 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring DNN Robustness Against Adversarial Attacks Using Approximate Multipliers
Apr 17, 2024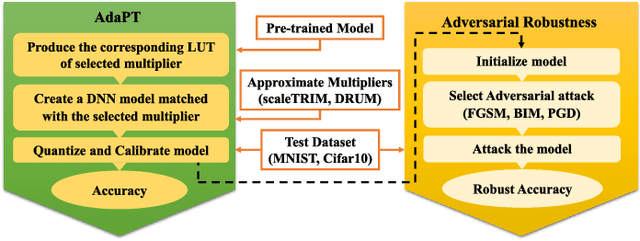
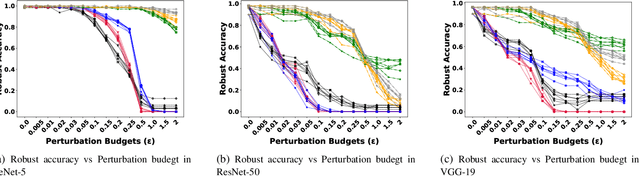
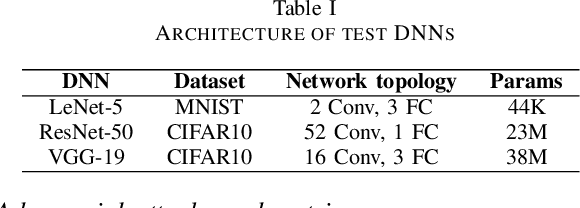

Deep Neural Networks (DNNs) have advanced in many real-world applications, such as healthcare and autonomous driving. However, their high computational complexity and vulnerability to adversarial attacks are ongoing challenges. In this letter, approximate multipliers are used to explore DNN robustness improvement against adversarial attacks. By uniformly replacing accurate multipliers for state-of-the-art approximate ones in DNN layer models, we explore the DNNs robustness against various adversarial attacks in a feasible time. Results show up to 7% accuracy drop due to approximations when no attack is present while improving robust accuracy up to 10% when attacks applied.
REWIND Dataset: Privacy-preserving Speaking Status Segmentation from Multimodal Body Movement Signals in the Wild
Mar 02, 2024



Recognizing speaking in humans is a central task towards understanding social interactions. Ideally, speaking would be detected from individual voice recordings, as done previously for meeting scenarios. However, individual voice recordings are hard to obtain in the wild, especially in crowded mingling scenarios due to cost, logistics, and privacy concerns. As an alternative, machine learning models trained on video and wearable sensor data make it possible to recognize speech by detecting its related gestures in an unobtrusive, privacy-preserving way. These models themselves should ideally be trained using labels obtained from the speech signal. However, existing mingling datasets do not contain high quality audio recordings. Instead, speaking status annotations have often been inferred by human annotators from video, without validation of this approach against audio-based ground truth. In this paper we revisit no-audio speaking status estimation by presenting the first publicly available multimodal dataset with high-quality individual speech recordings of 33 subjects in a professional networking event. We present three baselines for no-audio speaking status segmentation: a) from video, b) from body acceleration (chest-worn accelerometer), c) from body pose tracks. In all cases we predict a 20Hz binary speaking status signal extracted from the audio, a time resolution not available in previous datasets. In addition to providing the signals and ground truth necessary to evaluate a wide range of speaking status detection methods, the availability of audio in REWIND makes it suitable for cross-modality studies not feasible with previous mingling datasets. Finally, our flexible data consent setup creates new challenges for multimodal systems under missing modalities.
Impact of annotation modality on label quality and model performance in the automatic assessment of laughter in-the-wild
Nov 02, 2022
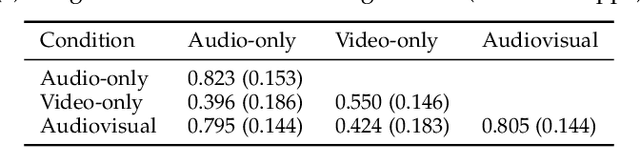
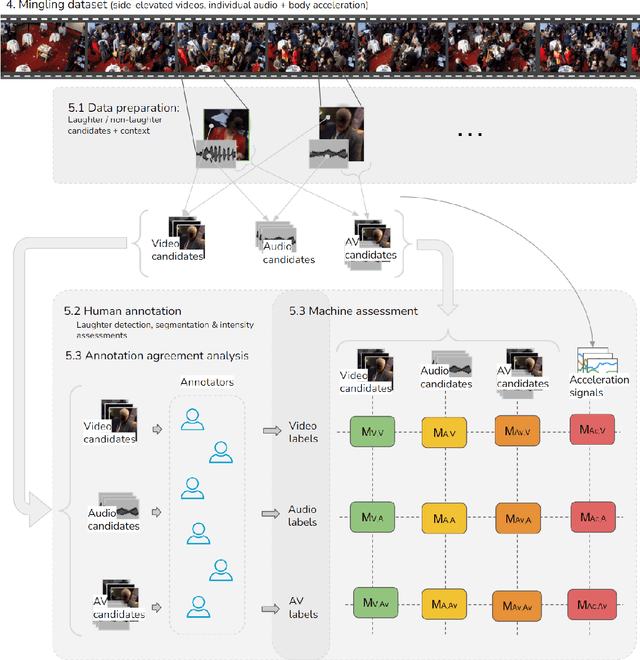
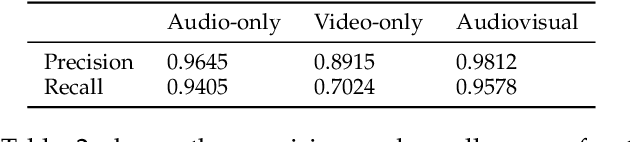
Laughter is considered one of the most overt signals of joy. Laughter is well-recognized as a multimodal phenomenon but is most commonly detected by sensing the sound of laughter. It is unclear how perception and annotation of laughter differ when annotated from other modalities like video, via the body movements of laughter. In this paper we take a first step in this direction by asking if and how well laughter can be annotated when only audio, only video (containing full body movement information) or audiovisual modalities are available to annotators. We ask whether annotations of laughter are congruent across modalities, and compare the effect that labeling modality has on machine learning model performance. We compare annotations and models for laughter detection, intensity estimation, and segmentation, three tasks common in previous studies of laughter. Our analysis of more than 4000 annotations acquired from 48 annotators revealed evidence for incongruity in the perception of laughter, and its intensity between modalities. Further analysis of annotations against consolidated audiovisual reference annotations revealed that recall was lower on average for video when compared to the audio condition, but tended to increase with the intensity of the laughter samples. Our machine learning experiments compared the performance of state-of-the-art unimodal (audio-based, video-based and acceleration-based) and multi-modal models for different combinations of input modalities, training label modality, and testing label modality. Models with video and acceleration inputs had similar performance regardless of training label modality, suggesting that it may be entirely appropriate to train models for laughter detection from body movements using video-acquired labels, despite their lower inter-rater agreement.
No-audio speaking status detection in crowded settings via visual pose-based filtering and wearable acceleration
Nov 01, 2022Recognizing who is speaking in a crowded scene is a key challenge towards the understanding of the social interactions going on within. Detecting speaking status from body movement alone opens the door for the analysis of social scenes in which personal audio is not obtainable. Video and wearable sensors make it possible recognize speaking in an unobtrusive, privacy-preserving way. When considering the video modality, in action recognition problems, a bounding box is traditionally used to localize and segment out the target subject, to then recognize the action taking place within it. However, cross-contamination, occlusion, and the articulated nature of the human body, make this approach challenging in a crowded scene. Here, we leverage articulated body poses for subject localization and in the subsequent speech detection stage. We show that the selection of local features around pose keypoints has a positive effect on generalization performance while also significantly reducing the number of local features considered, making for a more efficient method. Using two in-the-wild datasets with different viewpoints of subjects, we investigate the role of cross-contamination in this effect. We additionally make use of acceleration measured through wearable sensors for the same task, and present a multimodal approach combining both methods.