 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen and Sustainable AI: challenges, opportunities and the road ahead in the life sciences
May 22, 2025


Artificial intelligence (AI) has recently seen transformative breakthroughs in the life sciences, expanding possibilities for researchers to interpret biological information at an unprecedented capacity, with novel applications and advances being made almost daily. In order to maximise return on the growing investments in AI-based life science research and accelerate this progress, it has become urgent to address the exacerbation of long-standing research challenges arising from the rapid adoption of AI methods. We review the increased erosion of trust in AI research outputs, driven by the issues of poor reusability and reproducibility, and highlight their consequent impact on environmental sustainability. Furthermore, we discuss the fragmented components of the AI ecosystem and lack of guiding pathways to best support Open and Sustainable AI (OSAI) model development. In response, this perspective introduces a practical set of OSAI recommendations directly mapped to over 300 components of the AI ecosystem. Our work connects researchers with relevant AI resources, facilitating the implementation of sustainable, reusable and transparent AI. Built upon life science community consensus and aligned to existing efforts, the outputs of this perspective are designed to aid the future development of policy and structured pathways for guiding AI implementation.
Exploring the use of a Large Language Model for data extraction in systematic reviews: a rapid feasibility study
May 23, 2024
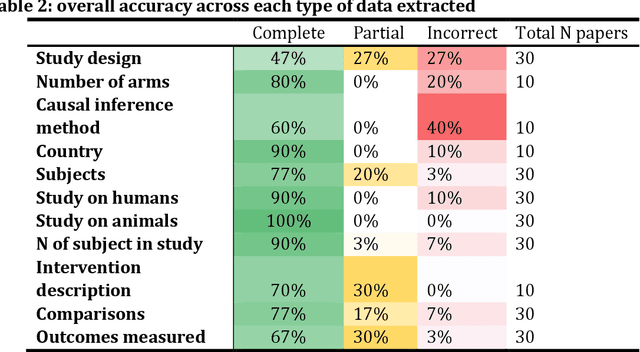


This paper describes a rapid feasibility study of using GPT-4, a large language model (LLM), to (semi)automate data extraction in systematic reviews. Despite the recent surge of interest in LLMs there is still a lack of understanding of how to design LLM-based automation tools and how to robustly evaluate their performance. During the 2023 Evidence Synthesis Hackathon we conducted two feasibility studies. Firstly, to automatically extract study characteristics from human clinical, animal, and social science domain studies. We used two studies from each category for prompt-development; and ten for evaluation. Secondly, we used the LLM to predict Participants, Interventions, Controls and Outcomes (PICOs) labelled within 100 abstracts in the EBM-NLP dataset. Overall, results indicated an accuracy of around 80%, with some variability between domains (82% for human clinical, 80% for animal, and 72% for studies of human social sciences). Causal inference methods and study design were the data extraction items with the most errors. In the PICO study, participants and intervention/control showed high accuracy (>80%), outcomes were more challenging. Evaluation was done manually; scoring methods such as BLEU and ROUGE showed limited value. We observed variability in the LLMs predictions and changes in response quality. This paper presents a template for future evaluations of LLMs in the context of data extraction for systematic review automation. Our results show that there might be value in using LLMs, for example as second or third reviewers. However, caution is advised when integrating models such as GPT-4 into tools. Further research on stability and reliability in practical settings is warranted for each type of data that is processed by the LLM.
* Conference proceedings, peer-reviewed and presented at the 3rd Workshop on Augmented Intelligence for Technology-Assisted Reviews Systems, Glasgow, 2024
A Comprehensive Survey on Model Quantization for Deep Neural Networks
May 14, 2022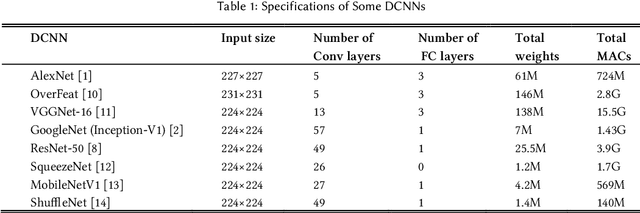
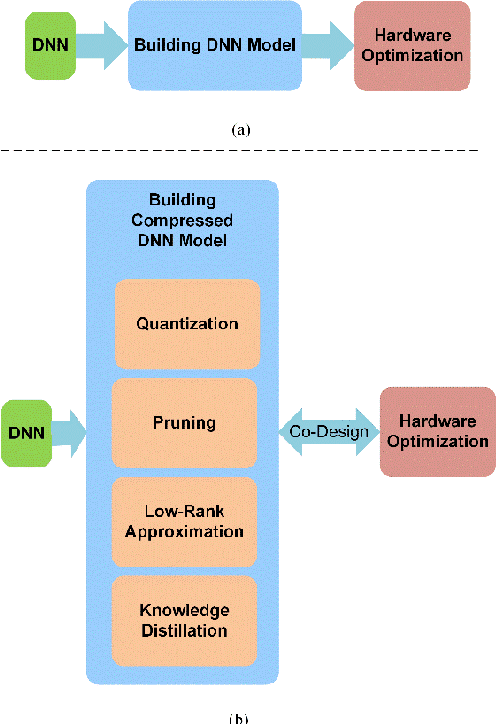
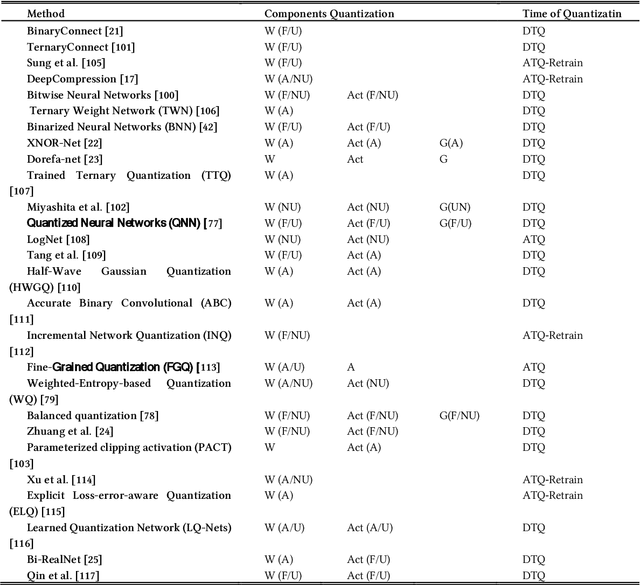
Recent advances in machine learning by deep neural networks are significant. But using these networks has been accompanied by a huge number of parameters for storage and computations that leads to an increase in the hardware cost and posing challenges. Therefore, compression approaches have been proposed to design efficient accelerators. One important approach for deep neural network compression is quantization that full-precision values are stored in low bit-width. In this way, in addition to memory saving, the operations will be replaced by simple ones with low cost. Many methods are suggested for DNNs Quantization in recent years, because of flexibility and influence in designing efficient hardware. Therefore, an integrated report is essential for better understanding, analysis, and comparison. In this paper, we provide a comprehensive survey. We describe the quantization concepts and categorize the methods from different perspectives. We discuss using the scale factor to match the quantization levels with the distribution of the full-precision values and describe the clustering-based methods. For the first time, we review the training of a quantized deep neural network and using Straight-Through Estimator comprehensively. Also, we describe the simplicity of operations in quantized deep convolutional neural networks and explain the sensitivity of the different layers in quantization. Finally, we discuss the evaluation of the quantization methods and compare the accuracy of previous methods with various bit-width for weights and activations on CIFAR-10 and the large-scale dataset, ImageNet.