING), a framework that recasts warping as the construction of a differential vector flow, naturally ensuring continuity, invertibility, and temporal coherence by encoding structural flow properties directly into the network architectures. This flow-centric approach yields principled and stable transformations, enabling accurate and structure-preserving morphing of both 2D images and 3D shapes. Extensive experiments across a range of applications - including face and image morphing, as well as Gaussian Splatting morphing - show that FLOWING achieves state-of-the-art morphing quality with faster convergence. Code and pretrained models are available at http://schardong.github.io/flowing.
Toward unlabeled multi-view 3D pedestrian detection by generalizable AI: techniques and performance analysis
Aug 08, 2023



We unveil how generalizable AI can be used to improve multi-view 3D pedestrian detection in unlabeled target scenes. One way to increase generalization to new scenes is to automatically label target data, which can then be used for training a detector model. In this context, we investigate two approaches for automatically labeling target data: pseudo-labeling using a supervised detector and automatic labeling using an untrained detector (that can be applied out of the box without any training). We adopt a training framework for optimizing detector models using automatic labeling procedures. This framework encompasses different training sets/modes and multi-round automatic labeling strategies. We conduct our analyses on the publicly-available WILDTRACK and MultiviewX datasets. We show that, by using the automatic labeling approach based on an untrained detector, we can obtain superior results than directly using the untrained detector or a detector trained with an existing labeled source dataset. It achieved a MODA about 4% and 1% better than the best existing unlabeled method when using WILDTRACK and MultiviewX as target datasets, respectively.
Generalizable Multi-Camera 3D Pedestrian Detection
Apr 12, 2021
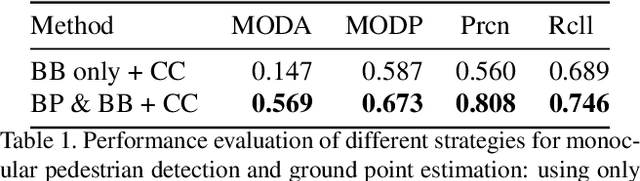


We present a multi-camera 3D pedestrian detection method that does not need to train using data from the target scene. We estimate pedestrian location on the ground plane using a novel heuristic based on human body poses and person's bounding boxes from an off-the-shelf monocular detector. We then project these locations onto the world ground plane and fuse them with a new formulation of a clique cover problem. We also propose an optional step for exploiting pedestrian appearance during fusion by using a domain-generalizable person re-identification model. We evaluated the proposed approach on the challenging WILDTRACK dataset. It obtained a MODA of 0.569 and an F-score of 0.78, superior to state-of-the-art generalizable detection techniques.