 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictor-Free and Hardware-Aware Federated Neural Architecture Search via Pareto-Guided Supernet Training
Jan 28, 2026Federated Neural Architecture Search (FedNAS) aims to automate model design for privacy-preserving Federated Learning (FL) but currently faces two critical bottlenecks: unguided supernet training that yields suboptimal models, and costly multi-hour pipelines for post-training subnet discovery. We introduce DeepFedNAS, a novel, two-phase framework underpinned by a multi-objective fitness function that synthesizes mathematical network design with architectural heuristics. Enabled by a re-engineered supernet, DeepFedNAS introduces Federated Pareto Optimal Supernet Training, which leverages a pre-computed Pareto-optimal cache of high-fitness architectures as an intelligent curriculum to optimize shared supernet weights. Subsequently, its Predictor-Free Search Method eliminates the need for costly accuracy surrogates by utilizing this fitness function as a direct, zero-cost proxy for accuracy, enabling on-demand subnet discovery in mere seconds. DeepFedNAS achieves state-of-the-art accuracy (e.g., up to 1.21% absolute improvement on CIFAR-100), superior parameter and communication efficiency, and a substantial ~61x speedup in total post-training search pipeline time. By reducing the pipeline from over 20 hours to approximately 20 minutes (including initial cache generation) and enabling 20-second individual subnet searches, DeepFedNAS makes hardware-aware FL deployments instantaneous and practical. The complete source code and experimental scripts are available at: https://github.com/bostankhan6/DeepFedNAS
Contextual Range-View Projection for 3D LiDAR Point Clouds
Jan 26, 2026Range-view projection provides an efficient method for transforming 3D LiDAR point clouds into 2D range image representations, enabling effective processing with 2D deep learning models. However, a major challenge in this projection is the many-to-one conflict, where multiple 3D points are mapped onto the same pixel in the range image, requiring a selection strategy. Existing approaches typically retain the point with the smallest depth (closest to the LiDAR), disregarding semantic relevance and object structure, which leads to the loss of important contextual information. In this paper, we extend the depth-based selection rule by incorporating contextual information from both instance centers and class labels, introducing two mechanisms: \textit{Centerness-Aware Projection (CAP)} and \textit{Class-Weighted-Aware Projection (CWAP)}. In CAP, point depths are adjusted according to their distance from the instance center, thereby prioritizing central instance points over noisy boundary and background points. In CWAP, object classes are prioritized through user-defined weights, offering flexibility in the projection strategy. Our evaluations on the SemanticKITTI dataset show that CAP preserves more instance points during projection, achieving up to a 3.1\% mIoU improvement compared to the baseline. Furthermore, CWAP enhances the performance of targeted classes while having a negligible impact on the performance of other classes
DeepFedNAS: A Unified Framework for Principled, Hardware-Aware, and Predictor-Free Federated Neural Architecture Search
Jan 21, 2026Federated Neural Architecture Search (FedNAS) aims to automate model design for privacy-preserving Federated Learning (FL) but currently faces two critical bottlenecks: unguided supernet training that yields suboptimal models, and costly multi-hour pipelines for post-training subnet discovery. We introduce DeepFedNAS, a novel, two-phase framework underpinned by a principled, multi-objective fitness function that synthesizes mathematical network design with architectural heuristics. Enabled by a re-engineered supernet, DeepFedNAS introduces Federated Pareto Optimal Supernet Training, which leverages a pre-computed Pareto-optimal cache of high-fitness architectures as an intelligent curriculum to optimize shared supernet weights. Subsequently, its Predictor-Free Search Method eliminates the need for costly accuracy surrogates by utilizing this fitness function as a direct, zero-cost proxy for accuracy, enabling on-demand subnet discovery in mere seconds. DeepFedNAS achieves state-of-the-art accuracy (e.g., up to 1.21% absolute improvement on CIFAR-100), superior parameter and communication efficiency, and a substantial ~61x speedup in total post-training search pipeline time. By reducing the pipeline from over 20 hours to approximately 20 minutes (including initial cache generation) and enabling 20-second individual subnet searches, DeepFedNAS makes hardware-aware FL deployments instantaneous and practical. The complete source code and experimental scripts are available at: https://github.com/bostankhan6/DeepFedNAS
Correcting and Quantifying Systematic Errors in 3D Box Annotations for Autonomous Driving
Jan 20, 2026Accurate ground truth annotations are critical to supervised learning and evaluating the performance of autonomous vehicle systems. These vehicles are typically equipped with active sensors, such as LiDAR, which scan the environment in predefined patterns. 3D box annotation based on data from such sensors is challenging in dynamic scenarios, where objects are observed at different timestamps, hence different positions. Without proper handling of this phenomenon, systematic errors are prone to being introduced in the box annotations. Our work is the first to discover such annotation errors in widely used, publicly available datasets. Through our novel offline estimation method, we correct the annotations so that they follow physically feasible trajectories and achieve spatial and temporal consistency with the sensor data. For the first time, we define metrics for this problem; and we evaluate our method on the Argoverse 2, MAN TruckScenes, and our proprietary datasets. Our approach increases the quality of box annotations by more than 17% in these datasets. Furthermore, we quantify the annotation errors in them and find that the original annotations are misplaced by up to 2.5 m, with highly dynamic objects being the most affected. Finally, we test the impact of the errors in benchmarking and find that the impact is larger than the improvements that state-of-the-art methods typically achieve with respect to the previous state-of-the-art methods; showing that accurate annotations are essential for correct interpretation of performance. Our code is available at https://github.com/alexandre-justo-miro/annotation-correction-3D-boxes.
ProARD: progressive adversarial robustness distillation: provide wide range of robust students
Jun 09, 2025



Adversarial Robustness Distillation (ARD) has emerged as an effective method to enhance the robustness of lightweight deep neural networks against adversarial attacks. Current ARD approaches have leveraged a large robust teacher network to train one robust lightweight student. However, due to the diverse range of edge devices and resource constraints, current approaches require training a new student network from scratch to meet specific constraints, leading to substantial computational costs and increased CO2 emissions. This paper proposes Progressive Adversarial Robustness Distillation (ProARD), enabling the efficient one-time training of a dynamic network that supports a diverse range of accurate and robust student networks without requiring retraining. We first make a dynamic deep neural network based on dynamic layers by encompassing variations in width, depth, and expansion in each design stage to support a wide range of architectures. Then, we consider the student network with the largest size as the dynamic teacher network. ProARD trains this dynamic network using a weight-sharing mechanism to jointly optimize the dynamic teacher network and its internal student networks. However, due to the high computational cost of calculating exact gradients for all the students within the dynamic network, a sampling mechanism is required to select a subset of students. We show that random student sampling in each iteration fails to produce accurate and robust students.
Exploring FMCW Radars and Feature Maps for Activity Recognition: A Benchmark Study
Mar 07, 2025



Human Activity Recognition has gained significant attention due to its diverse applications, including ambient assisted living and remote sensing. Wearable sensor-based solutions often suffer from user discomfort and reliability issues, while video-based methods raise privacy concerns and perform poorly in low-light conditions or long ranges. This study introduces a Frequency-Modulated Continuous Wave radar-based framework for human activity recognition, leveraging a 60 GHz radar and multi-dimensional feature maps. Unlike conventional approaches that process feature maps as images, this study feeds multi-dimensional feature maps -- Range-Doppler, Range-Azimuth, and Range-Elevation -- as data vectors directly into the machine learning (SVM, MLP) and deep learning (CNN, LSTM, ConvLSTM) models, preserving the spatial and temporal structures of the data. These features were extracted from a novel dataset with seven activity classes and validated using two different validation approaches. The ConvLSTM model outperformed conventional machine learning and deep learning models, achieving an accuracy of 90.51% and an F1-score of 87.31% on cross-scene validation and an accuracy of 89.56% and an F1-score of 87.15% on leave-one-person-out cross-validation. The results highlight the approach's potential for scalable, non-intrusive, and privacy-preserving activity monitoring in real-world scenarios.
DeepVigor+: Scalable and Accurate Semi-Analytical Fault Resilience Analysis for Deep Neural Network
Oct 21, 2024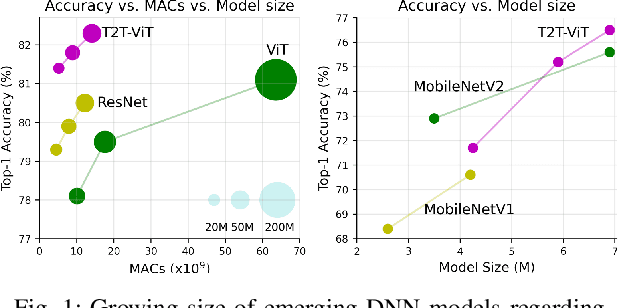


Growing exploitation of Machine Learning (ML) in safety-critical applications necessitates rigorous safety analysis. Hardware reliability assessment is a major concern with respect to measuring the level of safety. Quantifying the reliability of emerging ML models, including Deep Neural Networks (DNNs), is highly complex due to their enormous size in terms of the number of parameters and computations. Conventionally, Fault Injection (FI) is applied to perform a reliability measurement. However, performing FI on modern-day DNNs is prohibitively time-consuming if an acceptable confidence level is to be achieved. In order to speed up FI for large DNNs, statistical FI has been proposed. However, the run-time for the large DNN models is still considerably long. In this work, we introduce DeepVigor+, a scalable, fast and accurate semi-analytical method as an efficient alternative for reliability measurement in DNNs. DeepVigor+ implements a fault propagation analysis model and attempts to acquire Vulnerability Factors (VFs) as reliability metrics in an optimal way. The results indicate that DeepVigor+ obtains VFs for DNN models with an error less than 1\% and 14.9 up to 26.9 times fewer simulations than the best-known state-of-the-art statistical FI enabling an accurate reliability analysis for emerging DNNs within a few minutes.
ProAct: Progressive Training for Hybrid Clipped Activation Function to Enhance Resilience of DNNs
Jun 10, 2024Deep Neural Networks (DNNs) are extensively employed in safety-critical applications where ensuring hardware reliability is a primary concern. To enhance the reliability of DNNs against hardware faults, activation restriction techniques significantly mitigate the fault effects at the DNN structure level, irrespective of accelerator architectures. State-of-the-art methods offer either neuron-wise or layer-wise clipping activation functions. They attempt to determine optimal clipping thresholds using heuristic and learning-based approaches. Layer-wise clipped activation functions cannot preserve DNNs resilience at high bit error rates. On the other hand, neuron-wise clipping activation functions introduce considerable memory overhead due to the addition of parameters, which increases their vulnerability to faults. Moreover, the heuristic-based optimization approach demands numerous fault injections during the search process, resulting in time-consuming threshold identification. On the other hand, learning-based techniques that train thresholds for entire layers concurrently often yield sub-optimal results. In this work, first, we demonstrate that it is not essential to incorporate neuron-wise activation functions throughout all layers in DNNs. Then, we propose a hybrid clipped activation function that integrates neuron-wise and layer-wise methods that apply neuron-wise clipping only in the last layer of DNNs. Additionally, to attain optimal thresholds in the clipping activation function, we introduce ProAct, a progressive training methodology. This approach iteratively trains the thresholds on a layer-by-layer basis, aiming to obtain optimal threshold values in each layer separately.
Cost-Effective Fault Tolerance for CNNs Using Parameter Vulnerability Based Hardening and Pruning
May 17, 2024



Convolutional Neural Networks (CNNs) have become integral in safety-critical applications, thus raising concerns about their fault tolerance. Conventional hardware-dependent fault tolerance methods, such as Triple Modular Redundancy (TMR), are computationally expensive, imposing a remarkable overhead on CNNs. Whereas fault tolerance techniques can be applied either at the hardware level or at the model levels, the latter provides more flexibility without sacrificing generality. This paper introduces a model-level hardening approach for CNNs by integrating error correction directly into the neural networks. The approach is hardware-agnostic and does not require any changes to the underlying accelerator device. Analyzing the vulnerability of parameters enables the duplication of selective filters/neurons so that their output channels are effectively corrected with an efficient and robust correction layer. The proposed method demonstrates fault resilience nearly equivalent to TMR-based correction but with significantly reduced overhead. Nevertheless, there exists an inherent overhead to the baseline CNNs. To tackle this issue, a cost-effective parameter vulnerability based pruning technique is proposed that outperforms the conventional pruning method, yielding smaller networks with a negligible accuracy loss. Remarkably, the hardened pruned CNNs perform up to 24\% faster than the hardened un-pruned ones.
TrajectoryNAS: A Neural Architecture Search for Trajectory Prediction
Mar 18, 2024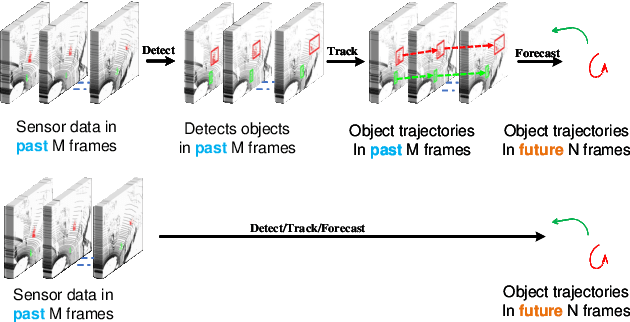
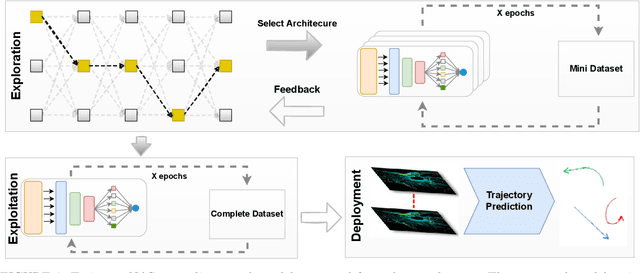

Autonomous driving systems are a rapidly evolving technology that enables driverless car production. Trajectory prediction is a critical component of autonomous driving systems, enabling cars to anticipate the movements of surrounding objects for safe navigation. Trajectory prediction using Lidar point-cloud data performs better than 2D images due to providing 3D information. However, processing point-cloud data is more complicated and time-consuming than 2D images. Hence, state-of-the-art 3D trajectory predictions using point-cloud data suffer from slow and erroneous predictions. This paper introduces TrajectoryNAS, a pioneering method that focuses on utilizing point cloud data for trajectory prediction. By leveraging Neural Architecture Search (NAS), TrajectoryNAS automates the design of trajectory prediction models, encompassing object detection, tracking, and forecasting in a cohesive manner. This approach not only addresses the complex interdependencies among these tasks but also emphasizes the importance of accuracy and efficiency in trajectory modeling. Through empirical studies, TrajectoryNAS demonstrates its effectiveness in enhancing the performance of autonomous driving systems, marking a significant advancement in the field.Experimental results reveal that TrajcetoryNAS yield a minimum of 4.8 higger accuracy and 1.1* lower latency over competing methods on the NuScenes dataset.