 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Synchronized Audio-Visual Multi-View Capture System
Mar 24, 2026Multi-view capture systems have been an important tool in research for recording human motion under controlling conditions. Most existing systems are specified around video streams and provide little or no support for audio acquisition and rigorous audio-video alignment, despite both being essential for studying conversational interaction where timing at the level of turn-taking, overlap, and prosody matters. In this technical report, we describe an audio-visual multi-view capture system that addresses this gap by treating synchronized audio and synchronized video as first-class signals. The system combines a multi-camera pipeline with multi-channel microphone recording under a unified timing architecture and provides a practical workflow for calibration, acquisition, and quality control that supports repeatable recordings at scale. We quantify synchronization performance in deployment and show that the resulting recordings are temporally consistent enough to support fine-grained analysis and data-driven modeling of conversation behavior.
Controlled Face Manipulation and Synthesis for Data Augmentation
Feb 22, 2026Deep learning vision models excel with abundant supervision, but many applications face label scarcity and class imbalance. Controllable image editing can augment scarce labeled data, yet edits often introduce artifacts and entangle non-target attributes. We study this in facial expression analysis, targeting Action Unit (AU) manipulation where annotation is costly and AU co-activation drives entanglement. We present a facial manipulation method that operates in the semantic latent space of a pre-trained face generator (Diffusion Autoencoder). Using lightweight linear models, we reduce entanglement of semantic features via (i) dependency-aware conditioning that accounts for AU co-activation, and (ii) orthogonal projection that removes nuisance attribute directions (e.g., glasses), together with an expression neutralization step to enable absolute AU edit. We use these edits to balance AU occurrence by editing labeled faces and to diversify identities/demographics via controlled synthesis. Augmenting AU detector training with the generated data improves accuracy and yields more disentangled predictions with fewer co-activation shortcuts, outperforming alternative data-efficient training strategies and suggesting improvements similar to what would require substantially more labeled data in our learning-curve analysis. Compared to prior methods, our edits are stronger, produce fewer artifacts, and preserve identity better.
Indeterminacy in Affective Computing: Considering Meaning and Context in Data Collection Practices
Feb 13, 2025
Automatic Affect Prediction (AAP) uses computational analysis of input data such as text, speech, images, and physiological signals to predict various affective phenomena (e.g., emotions or moods). These models are typically constructed using supervised machine-learning algorithms, which rely heavily on labeled training datasets. In this position paper, we posit that all AAP training data are derived from human Affective Interpretation Processes, resulting in a form of Affective Meaning. Research on human affect indicates a form of complexity that is fundamental to such meaning: it can possess what we refer to here broadly as Qualities of Indeterminacy (QIs) - encompassing Subjectivity (meaning depends on who is interpreting), Uncertainty (lack of confidence regarding meanings' correctness), Ambiguity (meaning contains mutually exclusive concepts) and Vagueness (meaning is situated at different levels in a nested hierarchy). Failing to appropriately consider QIs leads to results incapable of meaningful and reliable predictions. Based on this premise, we argue that a crucial step in adequately addressing indeterminacy in AAP is the development of data collection practices for modeling corpora that involve the systematic consideration of 1) a relevant set of QIs and 2) context for the associated interpretation processes. To this end, we are 1) outlining a conceptual model of AIPs and the QIs associated with the meaning these produce and a conceptual structure of relevant context, supporting understanding of its role. Finally, we use our framework for 2) discussing examples of context-sensitivity-related challenges for addressing QIs in data collection setups. We believe our efforts can stimulate a structured discussion of both the role of aspects of indeterminacy and context in research on AAP, informing the development of better practices for data collection and analysis.
Social Processes: Probabilistic Meta-learning for Adaptive Multiparty Interaction Forecasting
Jan 03, 2025Adaptively forecasting human behavior in social settings is an important step toward achieving Artificial General Intelligence. Most existing research in social forecasting has focused either on unfocused interactions, such as pedestrian trajectory prediction, or on monadic and dyadic behavior forecasting. In contrast, social psychology emphasizes the importance of group interactions for understanding complex social dynamics. This creates a gap that we address in this paper: forecasting social interactions at the group (conversation) level. Additionally, it is important for a forecasting model to be able to adapt to groups unseen at train time, as even the same individual behaves differently across different groups. This highlights the need for a forecasting model to explicitly account for each group's unique dynamics. To achieve this, we adopt a meta-learning approach to human behavior forecasting, treating every group as a separate meta-learning task. As a result, our method conditions its predictions on the specific behaviors within the group, leading to generalization to unseen groups. Specifically, we introduce Social Process (SP) models, which predict a distribution over future multimodal cues jointly for all group members based on their preceding low-level multimodal cues, while incorporating other past sequences of the same group's interactions. In this work we also analyze the generalization capabilities of SP models in both their outputs and latent spaces through the use of realistic synthetic datasets.
MindForge: Empowering Embodied Agents with Theory of Mind for Lifelong Collaborative Learning
Nov 20, 2024



Contemporary embodied agents, such as Voyager in Minecraft, have demonstrated promising capabilities in open-ended individual learning. However, when powered with open large language models (LLMs), these agents often struggle with rudimentary tasks, even when fine-tuned on domain-specific knowledge. Inspired by human cultural learning, we present \collabvoyager, a novel framework that enhances Voyager with lifelong collaborative learning through explicit perspective-taking. \collabvoyager introduces three key innovations: (1) theory of mind representations linking percepts, beliefs, desires, and actions; (2) natural language communication between agents; and (3) semantic memory of task and environment knowledge and episodic memory of collaboration episodes. These advancements enable agents to reason about their and others' mental states, empirically addressing two prevalent failure modes: false beliefs and faulty task executions. In mixed-expertise Minecraft experiments, \collabvoyager agents outperform Voyager counterparts, significantly improving task completion rate by $66.6\% (+39.4\%)$ for collecting one block of dirt and $70.8\% (+20.8\%)$ for collecting one wood block. They exhibit emergent behaviors like knowledge transfer from expert to novice agents and collaborative code correction. \collabvoyager agents also demonstrate the ability to adapt to out-of-distribution tasks by using their previous experiences and beliefs obtained through collaboration. In this open-ended social learning paradigm, \collabvoyager paves the way for the democratic development of embodied AI, where agents learn in deployment from both peer and environmental feedback.
How Private is Low-Frequency Speech Audio in the Wild? An Analysis of Verbal Intelligibility by Humans and Machines
Jul 18, 2024



Low-frequency audio has been proposed as a promising privacy-preserving modality to study social dynamics in real-world settings. To this end, researchers have developed wearable devices that can record audio at frequencies as low as 1250 Hz to mitigate the automatic extraction of the verbal content of speech that may contain private details. This paper investigates the validity of this hypothesis, examining the degree to which low-frequency speech ensures verbal privacy. It includes simulating a potential privacy attack in various noise environments. Further, it explores the trade-off between the performance of voice activity detection, which is fundamental for understanding social behavior, and privacy-preservation. The evaluation incorporates subjective human intelligibility and automatic speech recognition performance, comprehensively analyzing the delicate balance between effective social behavior analysis and preserving verbal privacy.
A Comparative Study of Garment Draping Techniques
May 17, 2024



We present a comparison review that evaluates popular techniques for garment draping for 3D fashion design, virtual try-ons, and animations. A comparative study is performed between various methods for garment draping of clothing over the human body. These include numerous models, such as physics and machine learning based techniques, collision handling, and more. Performance evaluations and trade-offs are discussed to ensure informed decision-making when choosing the most appropriate approach. These methods aim to accurately represent deformations and fine wrinkles of digital garments, considering the factors of data requirements, and efficiency, to produce realistic results. The research can be insightful to researchers, designers, and developers in visualizing dynamic multi-layered 3D clothing.
REWIND Dataset: Privacy-preserving Speaking Status Segmentation from Multimodal Body Movement Signals in the Wild
Mar 02, 2024



Recognizing speaking in humans is a central task towards understanding social interactions. Ideally, speaking would be detected from individual voice recordings, as done previously for meeting scenarios. However, individual voice recordings are hard to obtain in the wild, especially in crowded mingling scenarios due to cost, logistics, and privacy concerns. As an alternative, machine learning models trained on video and wearable sensor data make it possible to recognize speech by detecting its related gestures in an unobtrusive, privacy-preserving way. These models themselves should ideally be trained using labels obtained from the speech signal. However, existing mingling datasets do not contain high quality audio recordings. Instead, speaking status annotations have often been inferred by human annotators from video, without validation of this approach against audio-based ground truth. In this paper we revisit no-audio speaking status estimation by presenting the first publicly available multimodal dataset with high-quality individual speech recordings of 33 subjects in a professional networking event. We present three baselines for no-audio speaking status segmentation: a) from video, b) from body acceleration (chest-worn accelerometer), c) from body pose tracks. In all cases we predict a 20Hz binary speaking status signal extracted from the audio, a time resolution not available in previous datasets. In addition to providing the signals and ground truth necessary to evaluate a wide range of speaking status detection methods, the availability of audio in REWIND makes it suitable for cross-modality studies not feasible with previous mingling datasets. Finally, our flexible data consent setup creates new challenges for multimodal systems under missing modalities.
Ensemble Learning to Assess Dynamics of Affective Experience Ratings and Physiological Change
Dec 26, 2023The congruence between affective experiences and physiological changes has been a debated topic for centuries. Recent technological advances in measurement and data analysis provide hope to solve this epic challenge. Open science and open data practices, together with data analysis challenges open to the academic community, are also promising tools for solving this problem. In this entry to the Emotion Physiology and Experience Collaboration (EPiC) challenge, we propose a data analysis solution that combines theoretical assumptions with data-driven methodologies. We used feature engineering and ensemble selection. Each predictor was trained on subsets of the training data that would maximize the information available for training. Late fusion was used with an averaging step. We chose to average considering a ``wisdom of crowds'' strategy. This strategy yielded an overall RMSE of 1.19 in the test set. Future work should carefully explore if our assumptions are correct and the potential of weighted fusion.
Mesh-Tension Driven Expression-Based Wrinkles for Synthetic Faces
Oct 05, 2022
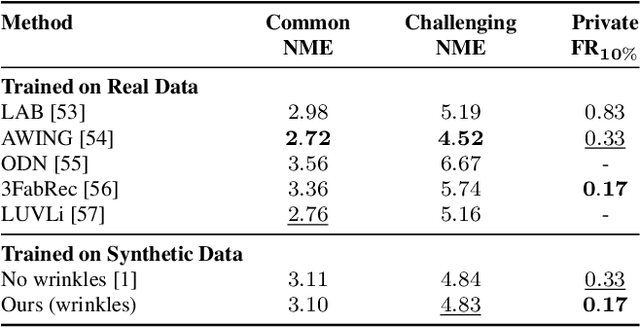

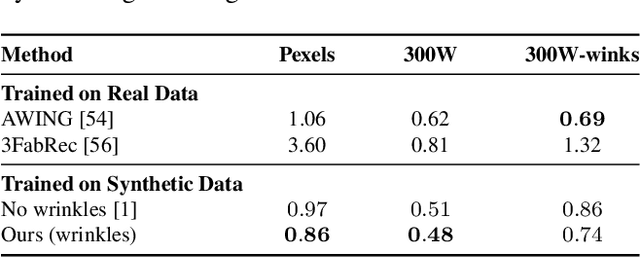
Recent advances in synthesizing realistic faces have shown that synthetic training data can replace real data for various face-related computer vision tasks. A question arises: how important is realism? Is the pursuit of photorealism excessive? In this work, we show otherwise. We boost the realism of our synthetic faces by introducing dynamic skin wrinkles in response to facial expressions and observe significant performance improvements in downstream computer vision tasks. Previous approaches for producing such wrinkles either required prohibitive artist effort to scale across identities and expressions or were not capable of reconstructing high-frequency skin details with sufficient fidelity. Our key contribution is an approach that produces realistic wrinkles across a large and diverse population of digital humans. Concretely, we formalize the concept of mesh-tension and use it to aggregate possible wrinkles from high-quality expression scans into albedo and displacement texture maps. At synthesis, we use these maps to produce wrinkles even for expressions not represented in the source scans. Additionally, to provide a more nuanced indicator of model performance under deformations resulting from compressed expressions, we introduce the 300W-winks evaluation subset and the Pexels dataset of closed eyes and winks.