 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORTALESA: Fault-Tolerant Reconfigurable Systolic Array for DNN Inference
Mar 06, 2025The emergence of Deep Neural Networks (DNNs) in mission- and safety-critical applications brings their reliability to the front. High performance demands of DNNs require the use of specialized hardware accelerators. Systolic array architecture is widely used in DNN accelerators due to its parallelism and regular structure. This work presents a run-time reconfigurable systolic array architecture with three execution modes and four implementation options. All four implementations are evaluated in terms of resource utilization, throughput, and fault tolerance improvement. The proposed architecture is used for reliability enhancement of DNN inference on systolic array through heterogeneous mapping of different network layers to different execution modes. The approach is supported by a novel reliability assessment method based on fault propagation analysis. It is used for the exploration of the appropriate execution mode-layer mapping for DNN inference. The proposed architecture efficiently protects registers and MAC units of systolic array PEs from transient and permanent faults. The reconfigurability feature enables a speedup of up to $3\times$, depending on layer vulnerability. Furthermore, it requires $6\times$ less resources compared to static redundancy and $2.5\times$ less resources compared to the previously proposed solution for transient faults.
DeepVigor+: Scalable and Accurate Semi-Analytical Fault Resilience Analysis for Deep Neural Network
Oct 21, 2024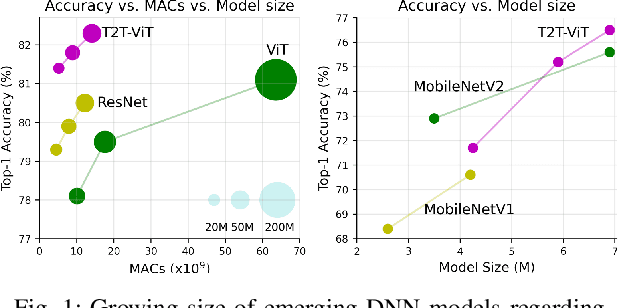


Growing exploitation of Machine Learning (ML) in safety-critical applications necessitates rigorous safety analysis. Hardware reliability assessment is a major concern with respect to measuring the level of safety. Quantifying the reliability of emerging ML models, including Deep Neural Networks (DNNs), is highly complex due to their enormous size in terms of the number of parameters and computations. Conventionally, Fault Injection (FI) is applied to perform a reliability measurement. However, performing FI on modern-day DNNs is prohibitively time-consuming if an acceptable confidence level is to be achieved. In order to speed up FI for large DNNs, statistical FI has been proposed. However, the run-time for the large DNN models is still considerably long. In this work, we introduce DeepVigor+, a scalable, fast and accurate semi-analytical method as an efficient alternative for reliability measurement in DNNs. DeepVigor+ implements a fault propagation analysis model and attempts to acquire Vulnerability Factors (VFs) as reliability metrics in an optimal way. The results indicate that DeepVigor+ obtains VFs for DNN models with an error less than 1\% and 14.9 up to 26.9 times fewer simulations than the best-known state-of-the-art statistical FI enabling an accurate reliability analysis for emerging DNNs within a few minutes.
ProAct: Progressive Training for Hybrid Clipped Activation Function to Enhance Resilience of DNNs
Jun 10, 2024Deep Neural Networks (DNNs) are extensively employed in safety-critical applications where ensuring hardware reliability is a primary concern. To enhance the reliability of DNNs against hardware faults, activation restriction techniques significantly mitigate the fault effects at the DNN structure level, irrespective of accelerator architectures. State-of-the-art methods offer either neuron-wise or layer-wise clipping activation functions. They attempt to determine optimal clipping thresholds using heuristic and learning-based approaches. Layer-wise clipped activation functions cannot preserve DNNs resilience at high bit error rates. On the other hand, neuron-wise clipping activation functions introduce considerable memory overhead due to the addition of parameters, which increases their vulnerability to faults. Moreover, the heuristic-based optimization approach demands numerous fault injections during the search process, resulting in time-consuming threshold identification. On the other hand, learning-based techniques that train thresholds for entire layers concurrently often yield sub-optimal results. In this work, first, we demonstrate that it is not essential to incorporate neuron-wise activation functions throughout all layers in DNNs. Then, we propose a hybrid clipped activation function that integrates neuron-wise and layer-wise methods that apply neuron-wise clipping only in the last layer of DNNs. Additionally, to attain optimal thresholds in the clipping activation function, we introduce ProAct, a progressive training methodology. This approach iteratively trains the thresholds on a layer-by-layer basis, aiming to obtain optimal threshold values in each layer separately.
Cost-Effective Fault Tolerance for CNNs Using Parameter Vulnerability Based Hardening and Pruning
May 17, 2024



Convolutional Neural Networks (CNNs) have become integral in safety-critical applications, thus raising concerns about their fault tolerance. Conventional hardware-dependent fault tolerance methods, such as Triple Modular Redundancy (TMR), are computationally expensive, imposing a remarkable overhead on CNNs. Whereas fault tolerance techniques can be applied either at the hardware level or at the model levels, the latter provides more flexibility without sacrificing generality. This paper introduces a model-level hardening approach for CNNs by integrating error correction directly into the neural networks. The approach is hardware-agnostic and does not require any changes to the underlying accelerator device. Analyzing the vulnerability of parameters enables the duplication of selective filters/neurons so that their output channels are effectively corrected with an efficient and robust correction layer. The proposed method demonstrates fault resilience nearly equivalent to TMR-based correction but with significantly reduced overhead. Nevertheless, there exists an inherent overhead to the baseline CNNs. To tackle this issue, a cost-effective parameter vulnerability based pruning technique is proposed that outperforms the conventional pruning method, yielding smaller networks with a negligible accuracy loss. Remarkably, the hardened pruned CNNs perform up to 24\% faster than the hardened un-pruned ones.
AdAM: Adaptive Fault-Tolerant Approximate Multiplier for Edge DNN Accelerators
Mar 05, 2024In this paper, we propose an architecture of a novel adaptive fault-tolerant approximate multiplier tailored for ASIC-based DNN accelerators.
SAFFIRA: a Framework for Assessing the Reliability of Systolic-Array-Based DNN Accelerators
Mar 05, 2024



Systolic array has emerged as a prominent architecture for Deep Neural Network (DNN) hardware accelerators, providing high-throughput and low-latency performance essential for deploying DNNs across diverse applications. However, when used in safety-critical applications, reliability assessment is mandatory to guarantee the correct behavior of DNN accelerators. While fault injection stands out as a well-established practical and robust method for reliability assessment, it is still a very time-consuming process. This paper addresses the time efficiency issue by introducing a novel hierarchical software-based hardware-aware fault injection strategy tailored for systolic array-based DNN accelerators.
Exploration of Activation Fault Reliability in Quantized Systolic Array-Based DNN Accelerators
Jan 17, 2024The stringent requirements for the Deep Neural Networks (DNNs) accelerator's reliability stand along with the need for reducing the computational burden on the hardware platforms, i.e. reducing the energy consumption and execution time as well as increasing the efficiency of DNN accelerators. Moreover, the growing demand for specialized DNN accelerators with tailored requirements, particularly for safety-critical applications, necessitates a comprehensive design space exploration to enable the development of efficient and robust accelerators that meet those requirements. Therefore, the trade-off between hardware performance, i.e. area and delay, and the reliability of the DNN accelerator implementation becomes critical and requires tools for analysis. This paper presents a comprehensive methodology for exploring and enabling a holistic assessment of the trilateral impact of quantization on model accuracy, activation fault reliability, and hardware efficiency. A fully automated framework is introduced that is capable of applying various quantization-aware techniques, fault injection, and hardware implementation, thus enabling the measurement of hardware parameters. Moreover, this paper proposes a novel lightweight protection technique integrated within the framework to ensure the dependable deployment of the final systolic-array-based FPGA implementation. The experiments on established benchmarks demonstrate the analysis flow and the profound implications of quantization on reliability, hardware performance, and network accuracy, particularly concerning the transient faults in the network's activations.
Enhancing Fault Resilience of QNNs by Selective Neuron Splitting
Jun 16, 2023The superior performance of Deep Neural Networks (DNNs) has led to their application in various aspects of human life. Safety-critical applications are no exception and impose rigorous reliability requirements on DNNs. Quantized Neural Networks (QNNs) have emerged to tackle the complexity of DNN accelerators, however, they are more prone to reliability issues. In this paper, a recent analytical resilience assessment method is adapted for QNNs to identify critical neurons based on a Neuron Vulnerability Factor (NVF). Thereafter, a novel method for splitting the critical neurons is proposed that enables the design of a Lightweight Correction Unit (LCU) in the accelerator without redesigning its computational part. The method is validated by experiments on different QNNs and datasets. The results demonstrate that the proposed method for correcting the faults has a twice smaller overhead than a selective Triple Modular Redundancy (TMR) while achieving a similar level of fault resiliency.
A Novel Fault-Tolerant Logic Style with Self-Checking Capability
May 31, 2023We introduce a novel logic style with self-checking capability to enhance hardware reliability at logic level. The proposed logic cells have two-rail inputs/outputs, and the functionality for each rail of outputs enables construction of faulttolerant configurable circuits. The AND and OR gates consist of 8 transistors based on CNFET technology, while the proposed XOR gate benefits from both CNFET and low-power MGDI technologies in its transistor arrangement. To demonstrate the feasibility of our new logic gates, we used an AES S-box implementation as the use case. The extensive simulation results using HSPICE indicate that the case-study circuit using on proposed gates has superior speed and power consumption compared to other implementations with error-detection capability
APPRAISER: DNN Fault Resilience Analysis Employing Approximation Errors
May 31, 2023



Nowadays, the extensive exploitation of Deep Neural Networks (DNNs) in safety-critical applications raises new reliability concerns. In practice, methods for fault injection by emulation in hardware are efficient and widely used to study the resilience of DNN architectures for mitigating reliability issues already at the early design stages. However, the state-of-the-art methods for fault injection by emulation incur a spectrum of time-, design- and control-complexity problems. To overcome these issues, a novel resiliency assessment method called APPRAISER is proposed that applies functional approximation for a non-conventional purpose and employs approximate computing errors for its interest. By adopting this concept in the resiliency assessment domain, APPRAISER provides thousands of times speed-up in the assessment process, while keeping high accuracy of the analysis. In this paper, APPRAISER is validated by comparing it with state-of-the-art approaches for fault injection by emulation in FPGA. By this, the feasibility of the idea is demonstrated, and a new perspective in resiliency evaluation for DNNs is opened.