 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREWIND Dataset: Privacy-preserving Speaking Status Segmentation from Multimodal Body Movement Signals in the Wild
Mar 02, 2024



Recognizing speaking in humans is a central task towards understanding social interactions. Ideally, speaking would be detected from individual voice recordings, as done previously for meeting scenarios. However, individual voice recordings are hard to obtain in the wild, especially in crowded mingling scenarios due to cost, logistics, and privacy concerns. As an alternative, machine learning models trained on video and wearable sensor data make it possible to recognize speech by detecting its related gestures in an unobtrusive, privacy-preserving way. These models themselves should ideally be trained using labels obtained from the speech signal. However, existing mingling datasets do not contain high quality audio recordings. Instead, speaking status annotations have often been inferred by human annotators from video, without validation of this approach against audio-based ground truth. In this paper we revisit no-audio speaking status estimation by presenting the first publicly available multimodal dataset with high-quality individual speech recordings of 33 subjects in a professional networking event. We present three baselines for no-audio speaking status segmentation: a) from video, b) from body acceleration (chest-worn accelerometer), c) from body pose tracks. In all cases we predict a 20Hz binary speaking status signal extracted from the audio, a time resolution not available in previous datasets. In addition to providing the signals and ground truth necessary to evaluate a wide range of speaking status detection methods, the availability of audio in REWIND makes it suitable for cross-modality studies not feasible with previous mingling datasets. Finally, our flexible data consent setup creates new challenges for multimodal systems under missing modalities.
ConfLab: A Rich Multimodal Multisensor Dataset of Free-Standing Social Interactions In-the-Wild
May 10, 2022


We describe an instantiation of a new concept for multimodal multisensor data collection of real life in-the-wild free standing social interactions in the form of a Conference Living Lab (ConfLab). ConfLab contains high fidelity data of 49 people during a real-life professional networking event capturing a diverse mix of status, acquaintanceship, and networking motivations at an international conference. Recording such a dataset is challenging due to the delicate trade-off between participant privacy and fidelity of the data, and the technical and logistic challenges involved. We improve upon prior datasets in the fidelity of most of our modalities: 8-camera overhead setup, personal wearable sensors recording body motion (9-axis IMU), Bluetooth-based proximity, and low-frequency audio. Additionally, we use a state-of-the-art hardware synchronization solution and time-efficient continuous technique for annotating body keypoints and actions at high frequencies. We argue that our improvements are essential for a deeper study of interaction dynamics at finer time scales. Our research tasks showcase some of the open challenges related to in-the-wild privacy-preserving social data analysis: keypoints detection from overhead camera views, skeleton based no-audio speaker detection, and F-formation detection. With the ConfLab dataset, we aim to bridge the gap between traditional computer vision tasks and in-the-wild ecologically valid socially-motivated tasks.
Detecting F-formations & Roles in Crowded Social Scenes with Wearables: Combining Proxemics & Dynamics using LSTMs
Nov 17, 2019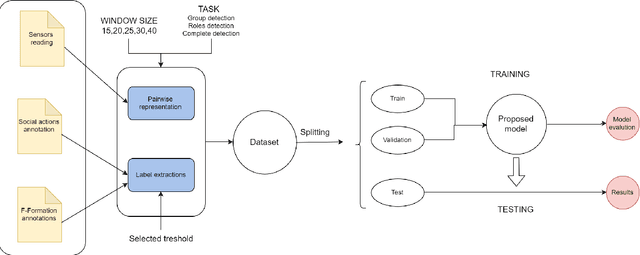
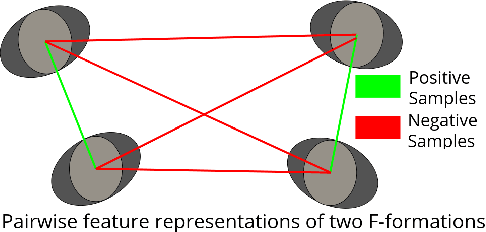


In this paper, we investigate the use of proxemics and dynamics for automatically identifying conversing groups, or so-called F-formations. More formally we aim to automatically identify whether wearable sensor data coming from 2 people is indicative of F-formation membership. We also explore the problem of jointly detecting membership and more descriptive information about the pair relating to the role they take in the conversation (i.e. speaker or listener). We jointly model the concepts of proxemics and dynamics using binary proximity and acceleration obtained through a single wearable sensor per person. We test our approaches on the publicly available MatchNMingle dataset which was collected during real-life mingling events. We find out that fusion of these two modalities performs significantly better than them independently, providing an AUC of 0.975 when data from 30-second windows are used. Furthermore, our investigation into roles detection shows that each role pair requires a different time resolution for accurate detection.