 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal learning for stable backpropagation-free neural network training towards physical learning
Mar 25, 2026While backpropagation and automatic differentiation have driven deep learning's success, the physical limits of chip manufacturing and rising environmental costs of deep learning motivate alternative learning paradigms such as physical neural networks. However, most existing physical neural networks still rely on digital computing for training, largely because backpropagation and automatic differentiation are difficult to realize in physical systems. We introduce FFzero, a forward-only learning framework enabling stable neural network training without backpropagation or automatic differentiation. FFzero combines layer-wise local learning, prototype-based representations, and directional-derivative-based optimization through forward evaluations only. We show that local learning is effective under forward-only optimization, where backpropagation fails. FFzero generalizes to multilayer perceptron and convolutional neural networks across classification and regression. Using a simulated photonic neural network as an example, we demonstrate that FFzero provides a viable path toward backpropagation-free in-situ physical learning.
REWIND Dataset: Privacy-preserving Speaking Status Segmentation from Multimodal Body Movement Signals in the Wild
Mar 02, 2024



Recognizing speaking in humans is a central task towards understanding social interactions. Ideally, speaking would be detected from individual voice recordings, as done previously for meeting scenarios. However, individual voice recordings are hard to obtain in the wild, especially in crowded mingling scenarios due to cost, logistics, and privacy concerns. As an alternative, machine learning models trained on video and wearable sensor data make it possible to recognize speech by detecting its related gestures in an unobtrusive, privacy-preserving way. These models themselves should ideally be trained using labels obtained from the speech signal. However, existing mingling datasets do not contain high quality audio recordings. Instead, speaking status annotations have often been inferred by human annotators from video, without validation of this approach against audio-based ground truth. In this paper we revisit no-audio speaking status estimation by presenting the first publicly available multimodal dataset with high-quality individual speech recordings of 33 subjects in a professional networking event. We present three baselines for no-audio speaking status segmentation: a) from video, b) from body acceleration (chest-worn accelerometer), c) from body pose tracks. In all cases we predict a 20Hz binary speaking status signal extracted from the audio, a time resolution not available in previous datasets. In addition to providing the signals and ground truth necessary to evaluate a wide range of speaking status detection methods, the availability of audio in REWIND makes it suitable for cross-modality studies not feasible with previous mingling datasets. Finally, our flexible data consent setup creates new challenges for multimodal systems under missing modalities.
Conversation Group Detection With Spatio-Temporal Context
Jun 02, 2022
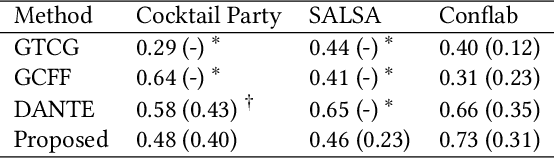

In this work, we propose an approach for detecting conversation groups in social scenarios like cocktail parties and networking events, from overhead camera recordings. We posit the detection of conversation groups as a learning problem that could benefit from leveraging the spatial context of the surroundings, and the inherent temporal context in interpersonal dynamics which is reflected in the temporal dynamics in human behavior signals, an aspect that has not been addressed in recent prior works. This motivates our approach which consists of a dynamic LSTM-based deep learning model that predicts continuous pairwise affinity values indicating how likely two people are in the same conversation group. These affinity values are also continuous in time, since relationships and group membership do not occur instantaneously, even though the ground truths of group membership are binary. Using the predicted affinity values, we apply a graph clustering method based on Dominant Set extraction to identify the conversation groups. We benchmark the proposed method against established methods on multiple social interaction datasets. Our results showed that the proposed method improves group detection performance in data that has more temporal granularity in conversation group labels. Additionally, we provide an analysis in the predicted affinity values in relation to the conversation group detection. Finally, we demonstrate the usability of the predicted affinity values in a forecasting framework to predict group membership for a given forecast horizon.
ConfLab: A Rich Multimodal Multisensor Dataset of Free-Standing Social Interactions In-the-Wild
May 10, 2022


We describe an instantiation of a new concept for multimodal multisensor data collection of real life in-the-wild free standing social interactions in the form of a Conference Living Lab (ConfLab). ConfLab contains high fidelity data of 49 people during a real-life professional networking event capturing a diverse mix of status, acquaintanceship, and networking motivations at an international conference. Recording such a dataset is challenging due to the delicate trade-off between participant privacy and fidelity of the data, and the technical and logistic challenges involved. We improve upon prior datasets in the fidelity of most of our modalities: 8-camera overhead setup, personal wearable sensors recording body motion (9-axis IMU), Bluetooth-based proximity, and low-frequency audio. Additionally, we use a state-of-the-art hardware synchronization solution and time-efficient continuous technique for annotating body keypoints and actions at high frequencies. We argue that our improvements are essential for a deeper study of interaction dynamics at finer time scales. Our research tasks showcase some of the open challenges related to in-the-wild privacy-preserving social data analysis: keypoints detection from overhead camera views, skeleton based no-audio speaker detection, and F-formation detection. With the ConfLab dataset, we aim to bridge the gap between traditional computer vision tasks and in-the-wild ecologically valid socially-motivated tasks.
Improving Temporal Interpolation of Head and Body Pose using Gaussian Process Regression in a Matrix Completion Setting
Aug 06, 2018
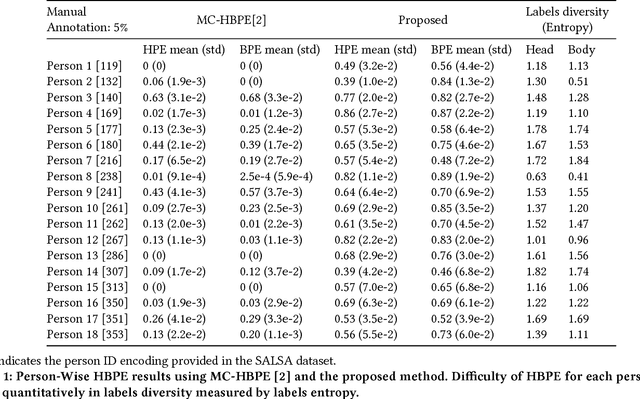

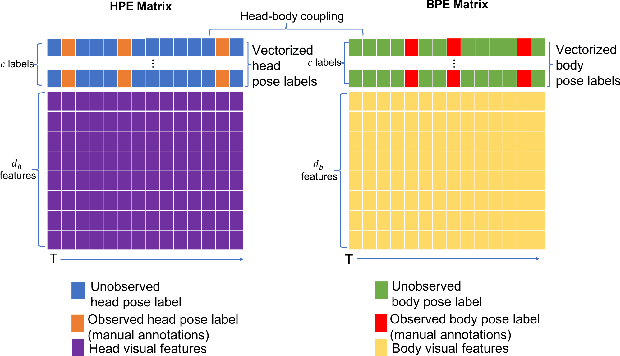
This paper presents a model for head and body pose estimation (HBPE) when labelled samples are highly sparse. The current state-of-the-art multimodal approach to HBPE utilizes the matrix completion method in a transductive setting to predict pose labels for unobserved samples. Based on this approach, the proposed method tackles HBPE when manually annotated ground truth labels are temporally sparse. We posit that the current state of the art approach oversimplifies the temporal sparsity assumption by using Laplacian smoothing. Our final solution uses: i) Gaussian process regression in place of Laplacian smoothing, ii) head and body coupling, and iii) nuclear norm minimization in the matrix completion setting. The model is applied to the challenging SALSA dataset for benchmark against the state-of-the-art method. Our presented formulation outperforms the state-of-the-art significantly in this particular setting, e.g. at 5% ground truth labels as training data, head pose accuracy and body pose accuracy is approximately 62% and 70%, respectively. As well as fitting a more flexible model to missing labels in time, we posit that our approach also loosens the head and body coupling constraint, allowing for a more expressive model of the head and body pose typically seen during conversational interaction in groups. This provides a new baseline to improve upon for future integration of multimodal sensor data for the purpose of HBPE.