 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Pruning with Quantization for Efficient Deep Neural Networks Compression
Sep 04, 2025Deep Neural Networks (DNNs) have achieved significant advances in a wide range of applications. However, their deployment on resource-constrained devices remains a challenge due to the large number of layers and parameters, which result in considerable computational and memory demands. To address this issue, pruning and quantization are two widely used compression techniques, commonly applied individually in most studies to reduce model size and enhance processing speed. Nevertheless, combining these two techniques can yield even greater compression benefits. Effectively integrating pruning and quantization to harness their complementary advantages poses a challenging task, primarily due to their potential impact on model accuracy and the complexity of jointly optimizing both processes. In this paper, we propose two approaches that integrate similarity-based filter pruning with Adaptive Power-of-Two (APoT) quantization to achieve higher compression efficiency while preserving model accuracy. In the first approach, pruning and quantization are applied simultaneously during training. In the second approach, pruning is performed first to remove less important parameters, followed by quantization of the pruned model using low-bit representations. Experimental results demonstrate that our proposed approaches achieve effective model compression with minimal accuracy degradation, making them well-suited for deployment on devices with limited computational resources.
AdAM: Adaptive Fault-Tolerant Approximate Multiplier for Edge DNN Accelerators
Mar 05, 2024In this paper, we propose an architecture of a novel adaptive fault-tolerant approximate multiplier tailored for ASIC-based DNN accelerators.
A Comprehensive Survey on Model Quantization for Deep Neural Networks
May 14, 2022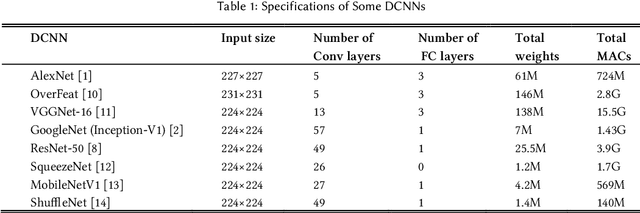
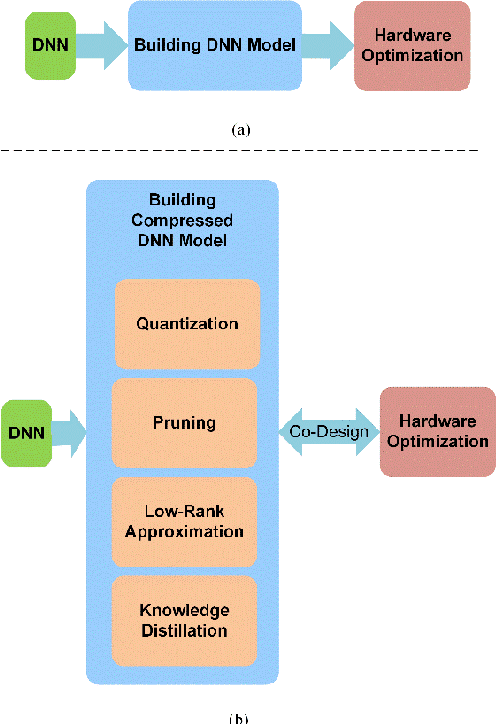
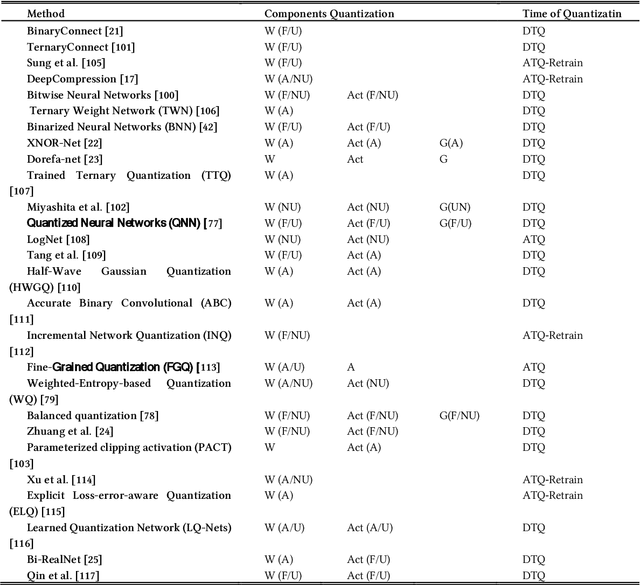
Recent advances in machine learning by deep neural networks are significant. But using these networks has been accompanied by a huge number of parameters for storage and computations that leads to an increase in the hardware cost and posing challenges. Therefore, compression approaches have been proposed to design efficient accelerators. One important approach for deep neural network compression is quantization that full-precision values are stored in low bit-width. In this way, in addition to memory saving, the operations will be replaced by simple ones with low cost. Many methods are suggested for DNNs Quantization in recent years, because of flexibility and influence in designing efficient hardware. Therefore, an integrated report is essential for better understanding, analysis, and comparison. In this paper, we provide a comprehensive survey. We describe the quantization concepts and categorize the methods from different perspectives. We discuss using the scale factor to match the quantization levels with the distribution of the full-precision values and describe the clustering-based methods. For the first time, we review the training of a quantized deep neural network and using Straight-Through Estimator comprehensively. Also, we describe the simplicity of operations in quantized deep convolutional neural networks and explain the sensitivity of the different layers in quantization. Finally, we discuss the evaluation of the quantization methods and compare the accuracy of previous methods with various bit-width for weights and activations on CIFAR-10 and the large-scale dataset, ImageNet.