 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of annotation modality on label quality and model performance in the automatic assessment of laughter in-the-wild
Paper and Code
Nov 02, 2022
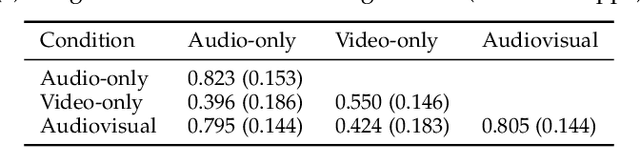
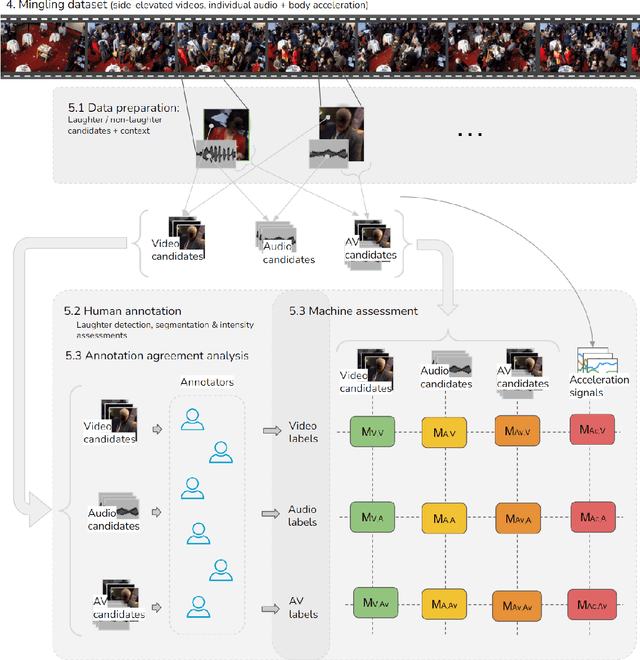
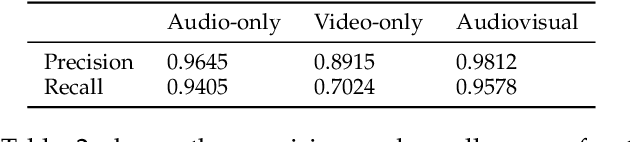
Laughter is considered one of the most overt signals of joy. Laughter is well-recognized as a multimodal phenomenon but is most commonly detected by sensing the sound of laughter. It is unclear how perception and annotation of laughter differ when annotated from other modalities like video, via the body movements of laughter. In this paper we take a first step in this direction by asking if and how well laughter can be annotated when only audio, only video (containing full body movement information) or audiovisual modalities are available to annotators. We ask whether annotations of laughter are congruent across modalities, and compare the effect that labeling modality has on machine learning model performance. We compare annotations and models for laughter detection, intensity estimation, and segmentation, three tasks common in previous studies of laughter. Our analysis of more than 4000 annotations acquired from 48 annotators revealed evidence for incongruity in the perception of laughter, and its intensity between modalities. Further analysis of annotations against consolidated audiovisual reference annotations revealed that recall was lower on average for video when compared to the audio condition, but tended to increase with the intensity of the laughter samples. Our machine learning experiments compared the performance of state-of-the-art unimodal (audio-based, video-based and acceleration-based) and multi-modal models for different combinations of input modalities, training label modality, and testing label modality. Models with video and acceleration inputs had similar performance regardless of training label modality, suggesting that it may be entirely appropriate to train models for laughter detection from body movements using video-acquired labels, despite their lower inter-rater agreement.