 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind Your Vision: Multimodal Estimation of Refractive Disorders Using Electrooculography and Eye Tracking
May 24, 2025Refractive errors are among the most common visual impairments globally, yet their diagnosis often relies on active user participation and clinical oversight. This study explores a passive method for estimating refractive power using two eye movement recording techniques: electrooculography (EOG) and video-based eye tracking. Using a publicly available dataset recorded under varying diopter conditions, we trained Long Short-Term Memory (LSTM) models to classify refractive power from unimodal (EOG or eye tracking) and multimodal configuration. We assess performance in both subject-dependent and subject-independent settings to evaluate model personalization and generalizability across individuals. Results show that the multimodal model consistently outperforms unimodal models, achieving the highest average accuracy in both settings: 96.207\% in the subject-dependent scenario and 8.882\% in the subject-independent scenario. However, generalization remains limited, with classification accuracy only marginally above chance in the subject-independent evaluations. Statistical comparisons in the subject-dependent setting confirmed that the multimodal model significantly outperformed the EOG and eye-tracking models. However, no statistically significant differences were found in the subject-independent setting. Our findings demonstrate both the potential and current limitations of eye movement data-based refractive error estimation, contributing to the development of continuous, non-invasive screening methods using EOG signals and eye-tracking data.
UMotion: Uncertainty-driven Human Motion Estimation from Inertial and Ultra-wideband Units
May 14, 2025Sparse wearable inertial measurement units (IMUs) have gained popularity for estimating 3D human motion. However, challenges such as pose ambiguity, data drift, and limited adaptability to diverse bodies persist. To address these issues, we propose UMotion, an uncertainty-driven, online fusing-all state estimation framework for 3D human shape and pose estimation, supported by six integrated, body-worn ultra-wideband (UWB) distance sensors with IMUs. UWB sensors measure inter-node distances to infer spatial relationships, aiding in resolving pose ambiguities and body shape variations when combined with anthropometric data. Unfortunately, IMUs are prone to drift, and UWB sensors are affected by body occlusions. Consequently, we develop a tightly coupled Unscented Kalman Filter (UKF) framework that fuses uncertainties from sensor data and estimated human motion based on individual body shape. The UKF iteratively refines IMU and UWB measurements by aligning them with uncertain human motion constraints in real-time, producing optimal estimates for each. Experiments on both synthetic and real-world datasets demonstrate the effectiveness of UMotion in stabilizing sensor data and the improvement over state of the art in pose accuracy.
Ensemble Learning to Assess Dynamics of Affective Experience Ratings and Physiological Change
Dec 26, 2023The congruence between affective experiences and physiological changes has been a debated topic for centuries. Recent technological advances in measurement and data analysis provide hope to solve this epic challenge. Open science and open data practices, together with data analysis challenges open to the academic community, are also promising tools for solving this problem. In this entry to the Emotion Physiology and Experience Collaboration (EPiC) challenge, we propose a data analysis solution that combines theoretical assumptions with data-driven methodologies. We used feature engineering and ensemble selection. Each predictor was trained on subsets of the training data that would maximize the information available for training. Late fusion was used with an averaging step. We chose to average considering a ``wisdom of crowds'' strategy. This strategy yielded an overall RMSE of 1.19 in the test set. Future work should carefully explore if our assumptions are correct and the potential of weighted fusion.
Toward unlabeled multi-view 3D pedestrian detection by generalizable AI: techniques and performance analysis
Aug 08, 2023



We unveil how generalizable AI can be used to improve multi-view 3D pedestrian detection in unlabeled target scenes. One way to increase generalization to new scenes is to automatically label target data, which can then be used for training a detector model. In this context, we investigate two approaches for automatically labeling target data: pseudo-labeling using a supervised detector and automatic labeling using an untrained detector (that can be applied out of the box without any training). We adopt a training framework for optimizing detector models using automatic labeling procedures. This framework encompasses different training sets/modes and multi-round automatic labeling strategies. We conduct our analyses on the publicly-available WILDTRACK and MultiviewX datasets. We show that, by using the automatic labeling approach based on an untrained detector, we can obtain superior results than directly using the untrained detector or a detector trained with an existing labeled source dataset. It achieved a MODA about 4% and 1% better than the best existing unlabeled method when using WILDTRACK and MultiviewX as target datasets, respectively.
MOTSLAM: MOT-assisted monocular dynamic SLAM using single-view depth estimation
Oct 05, 2022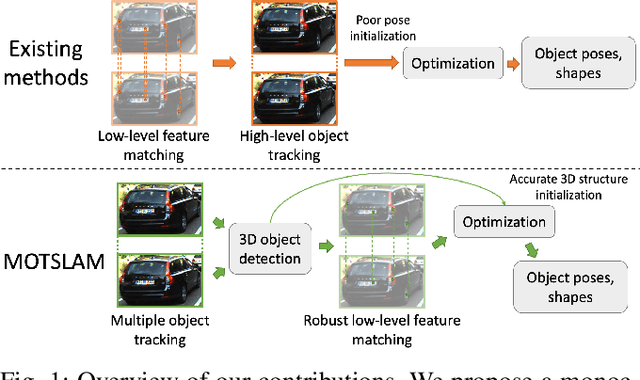
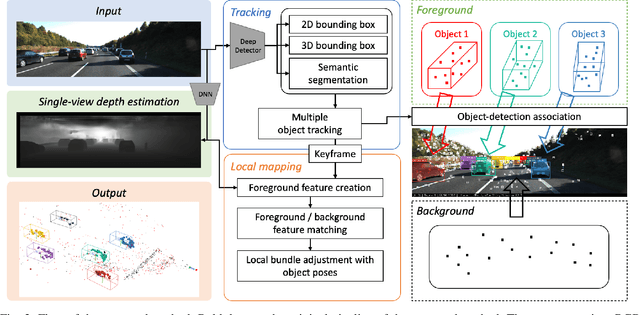
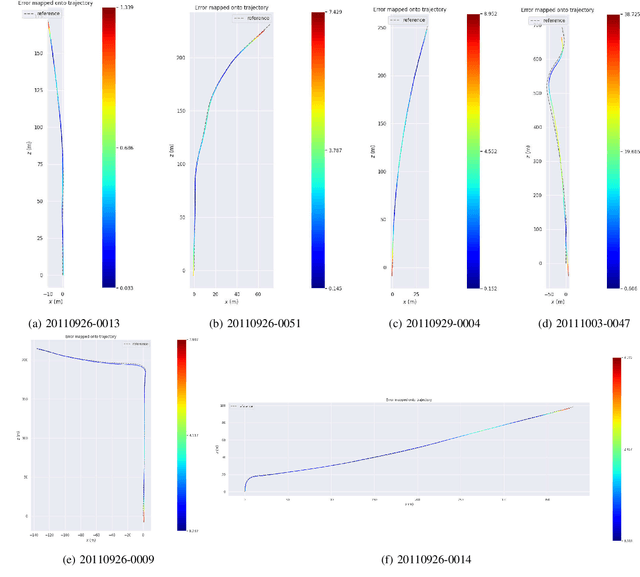

Visual SLAM systems targeting static scenes have been developed with satisfactory accuracy and robustness. Dynamic 3D object tracking has then become a significant capability in visual SLAM with the requirement of understanding dynamic surroundings in various scenarios including autonomous driving, augmented and virtual reality. However, performing dynamic SLAM solely with monocular images remains a challenging problem due to the difficulty of associating dynamic features and estimating their positions. In this paper, we present MOTSLAM, a dynamic visual SLAM system with the monocular configuration that tracks both poses and bounding boxes of dynamic objects. MOTSLAM first performs multiple object tracking (MOT) with associated both 2D and 3D bounding box detection to create initial 3D objects. Then, neural-network-based monocular depth estimation is applied to fetch the depth of dynamic features. Finally, camera poses, object poses, and both static, as well as dynamic map points, are jointly optimized using a novel bundle adjustment. Our experiments on the KITTI dataset demonstrate that our system has reached best performance on both camera ego-motion and object tracking on monocular dynamic SLAM.
TetraTSDF: 3D human reconstruction from a single image with a tetrahedral outer shell
Apr 22, 2020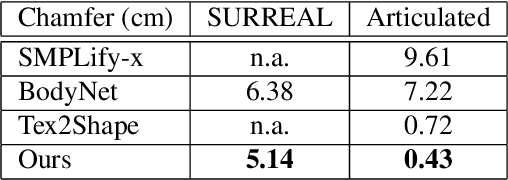
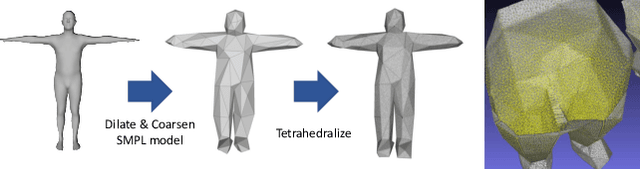

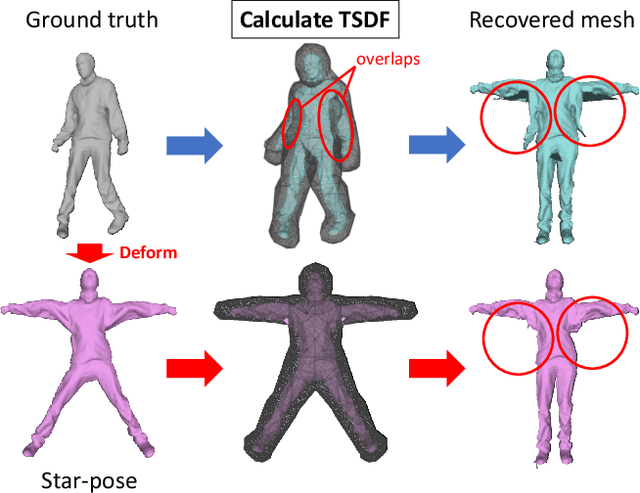
Recovering the 3D shape of a person from its 2D appearance is ill-posed due to ambiguities. Nevertheless, with the help of convolutional neural networks (CNN) and prior knowledge on the 3D human body, it is possible to overcome such ambiguities to recover detailed 3D shapes of human bodies from single images. Current solutions, however, fail to reconstruct all the details of a person wearing loose clothes. This is because of either (a) huge memory requirement that cannot be maintained even on modern GPUs or (b) the compact 3D representation that cannot encode all the details. In this paper, we propose the tetrahedral outer shell volumetric truncated signed distance function (TetraTSDF) model for the human body, and its corresponding part connection network (PCN) for 3D human body shape regression. Our proposed model is compact, dense, accurate, and yet well suited for CNN-based regression task. Our proposed PCN allows us to learn the distribution of the TSDF in the tetrahedral volume from a single image in an end-to-end manner. Results show that our proposed method allows to reconstruct detailed shapes of humans wearing loose clothes from single RGB images.