 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of annotation modality on label quality and model performance in the automatic assessment of laughter in-the-wild
Nov 02, 2022
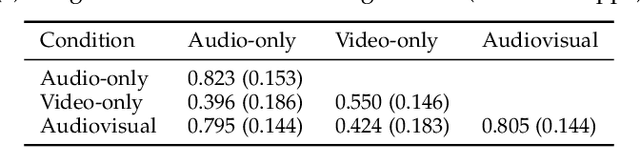
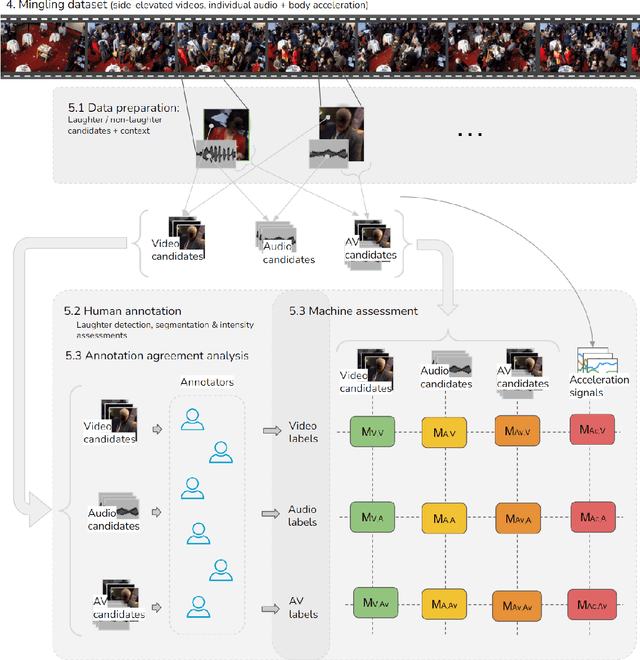
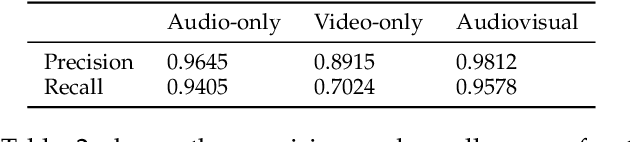
Laughter is considered one of the most overt signals of joy. Laughter is well-recognized as a multimodal phenomenon but is most commonly detected by sensing the sound of laughter. It is unclear how perception and annotation of laughter differ when annotated from other modalities like video, via the body movements of laughter. In this paper we take a first step in this direction by asking if and how well laughter can be annotated when only audio, only video (containing full body movement information) or audiovisual modalities are available to annotators. We ask whether annotations of laughter are congruent across modalities, and compare the effect that labeling modality has on machine learning model performance. We compare annotations and models for laughter detection, intensity estimation, and segmentation, three tasks common in previous studies of laughter. Our analysis of more than 4000 annotations acquired from 48 annotators revealed evidence for incongruity in the perception of laughter, and its intensity between modalities. Further analysis of annotations against consolidated audiovisual reference annotations revealed that recall was lower on average for video when compared to the audio condition, but tended to increase with the intensity of the laughter samples. Our machine learning experiments compared the performance of state-of-the-art unimodal (audio-based, video-based and acceleration-based) and multi-modal models for different combinations of input modalities, training label modality, and testing label modality. Models with video and acceleration inputs had similar performance regardless of training label modality, suggesting that it may be entirely appropriate to train models for laughter detection from body movements using video-acquired labels, despite their lower inter-rater agreement.
No-audio speaking status detection in crowded settings via visual pose-based filtering and wearable acceleration
Nov 01, 2022Recognizing who is speaking in a crowded scene is a key challenge towards the understanding of the social interactions going on within. Detecting speaking status from body movement alone opens the door for the analysis of social scenes in which personal audio is not obtainable. Video and wearable sensors make it possible recognize speaking in an unobtrusive, privacy-preserving way. When considering the video modality, in action recognition problems, a bounding box is traditionally used to localize and segment out the target subject, to then recognize the action taking place within it. However, cross-contamination, occlusion, and the articulated nature of the human body, make this approach challenging in a crowded scene. Here, we leverage articulated body poses for subject localization and in the subsequent speech detection stage. We show that the selection of local features around pose keypoints has a positive effect on generalization performance while also significantly reducing the number of local features considered, making for a more efficient method. Using two in-the-wild datasets with different viewpoints of subjects, we investigate the role of cross-contamination in this effect. We additionally make use of acceleration measured through wearable sensors for the same task, and present a multimodal approach combining both methods.
ConfLab: A Rich Multimodal Multisensor Dataset of Free-Standing Social Interactions In-the-Wild
May 10, 2022


We describe an instantiation of a new concept for multimodal multisensor data collection of real life in-the-wild free standing social interactions in the form of a Conference Living Lab (ConfLab). ConfLab contains high fidelity data of 49 people during a real-life professional networking event capturing a diverse mix of status, acquaintanceship, and networking motivations at an international conference. Recording such a dataset is challenging due to the delicate trade-off between participant privacy and fidelity of the data, and the technical and logistic challenges involved. We improve upon prior datasets in the fidelity of most of our modalities: 8-camera overhead setup, personal wearable sensors recording body motion (9-axis IMU), Bluetooth-based proximity, and low-frequency audio. Additionally, we use a state-of-the-art hardware synchronization solution and time-efficient continuous technique for annotating body keypoints and actions at high frequencies. We argue that our improvements are essential for a deeper study of interaction dynamics at finer time scales. Our research tasks showcase some of the open challenges related to in-the-wild privacy-preserving social data analysis: keypoints detection from overhead camera views, skeleton based no-audio speaker detection, and F-formation detection. With the ConfLab dataset, we aim to bridge the gap between traditional computer vision tasks and in-the-wild ecologically valid socially-motivated tasks.