 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn FPGA-Based SoC Architecture with a RISC-V Controller for Energy-Efficient Temporal-Coding Spiking Neural Networks
Mar 17, 2026Spiking Neural Networks (SNNs) offer high energy efficiency and event-driven computation, ideal for low-power edge AI. Their hardware implementation on FPGAs, however, faces challenges due to heavy computation, large memory use, and limited flexibility. This paper proposes a compact System-on-Chip (SoC) architecture for temporal-coding SNNs, integrating a RISC-V controller with an event-driven SNN core. It replaces multipliers with bitwise operations using binarized weights, includes a spike-time sorter for active spikes, and skips noninformative events to reduce computation. The architecture runs fully on a Xilinx Artix-7 FPGA, achieving up to 16x memory reduction for weights and lowering computational overhead and latency, with 97.0% accuracy on MNIST and 88.3% on FashionMNIST. This self-contained design provides an efficient, scalable platform for real-time neuromorphic inference at the edge.
SPARQ: Spiking Early-Exit Neural Networks for Energy-Efficient Edge AI
Mar 15, 2026Spiking neural networks (SNNs) offer inherent energy efficiency due to their event-driven computation model, making them promising for edge AI deployment. However, their practical adoption is limited by the computational overhead of deep architectures and the absence of input-adaptive control. This work presents SPARQ, a unified framework that integrates spiking computation, quantization-aware training, and reinforcement learning-guided early exits for efficient and adaptive inference. Evaluations across MLP, LeNet, and AlexNet architectures demonstrated that the proposed Quantised Dynamic SNNs (QDSNN) consistently outperform conventional SNNs and QSNNs, achieving up to 5.15% higher accuracy over QSNNs, over 330 times lower system energy compared to baseline SNNs, and over 90 percent fewer synaptic operations across different datasets. These results validate SPARQ as a hardware-friendly, energy-efficient solution for real-time AI at the edge.
HAWX: A Hardware-Aware FrameWork for Fast and Scalable ApproXimation of DNNs
Feb 18, 2026This work presents HAWX, a hardware-aware scalable exploration framework that employs multi-level sensitivity scoring at different DNN abstraction levels (operator, filter, layer, and model) to guide selective integration of heterogeneous AxC blocks. Supported by predictive models for accuracy, power, and area, HAWX accelerates the evaluation of candidate configurations, achieving over 23* speedup in a layer-level search with two candidate approximate blocks and more than (3*106)* speedup at the filter-level search only for LeNet-5, while maintaining accuracy comparable to exhaustive search. Experiments across state-of-the-art DNN benchmarks such as VGG-11, ResNet-18, and EfficientNetLite demonstrate that the efficiency benefits of HAWX scale exponentially with network size. The HAWX hardware-aware search algorithm supports both spatial and temporal accelerator architectures, leveraging either off-the-shelf approximate components or customized designs.
Exploring DNN Robustness Against Adversarial Attacks Using Approximate Multipliers
Apr 17, 2024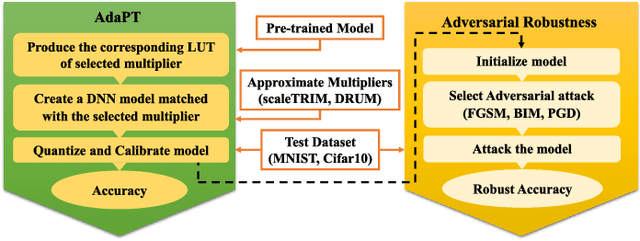
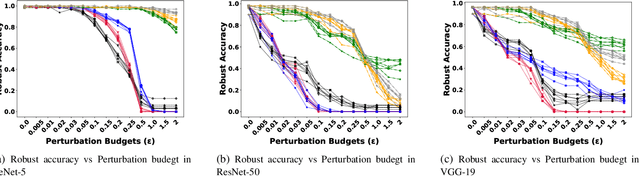
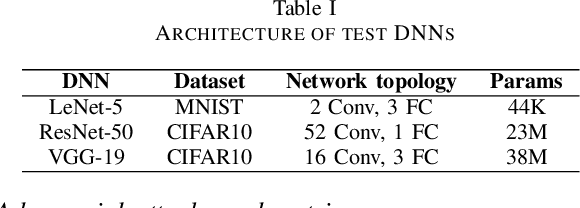

Deep Neural Networks (DNNs) have advanced in many real-world applications, such as healthcare and autonomous driving. However, their high computational complexity and vulnerability to adversarial attacks are ongoing challenges. In this letter, approximate multipliers are used to explore DNN robustness improvement against adversarial attacks. By uniformly replacing accurate multipliers for state-of-the-art approximate ones in DNN layer models, we explore the DNNs robustness against various adversarial attacks in a feasible time. Results show up to 7% accuracy drop due to approximations when no attack is present while improving robust accuracy up to 10% when attacks applied.
Exploration of Activation Fault Reliability in Quantized Systolic Array-Based DNN Accelerators
Jan 17, 2024The stringent requirements for the Deep Neural Networks (DNNs) accelerator's reliability stand along with the need for reducing the computational burden on the hardware platforms, i.e. reducing the energy consumption and execution time as well as increasing the efficiency of DNN accelerators. Moreover, the growing demand for specialized DNN accelerators with tailored requirements, particularly for safety-critical applications, necessitates a comprehensive design space exploration to enable the development of efficient and robust accelerators that meet those requirements. Therefore, the trade-off between hardware performance, i.e. area and delay, and the reliability of the DNN accelerator implementation becomes critical and requires tools for analysis. This paper presents a comprehensive methodology for exploring and enabling a holistic assessment of the trilateral impact of quantization on model accuracy, activation fault reliability, and hardware efficiency. A fully automated framework is introduced that is capable of applying various quantization-aware techniques, fault injection, and hardware implementation, thus enabling the measurement of hardware parameters. Moreover, this paper proposes a novel lightweight protection technique integrated within the framework to ensure the dependable deployment of the final systolic-array-based FPGA implementation. The experiments on established benchmarks demonstrate the analysis flow and the profound implications of quantization on reliability, hardware performance, and network accuracy, particularly concerning the transient faults in the network's activations.
A Novel Fault-Tolerant Logic Style with Self-Checking Capability
May 31, 2023We introduce a novel logic style with self-checking capability to enhance hardware reliability at logic level. The proposed logic cells have two-rail inputs/outputs, and the functionality for each rail of outputs enables construction of faulttolerant configurable circuits. The AND and OR gates consist of 8 transistors based on CNFET technology, while the proposed XOR gate benefits from both CNFET and low-power MGDI technologies in its transistor arrangement. To demonstrate the feasibility of our new logic gates, we used an AES S-box implementation as the use case. The extensive simulation results using HSPICE indicate that the case-study circuit using on proposed gates has superior speed and power consumption compared to other implementations with error-detection capability
LRDB: LSTM Raw data DNA Base-caller based on long-short term models in an active learning environment
Mar 15, 2023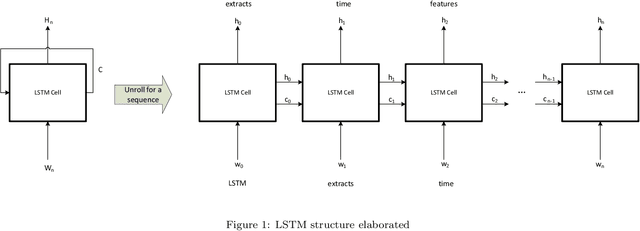
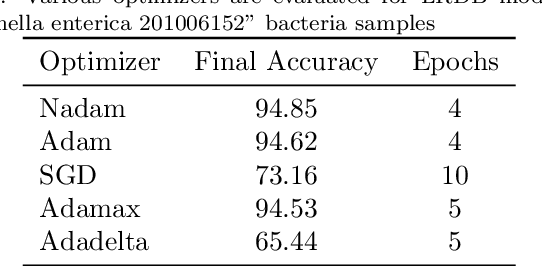
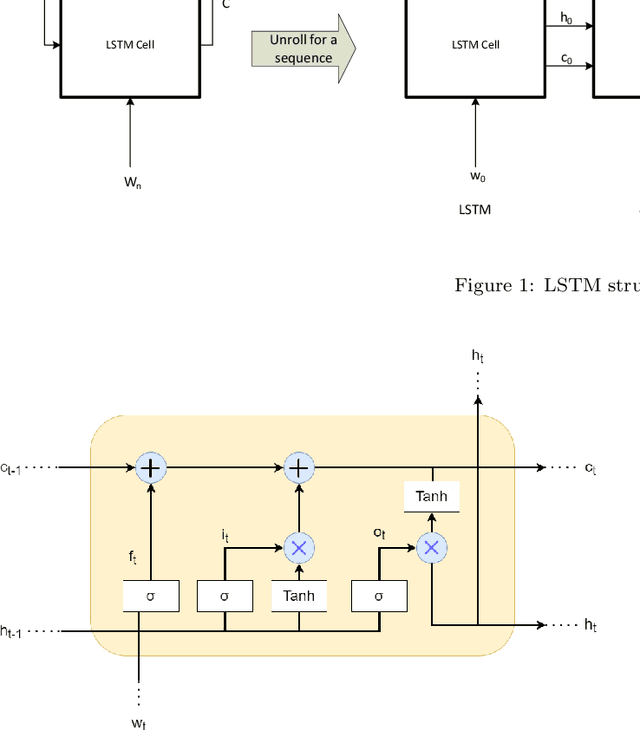
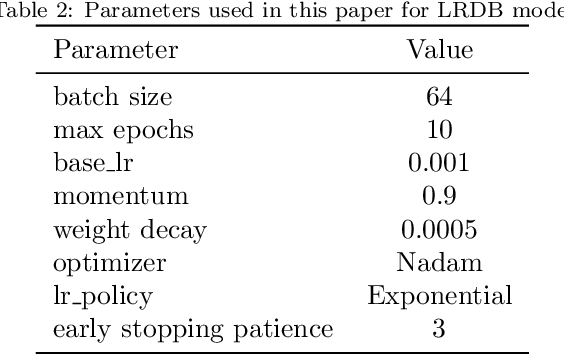
The first important step in extracting DNA characters is using the output data of MinION devices in the form of electrical current signals. Various cutting-edge base callers use this data to detect the DNA characters based on the input. In this paper, we discuss several shortcomings of prior base callers in the case of time-critical applications, privacy-aware design, and the problem of catastrophic forgetting. Next, we propose the LRDB model, a lightweight open-source model for private developments with a better read-identity (0.35% increase) for the target bacterial samples in the paper. We have limited the extent of training data and benefited from the transfer learning algorithm to make the active usage of the LRDB viable in critical applications. Henceforth, less training time for adapting to new DNA samples (in our case, Bacterial samples) is needed. Furthermore, LRDB can be modified concerning the user constraints as the results show a negligible accuracy loss in case of using fewer parameters. We have also assessed the noise-tolerance property, which offers about a 1.439% decline in accuracy for a 15dB noise injection, and the performance metrics show that the model executes in a medium speed range compared with current cutting-edge models.